Hi, I'd expect the throughput with 5 servers to be around 10K ops/sec for 100% writes.
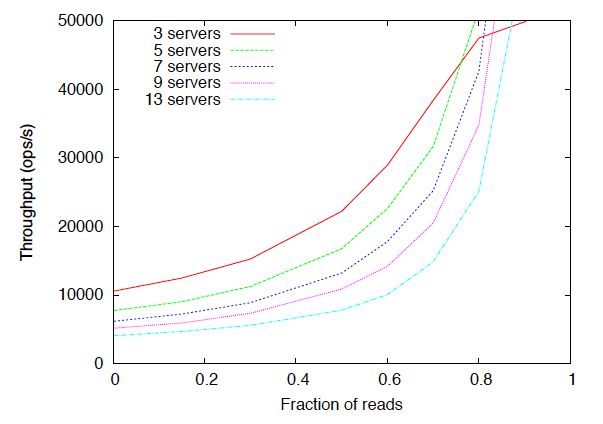
The graph Jordan sent shows smaller numbers than in the ZK paper (Figure 6: https://www.usenix.org/legacy/event/usenix10/tech/full_papers/Hunt.pdf) or what I saw with 7 servers here (Figure 6): https://www.usenix.org/system/files/conference/atc12/atc12-final74.pdf These were generated using our system test (see src/java/systest/README.txt on how to run). If you do run it, I suggest that you use the version in trunk, not 3.5.0 due to ZK-2008 that is fixed there. Alex On Thu, Aug 14, 2014 at 9:09 AM, Jordan Zimmerman < [email protected]> wrote: > Here is the standard graph of ZK tps: > > http://zookeeper.apache.org/doc/r3.1.2/images/zkperfRW.jpg > > If you are doing 100% writes with 5 ZK instances, 5K tps sounds right. You > can get more tps if you switch to 3 instances. The real question, though, > is why are you doing so many writes? > > -Jordan > > > From: Mudit Verma <[email protected]> > Reply: [email protected] <[email protected]>> > Date: August 14, 2014 at 10:50:53 AM > To: [email protected] <[email protected]>> > Subject: Write throughput is low !! > > Hi All, > > We, at our company, have a modest Zookeeper lab setup with 5 servers. > > During our lab tests, we found that somehow we can not go beyond 5K > Writes/Sec in total with roughly 100 clients (all the clients issues writes > to different znodes in a tight loop). Can someone point me to the official > numbers? Is this a good number for Zookeeper or it can scale much beyond? > > I understand that, parallelization by writing to different znodes will not > increase the throughput as there is only one log underneath. > > PS: Lab is hosted on a high speed network (1gigbit/sec) and network > latencies are far lower in contract to the the numbers we have. > > > Thanks > Mudit >
{kind=link}