YP AB Intermittent failures meeting =================================== https://windriver.zoom.us/j/3696693975
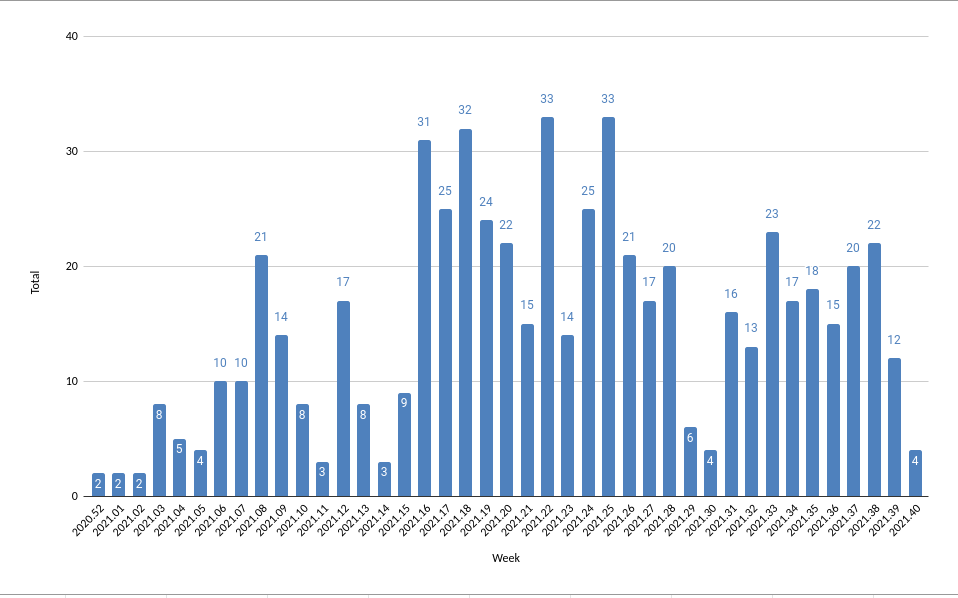
Attendees: Richard, Trevor, Randy, Saul Summary: ======== Ptest results continue to improve yet again but there's still room for even more improvement. Alex made a graph of the number of AB INT issues per week: https://bootlin.com/~alexandre/SWAT_stats.png We assume that week 15, 16 was when the RCU bug in he kernel started being a problem and week 29 was when it go fixed but more careful analysis is required. The make/ninja load average limit is in but it's not clear if it's effective yet and it breaks dunfell. Trevor has a build of dunfell that with some patches appears to work. If anyone wants to help, we could use more eyes on the logs, particularly the summary logs and understanding iostat # when the dd test times out. Plans for the week: =================== Richard: QA results for M4, etc. Alex: ? Sakib: hook more responsive load average in to latency test. (v3) Trevor: patch to set PARALLEL_MAKE : -l 50 -> dunfell, gatesgarth, hardknott (Aug 5, Oct 7) Confirm that dunfell works now, test other branches. Saul: SBOM Randy: # processes graph of full builds, patch ninja, graph it. Kiran: SBOM Nothing much new below here. Keeping the list since it's still to-do. ../Randy Meeting Notes: ============== 1. job server - ninja could be patched with make's more responsive algorithm next or is this good enough? Aug 26: Randy made some graphs that show that the -l NUM results in the number of compile jobs oscillates *wildly* between 0 and 200 on a 192 core builder compiling chromium. What I did was: $ bitbake -c cleansstate chromium-x11 $ bitbake -c configure chromium-x11 $ bitbake -c compile chromium-x11 and while that compile was running: $ while [ ! -f /tmp/compiling-chromium-is-done ]; do \ cat /proc/loadavg >> procs-load.log ; sleep 0.5 ; done Results so far: https://postimg.cc/gallery/3hjfYfG/f8f46c97 Next step is either: a. collect data as above for an image build and see if the sub-optimal ninja behaviour makes a difference and/or b. patch ninja with make's more responsive load avg algorithm: https://git.savannah.gnu.org/cgit/make.git/commit/?id=d8728efc8 - Richard suggested that we extract make's code for measuring the load average to a separate binary and run it in the periodic io latency test. Also can we translate it to python? - Trevor is working on this and had some problems so next week. (Aug 19 - Trevor is back from vaction so maybe next week.) - Trevor to see if the load average change really did reduce load on WR build systems. (Aug 19) 2. AB status Trevor is learning about buildbot and working on a scheduling bug (CentOS worker?) bitbake layer setup tool should allow multiple backends: eg: kas, a y-a-helper. ptest cases are improving, we may be close to done! Let's wait a week to see how things go. (July29, Aug 5, Aug 19, we're not done...) - lttng-tools ptest is failing. RP is working on it with upstream. The timeout (done on Aug 5) increase hasn't helped. 3. Sakib's improvements to the logging are merged. Sakib generated a summary of all high latency 'top' logs from ~July 23->July 29 by just running his summary script on the merged raw top logs. More analysis required.... Still relevant parts of Previous Meeting Notes: ======================= 4. bitbake server timeout ( no change july 29, Aug 19, Oct 7) "Timeout while waiting for a reply from the bitbake server (60s)" 5. io stalls (no update: July 29, Oct 7) Richard said that it would make sense to write an ftrace utility / script to monitor io latency and we could install it with sudo Ch^W mentioned ftrace on IRC. Sakib and Randy will work on that but not for a week or two or longer! (Aug 19). Randy collected iostat data on 3 build server: https://postimg.cc/gallery/8cN6LYB We agreed that having -ty-2 be ~ 100 utilization for many hours in a row is not acceptable and that a threshold of ~ 10 minutes at 100% utilization may be a reasonable limt. I need to figure out if I can get data on the fraction of IO done per IO clas since we do use ionice to do clean-up and other activities. ../Randy
{kind=link}
-=-=-=-=-=-=-=-=-=-=-=- Links: You receive all messages sent to this group. View/Reply Online (#54984): https://lists.yoctoproject.org/g/yocto/message/54984 Mute This Topic: https://lists.yoctoproject.org/mt/86145076/21656 Group Owner: [email protected] Unsubscribe: https://lists.yoctoproject.org/g/yocto/unsub [[email protected]] -=-=-=-=-=-=-=-=-=-=-=-