This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new b5e39bedab14 [SPARK-48027][SQL] InjectRuntimeFilter for multi-level
join should check child join type
b5e39bedab14 is described below
commit b5e39bedab14a7fd800597ee0114b07448c1b0f9
Author: Angerszhuuuu <angers....@gmail.com>
AuthorDate: Tue May 7 14:47:40 2024 +0800
[SPARK-48027][SQL] InjectRuntimeFilter for multi-level join should check
child join type
### What changes were proposed in this pull request?
In our prod we meet a case
```
with
refund_info as (
select
b_key,
1 as b_type
from default.table_b
),
next_month_time as (
select /*+ broadcast(b, c) */
c_key
,1 as c_time
FROM default.table_c
)
select
a.loan_id
,c.c_time
,b.type
from (
select
a_key
from default.table_a2
union
select
a_key
from default.table_a1
) a
left join refund_info b on a.loan_id = b.loan_id
left join next_month_time c on a.loan_id = c.loan_id
;
```
In this query, it inject table_b as table_c's runtime bloom filter, but
table_b join condition is LEFT OUTER, causing table_c missing data.
Caused by
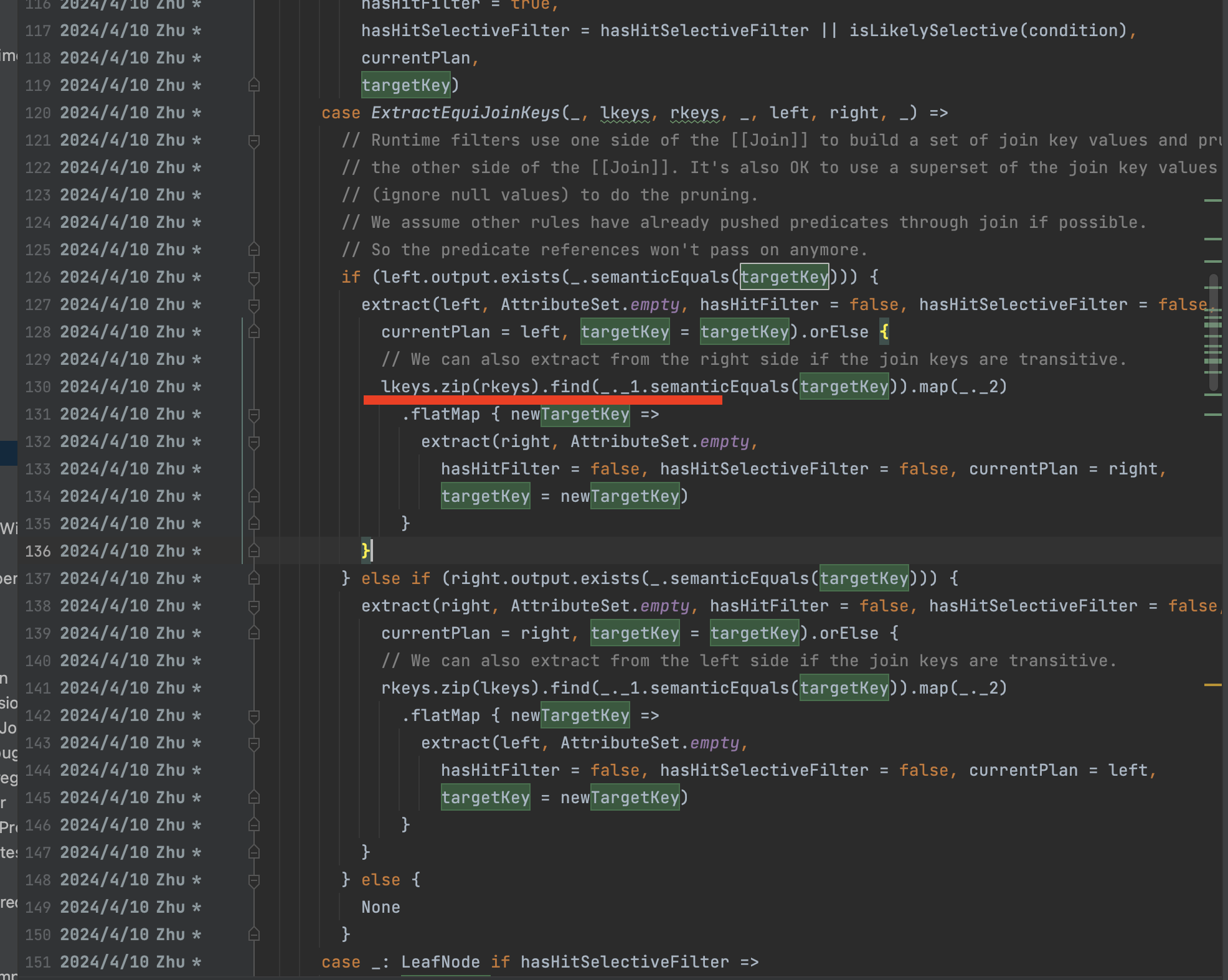
InjectRuntimeFilter.extractSelectiveFilterOverScan(), when handle join,
since left plan (a left outer join b's a) is a UNION then the extract result is
NONE, then zip left/right keys to extract from join's right, finnaly cause
this issue.
### Why are the changes needed?
Fix data correctness issue
### Does this PR introduce _any_ user-facing change?
Yea, fix data incorrect issue
### How was this patch tested?
For the existed PR, it fix the wrong case
Before: It extract a LEFT_ANTI_JOIN's right child to the outside bf3....its
not correct
```
Join Inner, (c3#45926 = c1#45914)
:- Join LeftAnti, (c1#45914 = c2#45920)
: :- Filter isnotnull(c1#45914)
: : +- Relation
default.bf1[a1#45912,b1#45913,c1#45914,d1#45915,e1#45916,f1#45917] parquet
: +- Project [c2#45920]
: +- Filter ((isnotnull(a2#45918) AND (a2#45918 = 5)) AND
isnotnull(c2#45920))
: +- Relation
default.bf2[a2#45918,b2#45919,c2#45920,d2#45921,e2#45922,f2#45923] parquet
+- Filter (isnotnull(c3#45926) AND might_contain(scalar-subquery#48719 [],
xxhash64(c3#45926, 42)))
: +- Aggregate [bloom_filter_agg(xxhash64(c2#45920, 42), 1000000,
8388608, 0, 0) AS bloomFilter#48718]
: +- Project [c2#45920]
: +- Filter ((isnotnull(a2#45918) AND (a2#45918 = 5)) AND
isnotnull(c2#45920))
: +- Relation
default.bf2[a2#45918,b2#45919,c2#45920,d2#45921,e2#45922,f2#45923] parquet
+- Relation
default.bf3[a3#45924,b3#45925,c3#45926,d3#45927,e3#45928,f3#45929] parquet
```
After:
```
Join Inner, (c3#45926 = c1#45914)
:- Join LeftAnti, (c1#45914 = c2#45920)
: :- Filter isnotnull(c1#45914)
: : +- Relation
default.bf1[a1#45912,b1#45913,c1#45914,d1#45915,e1#45916,f1#45917] parquet
: +- Project [c2#45920]
: +- Filter ((isnotnull(a2#45918) AND (a2#45918 = 5)) AND
isnotnull(c2#45920))
: +- Relation
default.bf2[a2#45918,b2#45919,c2#45920,d2#45921,e2#45922,f2#45923] parquet
+- Filter (isnotnull(c3#45926))
+- Relation
default.bf3[a3#45924,b3#45925,c3#45926,d3#45927,e3#45928,f3#45929] parquet
```
### Was this patch authored or co-authored using generative AI tooling?
NO
Closes #46263 from AngersZhuuuu/SPARK-48027.
Lead-authored-by: Angerszhuuuu <angers....@gmail.com>
Co-authored-by: Wenchen Fan <cloud0...@gmail.com>
Signed-off-by: Wenchen Fan <wenc...@databricks.com>
---
.../catalyst/optimizer/InjectRuntimeFilter.scala | 44 +++++++++++++++-------
.../spark/sql/InjectRuntimeFilterSuite.scala | 4 +-
2 files changed, 32 insertions(+), 16 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InjectRuntimeFilter.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InjectRuntimeFilter.scala
index 9c150f1f3308..3bb7c4d1ceca 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InjectRuntimeFilter.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InjectRuntimeFilter.scala
@@ -120,7 +120,7 @@ object InjectRuntimeFilter extends Rule[LogicalPlan] with
PredicateHelper with J
hasHitSelectiveFilter = hasHitSelectiveFilter ||
isLikelySelective(condition),
currentPlan,
targetKey)
- case ExtractEquiJoinKeys(_, lkeys, rkeys, _, _, left, right, _) =>
+ case ExtractEquiJoinKeys(joinType, lkeys, rkeys, _, _, left, right, _) =>
// Runtime filters use one side of the [[Join]] to build a set of join
key values and prune
// the other side of the [[Join]]. It's also OK to use a superset of
the join key values
// (ignore null values) to do the pruning.
@@ -129,24 +129,40 @@ object InjectRuntimeFilter extends Rule[LogicalPlan] with
PredicateHelper with J
if (left.output.exists(_.semanticEquals(targetKey))) {
extract(left, AttributeSet.empty, hasHitFilter = false,
hasHitSelectiveFilter = false,
currentPlan = left, targetKey = targetKey).orElse {
- // We can also extract from the right side if the join keys are
transitive.
- lkeys.zip(rkeys).find(_._1.semanticEquals(targetKey)).map(_._2)
- .flatMap { newTargetKey =>
- extract(right, AttributeSet.empty,
- hasHitFilter = false, hasHitSelectiveFilter = false,
currentPlan = right,
- targetKey = newTargetKey)
- }
+ // We can also extract from the right side if the join keys are
transitive, and
+ // the right side always produces a superset output of join left
keys.
+ // Let's look at an example
+ // left table: 1, 2, 3
+ // right table, 3, 4
+ // left outer join output: (1, null), (2, null), (3, 3)
+ // left key output: 1, 2, 3
+ // Any join side always produce a superset output of its
corresponding
+ // join keys, but for transitive join keys we need to check the
join type.
+ if (canPruneLeft(joinType)) {
+ lkeys.zip(rkeys).find(_._1.semanticEquals(targetKey)).map(_._2)
+ .flatMap { newTargetKey =>
+ extract(right, AttributeSet.empty,
+ hasHitFilter = false, hasHitSelectiveFilter = false,
currentPlan = right,
+ targetKey = newTargetKey)
+ }
+ } else {
+ None
+ }
}
} else if (right.output.exists(_.semanticEquals(targetKey))) {
extract(right, AttributeSet.empty, hasHitFilter = false,
hasHitSelectiveFilter = false,
currentPlan = right, targetKey = targetKey).orElse {
// We can also extract from the left side if the join keys are
transitive.
- rkeys.zip(lkeys).find(_._1.semanticEquals(targetKey)).map(_._2)
- .flatMap { newTargetKey =>
- extract(left, AttributeSet.empty,
- hasHitFilter = false, hasHitSelectiveFilter = false,
currentPlan = left,
- targetKey = newTargetKey)
- }
+ if (canPruneRight(joinType)) {
+ rkeys.zip(lkeys).find(_._1.semanticEquals(targetKey)).map(_._2)
+ .flatMap { newTargetKey =>
+ extract(left, AttributeSet.empty,
+ hasHitFilter = false, hasHitSelectiveFilter = false,
currentPlan = left,
+ targetKey = newTargetKey)
+ }
+ } else {
+ None
+ }
}
} else {
None
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/InjectRuntimeFilterSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/InjectRuntimeFilterSuite.scala
index fc1524be1317..027477a8291a 100644
---
a/sql/core/src/test/scala/org/apache/spark/sql/InjectRuntimeFilterSuite.scala
+++
b/sql/core/src/test/scala/org/apache/spark/sql/InjectRuntimeFilterSuite.scala
@@ -356,8 +356,8 @@ class InjectRuntimeFilterSuite extends QueryTest with
SQLTestUtils with SharedSp
"(bf1.c1 = bf2.c2 and bf2.a2 = 5)) as a join bf3 on bf3.c3 = a.c1", 2)
// left anti join unsupported.
// bf2 as creation side and inject runtime filter for bf3(by passing
key).
- assertRewroteWithBloomFilter("select * from (select * from bf1 left anti
join bf2 on " +
- "(bf1.c1 = bf2.c2 and bf2.a2 = 5)) as a join bf3 on bf3.c3 = a.c1")
+ assertDidNotRewriteWithBloomFilter("select * from (select * from bf1
left anti join bf2 " +
+ "on (bf1.c1 = bf2.c2 and bf2.a2 = 5)) as a join bf3 on bf3.c3 = a.c1")
// left anti join unsupported and hasn't selective filter.
assertRewroteWithBloomFilter("select * from (select * from bf1 left anti
join bf2 on " +
"(bf1.c1 = bf2.c2 and bf1.a1 = 5)) as a join bf3 on bf3.c3 = a.c1", 0)
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org