On Nov 30, 2007 9:46 AM, Mike Perkowitz <[EMAIL PROTECTED]> wrote: > > > Hello! We have a web site currently built on linux/apache/mysql/php. Most > pages do some mysql queries and then stuff the results into php/html > templates. We've been hitting the limits of what our database can handle, > and what we can do in realtime for the site. Our plan is to move our data > over to Hbase, precomputing as much as we can (some queries we currently > do > with joins in mysql, for example). Our pages would then be pulling rows > from > Hbase to stuff into templates. > > > > We're still working on getting Hbase working with the amount of data we > want > to be able to handle, so haven't yet been able to test it for performance. > Is anyone else using Hbase in this way, and what has been your experience > with realtime performance? I haven't really seen examples of people using > Hbase this way - another approach would be for us to use > Hadoop/Hbase/mapreduce for computation then put results back into mysql or > whatever for realtime access. Any experience or suggestions would be > appreciated!
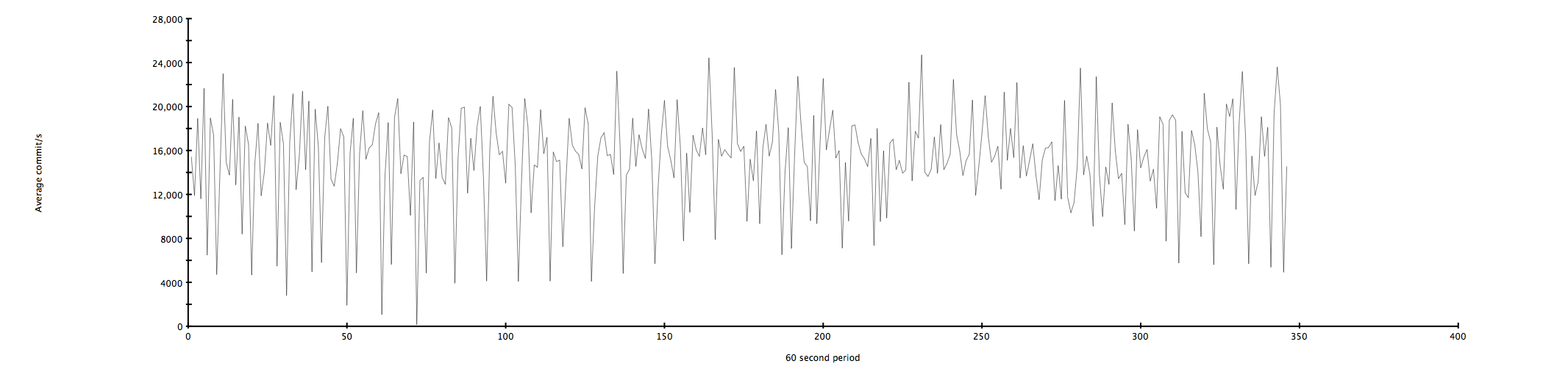
In my setup of loading 313ish million rows into hbase with about 38 bytes of column data (not including timestamps) and a variable size row key takes around 6 hours to complete using a map-reduce job to do the import. I was able to sustain an average write-rate of 15220.9 commits/s with a peak commit rate of 44300/s. You can take a look at the link below which is an attempt to graph the commit rate of my job. I had quite a bit of data points, so i took the avg commits/s over a 60 period and plotted that. http://yogurt.org/hadoop_import.jpg Once the data was loaded, reading the same row key 1000 times took 454 seconds and reading 1000 sequential keys using HTable.get() took 542 seconds. There's much to be improved on the reading side. Hope that answers some of your questions.
{kind=link}