[GitHub] [flink] flinkbot commented on pull request #21743: [FLINK-15325][coordination] Ignores the input locations of a ConsumePartitionGroup if the corresponding ConsumerVertexGroup is too large
flinkbot commented on PR #21743: URL: https://github.com/apache/flink/pull/21743#issuecomment-1398746472 ## CI report: * 9118095bdfdf184466f83661e8b39661c7075181 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] zhuzhurk opened a new pull request, #21743: [FLINK-15325][coordination] Ignores the input locations of a ConsumePartitionGroup if the corresponding ConsumerVertexGroup is too large
zhuzhurk opened a new pull request, #21743: URL: https://github.com/apache/flink/pull/21743 ## What is the purpose of the change This change improves the `DefaultPreferredLocationsRetriever` so that it ignores the input locations of a ConsumePartitionGroup if the corresponding ConsumerVertexGroup is too large. This helps to avoid tasks to be unevenly distributed on nodes when running batch jobs or running jobs in session/standalone mode, because the consumers in this case will tend to be placed on the same node of the input vertex. ## Brief change log *(for example:)* - Changed `EdgeManagerBuildUtil` to set the ConsumedPartitionGroup/ConsumerVertexGroup to its corresponding ConsumerVertexGroup/ConsumedPartitionGroup - Changed `DefaultPreferredLocationsRetriever` to ignore the input locations of a ConsumePartitionGroup if the corresponding ConsumerVertexGroup is too large(compared to the ConsumePartitionGroup) ## Verifying this change - *Added unit tests in EdgeManagerBuildUtilTest and DefaultPreferredLocationsRetrieverTest* - *The change is also covered by existing tests of preferred location retriever* ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / **no**) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / **no**) - The serializers: (yes / **no** / don't know) - The runtime per-record code paths (performance sensitive): (yes / **no** / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (**yes** / no / don't know) - The S3 file system connector: (yes / **no** / don't know) ## Documentation - Does this pull request introduce a new feature? (yes / **no**) - If yes, how is the feature documented? (not applicable / docs / JavaDocs / not documented) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] MartijnVisser commented on pull request #18823: [FLINK-20625][pubsub,e2e] Add PubSubSource connector using FLIP-27
MartijnVisser commented on PR #18823: URL: https://github.com/apache/flink/pull/18823#issuecomment-1398705483 @RyanSkraba It would indeed be nice if we can move this now to the externalized repo. @dchristle it would be great if you can help validate it so we can move it forward. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] XComp commented on a diff in pull request #21742: [FLINK-30765][runtime] Aligns the LeaderElectionService.stop() contract
XComp commented on code in PR #21742:
URL: https://github.com/apache/flink/pull/21742#discussion_r1082832944
##
flink-runtime/src/main/java/org/apache/flink/runtime/leaderelection/DefaultLeaderElectionService.java:
##
@@ -100,6 +100,7 @@ public final void stop() throws Exception {
if (!running) {
return;
}
+leaderContender.revokeLeadership();
Review Comment:
Ok, digging into a the PR a bit more shows that the old
[ZooKeeperLeaderElectionService](https://github.com/apache/flink/pull/13644/files?show-deleted-files=true=true%5B%5D=#diff-de2fa2be46667dad62b57be6fefa6135043e19888afd453b634792241785c8e0L147)
didn't call the revoke. So, I guess, that's just keeping the implementation
like that.
But just in general from a theoretical standpoint: We do want to
consistently call revoke during shutdown to trigger the clean up through
revokeLeadership to stick to the right protocol. That, as a consequence, would
make cleanup in the `LeaderContender.stop()` implementation obsolete. WDYT?
:thinking:
From what I've seen within the code, any implementation does essentially
call redundant code cleaning up artifacts in `stop()` and `revokeLeadership()`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] XComp commented on a diff in pull request #21742: [FLINK-30765][runtime] Aligns the LeaderElectionService.stop() contract
XComp commented on code in PR #21742:
URL: https://github.com/apache/flink/pull/21742#discussion_r1082832944
##
flink-runtime/src/main/java/org/apache/flink/runtime/leaderelection/DefaultLeaderElectionService.java:
##
@@ -100,6 +100,7 @@ public final void stop() throws Exception {
if (!running) {
return;
}
+leaderContender.revokeLeadership();
Review Comment:
Ok, digging into a the PR a bit more shows that the old
[ZooKeeperLeaderElectionService](https://github.com/apache/flink/pull/13644/files?show-deleted-files=true=true%5B%5D=#diff-de2fa2be46667dad62b57be6fefa6135043e19888afd453b634792241785c8e0L147)
didn't call the revoke. So, I guess, that's just keeping the implementation
like that.
But just in general from a theoretical standpoint: We do want to
consistently call revoke during shutdown to trigger the clean up through
revokeLeadership to stick to the right protocol. That, as a consequence, would
make cleanup in the `LeaderContender.stop()` implementation obsolete. WDYT?
:thinking:
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] zentol merged pull request #21741: [FLINK-30764][docs] Include generic delegation token params in the main config page
zentol merged PR #21741: URL: https://github.com/apache/flink/pull/21741 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] XComp commented on a diff in pull request #21742: [FLINK-30765][runtime] Aligns the LeaderElectionService.stop() contract
XComp commented on code in PR #21742:
URL: https://github.com/apache/flink/pull/21742#discussion_r1082817072
##
flink-runtime/src/main/java/org/apache/flink/runtime/leaderelection/DefaultLeaderElectionService.java:
##
@@ -100,6 +100,7 @@ public final void stop() throws Exception {
if (!running) {
return;
}
+leaderContender.revokeLeadership();
Review Comment:
@wangyang0918 Was there a rationale to omit the revoking of the leadership
when stopping the service? We even added a dedicated test for that in
`DefaultLeaderElectionServiceTest`. :thinking:
To help gettin back the memory: The commit belongs to PR #13644
(FLINK-19542).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] XComp commented on pull request #21737: [FLINK-30760][runtime] Fixes wrongly used @GuardedBy annotation
XComp commented on PR #21737: URL: https://github.com/apache/flink/pull/21737#issuecomment-1398645766 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] 1996fanrui commented on a diff in pull request #20151: [FLINK-26803][checkpoint] Merging channel state files
1996fanrui commented on code in PR #20151:
URL: https://github.com/apache/flink/pull/20151#discussion_r1082757960
##
flink-streaming-java/src/main/java/org/apache/flink/streaming/api/environment/ExecutionCheckpointingOptions.java:
##
@@ -280,4 +280,13 @@ public class ExecutionCheckpointingOptions {
.booleanType()
.defaultValue(false)
.withDescription("Flag to enable approximate local
recovery.");
+
+public static final ConfigOption
CHANNEL_STATE_NUMBER_OF_SUBTASKS_SHARE_FILE =
+
ConfigOptions.key("execution.checkpointing.channel-state.number-of-subtasks-share-file")
+.intType()
+.defaultValue(5)
+.withDescription(
+"Defines the maximum number of subtasks that share
the same channel state file. "
++ "It can reduce the number of small files
when enable unaligned checkpoint. "
++ "Each subtask will create a new channel
state file when this is configured to 1.");
Review Comment:
Sounds good to me.
Thanks for the suggestion, I will update it asap.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] dawidwys commented on a diff in pull request #20151: [FLINK-26803][checkpoint] Merging channel state files
dawidwys commented on code in PR #20151:
URL: https://github.com/apache/flink/pull/20151#discussion_r1082743417
##
flink-streaming-java/src/main/java/org/apache/flink/streaming/api/environment/ExecutionCheckpointingOptions.java:
##
@@ -280,4 +280,13 @@ public class ExecutionCheckpointingOptions {
.booleanType()
.defaultValue(false)
.withDescription("Flag to enable approximate local
recovery.");
+
+public static final ConfigOption
CHANNEL_STATE_NUMBER_OF_SUBTASKS_SHARE_FILE =
+
ConfigOptions.key("execution.checkpointing.channel-state.number-of-subtasks-share-file")
+.intType()
+.defaultValue(5)
+.withDescription(
+"Defines the maximum number of subtasks that share
the same channel state file. "
++ "It can reduce the number of small files
when enable unaligned checkpoint. "
++ "Each subtask will create a new channel
state file when this is configured to 1.");
Review Comment:
Makes sense to me
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] gaborgsomogyi commented on pull request #21741: [FLINK-30764][docs] Include generic delegation token params in the main config page
gaborgsomogyi commented on PR #21741: URL: https://github.com/apache/flink/pull/21741#issuecomment-1398600117 cc @mbalassi @zentol -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #21742: [FLINK-30765][runtime] Aligns the LeaderElectionService.stop() contract
flinkbot commented on PR #21742: URL: https://github.com/apache/flink/pull/21742#issuecomment-1398477646 ## CI report: * 9afce3d1052ab18c689e446302a91201c84fadef UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] XComp opened a new pull request, #21742: [FLINK-30765][runtime] Aligns the LeaderElectionService.stop() contract
XComp opened a new pull request, #21742: URL: https://github.com/apache/flink/pull/21742 ## What is the purpose of the change This PR is about hardening the `LeaderElectionService.stop()` contract. The current implementations of LeaderElectionService do not implement the stop() call consistently. Some (e.g. [StandaloneLeaderElectionService](https://github.com/apache/flink/blob/c6997c97c575d334679915c328792b8a3067cfb5/flink-runtime/src/main/java/org/apache/flink/runtime/leaderelection/StandaloneLeaderElectionService.java#L53) call revoke on the LeaderContender) whereas others don't (e.g. [DefaultLeaderElectionService](https://github.com/apache/flink/blob/6e1caa390882996bf2d602951b54e4bb2d9c90dc/flink-runtime/src/main/java/org/apache/flink/runtime/leaderelection/DefaultLeaderElectionService.java#L96)). The [MultipleComponentLeaderElectionService](https://github.com/apache/flink/blob/0290715a57b8d243586ab747b0cd2416c8081012/flink-runtime/src/main/java/org/apache/flink/runtime/leaderelection/DefaultMultipleComponentLeaderElectionService.java#L166) does call revoke on the LeaderContender instances, though. We should align this behavior and specify it in the LeaderElectionService contract before going ahead with refactoring the interfaces ([FLIP-285](https://cwiki.apache.org/confluence/display/FLINK/FLIP-285%3A+Refactoring+LeaderElection+to+make+Flink+support+multi-component+leader+election+out-of-the-box)). ## Brief change log * Updated the JavaDoc in `LeaderElectionService.stop()` to specify the contract * Added `LeaderContender.revokeLeadership()` call to implementations that missed that call before ## Verifying this change The `LeaderContender.revokeLeadership()` call was also added to `TestingLeaderElectionService` to make each test rely on this contract. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? JavaDocs -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] pnowojski commented on a diff in pull request #20151: [FLINK-26803][checkpoint] Merging channel state files
pnowojski commented on code in PR #20151:
URL: https://github.com/apache/flink/pull/20151#discussion_r1082600527
##
flink-streaming-java/src/main/java/org/apache/flink/streaming/api/environment/ExecutionCheckpointingOptions.java:
##
@@ -280,4 +280,13 @@ public class ExecutionCheckpointingOptions {
.booleanType()
.defaultValue(false)
.withDescription("Flag to enable approximate local
recovery.");
+
+public static final ConfigOption
CHANNEL_STATE_NUMBER_OF_SUBTASKS_SHARE_FILE =
+
ConfigOptions.key("execution.checkpointing.channel-state.number-of-subtasks-share-file")
+.intType()
+.defaultValue(5)
+.withDescription(
+"Defines the maximum number of subtasks that share
the same channel state file. "
++ "It can reduce the number of small files
when enable unaligned checkpoint. "
++ "Each subtask will create a new channel
state file when this is configured to 1.");
Review Comment:
It's only for unaligned checkpoints. There is a possibility we will have
more options, but not very likely. So maybe
`execution.checkpointing.unaligned.max-subtasks-per-channel-state-file`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #21741: [FLINK-30764][docs] Include generic delegation token params in the main config page
flinkbot commented on PR #21741: URL: https://github.com/apache/flink/pull/21741#issuecomment-1398454630 ## CI report: * 79d653c444716cf88e0b22b08333c2feb50ac872 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] gaborgsomogyi commented on pull request #21732: [FLINK-30754][tests] Fix ExceptionThrowingDelegationTokenProvider/Receiver multi-threaded test issues
gaborgsomogyi commented on PR #21732: URL: https://github.com/apache/flink/pull/21732#issuecomment-1398453852 Resolved the conflicts -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] gaborgsomogyi commented on pull request #21741: [FLINK-30764][docs] Include generic delegation token params in the main config page
gaborgsomogyi commented on PR #21741: URL: https://github.com/apache/flink/pull/21741#issuecomment-1398450836 Addressing the [following](https://github.com/apache/flink/pull/21723#issuecomment-1387339515) comment in this PR. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] healchow commented on a diff in pull request #21722: [FLINK-30747][docs]Translate "Window Deduplication" page of "Querys"
healchow commented on code in PR #21722:
URL: https://github.com/apache/flink/pull/21722#discussion_r1082589298
##
docs/content.zh/docs/dev/table/sql/queries/window-deduplication.md:
##
@@ -101,15 +102,16 @@ Flink SQL> SELECT *
+--+---+--+-+--+--++
```
-*Note: in order to better understand the behavior of windowing, we simplify
the displaying of timestamp values to not show the trailing zeros, e.g.
`2020-04-15 08:05` should be displayed as `2020-04-15 08:05:00.000` in Flink
SQL Client if the type is `TIMESTAMP(3)`.*
+*注意: 为了更好地理解窗口行为,这里把timestamp值后面的0去掉了.例如:在Flink SQL
Client中,如果类型是`TIMESTAMP(3)`,`2020-04-15 08:05`应该显示成`2020-04-15 08:05:00.000`.*
+
+## 限制
-## Limitation
+## 在窗口表值函数后直接进行窗口去重的限制
-### Limitation on Window Deduplication which follows after Windowing TVFs
directly
-Currently, if Window Deduplication follows after [Windowing TVF]({{< ref
"docs/dev/table/sql/queries/window-tvf" >}}), the [Windowing TVF]({{< ref
"docs/dev/table/sql/queries/window-tvf" >}}) has to be with Tumble Windows, Hop
Windows or Cumulate Windows instead of Session windows. Session windows will be
supported in the near future.
+目前,Flink只支持在滚动,滑动和累计\[窗口表值函数]\({{< ref "docs/dev/table/sql/queries/window-tvf"
>}})后进行窗口去重.会话窗口不久之后就会支持.
-### Limitation on time attribute of order key
-Currently, Window Deduplication requires order key must be [event time
attribute]({{< ref "docs/dev/table/concepts/time_attributes" >}}#event-time)
instead of [processing time attribute]({{< ref
"docs/dev/table/concepts/time_attributes" >}}#processing-time). Ordering by
processing-time would be supported in the near future.
+### 根据时间属性排序的限制
+目前,Flink只支持根据\[事件时间属性]\({{< ref "docs/dev/table/concepts/time\_attributes"
>}}#event-time)排序.根据处理时间排序不久之后就会支持.
Review Comment:
使用 \ 转义符会导致链接无法跳转。
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] gaborgsomogyi commented on pull request #21741: [FLINK-30764][docs] Include generic delegation token params in the main config page
gaborgsomogyi commented on PR #21741: URL: https://github.com/apache/flink/pull/21741#issuecomment-1398447229 This is how it looks like: https://user-images.githubusercontent.com/18561820/213716824-489f5eca-ae23-4d20-b496-fdd09dc9457d.png;> -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] gaborgsomogyi opened a new pull request, #21741: [FLINK-30764][docs] Include generic delegation token params in the main config page
gaborgsomogyi opened a new pull request, #21741: URL: https://github.com/apache/flink/pull/21741 ## What is the purpose of the change Until now the generic delegation token params are not shown on the main config page. In this PR I've added them. ## Brief change log Included generic delegation token params in the main config page. ## Verifying this change Existing tests + manually checked the generated page. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? docs -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] fsk119 commented on pull request #21717: [FLINK-29945][sql-client] Supports to submit SQL to a embedded SQL Ga…
fsk119 commented on PR #21717: URL: https://github.com/apache/flink/pull/21717#issuecomment-1398397981 > P.S. Wrong cmd will get CLI blocked forever. Thanks for reporting the case. With the commit 0e04c7, the Executor will try to close the Operation in the background when users hit ctrl + c. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] XComp commented on a diff in pull request #21740: [FLINK-30759][runtime] Merges DispatcherRunnerLeaderElectionLifecycleManager into DefaultDispatcherRunner
XComp commented on code in PR #21740:
URL: https://github.com/apache/flink/pull/21740#discussion_r1082532829
##
flink-runtime/src/main/java/org/apache/flink/runtime/dispatcher/runner/DefaultDispatcherRunner.java:
##
@@ -89,11 +93,29 @@ public CompletableFuture closeAsync() {
}
}
+Exception exception = null;
+try {
+leaderElectionService.stop();
+} catch (Exception e) {
+exception = e;
+}
+final Exception leaderElectionServiceShutdownException = exception;
+
stopDispatcherLeaderProcess();
FutureUtils.forward(previousDispatcherLeaderProcessTerminationFuture,
terminationFuture);
-return terminationFuture;
+return terminationFuture.whenComplete(
+(ignoredResult, terminationThrowable) -> {
+if (terminationThrowable != null) {
+throw new CompletionException(
+ExceptionUtils.firstOrSuppressed(
+terminationThrowable,
+
leaderElectionServiceShutdownException));
Review Comment:
Fair point. I don't know, why I didn't come up with a simple copy I
updated the code. This also fixed the compilation error where some imports were
missing.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] XComp commented on a diff in pull request #21740: [FLINK-30759][runtime] Merges DispatcherRunnerLeaderElectionLifecycleManager into DefaultDispatcherRunner
XComp commented on code in PR #21740:
URL: https://github.com/apache/flink/pull/21740#discussion_r1082532829
##
flink-runtime/src/main/java/org/apache/flink/runtime/dispatcher/runner/DefaultDispatcherRunner.java:
##
@@ -89,11 +93,29 @@ public CompletableFuture closeAsync() {
}
}
+Exception exception = null;
+try {
+leaderElectionService.stop();
+} catch (Exception e) {
+exception = e;
+}
+final Exception leaderElectionServiceShutdownException = exception;
+
stopDispatcherLeaderProcess();
FutureUtils.forward(previousDispatcherLeaderProcessTerminationFuture,
terminationFuture);
-return terminationFuture;
+return terminationFuture.whenComplete(
+(ignoredResult, terminationThrowable) -> {
+if (terminationThrowable != null) {
+throw new CompletionException(
+ExceptionUtils.firstOrSuppressed(
+terminationThrowable,
+
leaderElectionServiceShutdownException));
Review Comment:
Fair point. I don't know, why I didn't come up with a simple copy I
updated this and fixed the compilation failure as part of the force push.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] dawidwys commented on a diff in pull request #20151: [FLINK-26803][checkpoint] Merging channel state files
dawidwys commented on code in PR #20151:
URL: https://github.com/apache/flink/pull/20151#discussion_r1082525394
##
flink-streaming-java/src/main/java/org/apache/flink/streaming/api/environment/ExecutionCheckpointingOptions.java:
##
@@ -280,4 +280,13 @@ public class ExecutionCheckpointingOptions {
.booleanType()
.defaultValue(false)
.withDescription("Flag to enable approximate local
recovery.");
+
+public static final ConfigOption
CHANNEL_STATE_NUMBER_OF_SUBTASKS_SHARE_FILE =
+
ConfigOptions.key("execution.checkpointing.channel-state.number-of-subtasks-share-file")
+.intType()
+.defaultValue(5)
+.withDescription(
+"Defines the maximum number of subtasks that share
the same channel state file. "
++ "It can reduce the number of small files
when enable unaligned checkpoint. "
++ "Each subtask will create a new channel
state file when this is configured to 1.");
Review Comment:
1. Does it apply to unaligned checkpoints only? If so, could we put it under
`unaligned` subgroup? `execution.checkpointing.unaligned.(...)`
2. Do we plan to have more options under `channel-state`? If not, I would
not introduce this subgroup.
3. I like @pnowojski idea more, but I'd add `max` prefix:
`max-subtasks-per-file`
Depending on 2. I'd go with either `channel-state.max-subtasks-per-file` or
` max-subtasks-per-channel-state-file`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] zentol commented on a diff in pull request #21740: [FLINK-30759][runtime] Merges DispatcherRunnerLeaderElectionLifecycleManager into DefaultDispatcherRunner
zentol commented on code in PR #21740:
URL: https://github.com/apache/flink/pull/21740#discussion_r1082519363
##
flink-runtime/src/main/java/org/apache/flink/runtime/dispatcher/runner/DefaultDispatcherRunner.java:
##
@@ -89,11 +93,29 @@ public CompletableFuture closeAsync() {
}
}
+Exception exception = null;
+try {
+leaderElectionService.stop();
+} catch (Exception e) {
+exception = e;
+}
+final Exception leaderElectionServiceShutdownException = exception;
+
stopDispatcherLeaderProcess();
FutureUtils.forward(previousDispatcherLeaderProcessTerminationFuture,
terminationFuture);
-return terminationFuture;
+return terminationFuture.whenComplete(
+(ignoredResult, terminationThrowable) -> {
+if (terminationThrowable != null) {
+throw new CompletionException(
+ExceptionUtils.firstOrSuppressed(
+terminationThrowable,
+
leaderElectionServiceShutdownException));
Review Comment:
I kinda preferred how this was modeled as a completable future in the
lifecycle manager.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] XComp commented on a diff in pull request #21737: [FLINK-30760][runtime] Fixes wrongly used @GuardedBy annotation
XComp commented on code in PR #21737:
URL: https://github.com/apache/flink/pull/21737#discussion_r1082508795
##
flink-runtime/src/main/java/org/apache/flink/runtime/leaderelection/DefaultLeaderElectionService.java:
##
@@ -48,9 +48,11 @@
private final LeaderElectionDriverFactory leaderElectionDriverFactory;
/** The leader contender which applies for leadership. */
+@GuardedBy("lock")
private volatile LeaderContender leaderContender;
Review Comment:
That's also my thought. The FLIP-285 changes make these things go away,
anyway. I'm gonna leave the comment for each of these fields to clarify when
they are non-null.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] XComp commented on a diff in pull request #21737: [FLINK-30760][runtime] Fixes wrongly used @GuardedBy annotation
XComp commented on code in PR #21737:
URL: https://github.com/apache/flink/pull/21737#discussion_r1082508795
##
flink-runtime/src/main/java/org/apache/flink/runtime/leaderelection/DefaultLeaderElectionService.java:
##
@@ -48,9 +48,11 @@
private final LeaderElectionDriverFactory leaderElectionDriverFactory;
/** The leader contender which applies for leadership. */
+@GuardedBy("lock")
private volatile LeaderContender leaderContender;
Review Comment:
That's also my thought. The FLIP-285 changes make these things go away,
anyway.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] hehuiyuan commented on pull request #21731: [FLINK-30679][hive]Fix IndexOutOfBoundsException for Hive lookup join when column pushdown to Hive lookup table source
hehuiyuan commented on PR #21731: URL: https://github.com/apache/flink/pull/21731#issuecomment-1398347485 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #21740: [FLINK-30759][runtime] Merges DispatcherRunnerLeaderElectionLifecycleManager into DefaultDispatcherRunner
flinkbot commented on PR #21740: URL: https://github.com/apache/flink/pull/21740#issuecomment-1398335456 ## CI report: * 46ab3d550b0d2be1b260f7c200ca6d168c7625ae UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] XComp opened a new pull request, #21740: [FLINK-30759][runtime] Merges DispatcherRunnerLeaderElectionLifecycleManager into DefaultDispatcherRunner
XComp opened a new pull request, #21740: URL: https://github.com/apache/flink/pull/21740 ## What is the purpose of the change The entire purpose of this wrapper `DispatcherRunnerLeaderElectionLifecycleManager` is to have the start/stop of the `LeaderElectionService` out of the `DefaultDispatcherRunner`. FLINK-26522/FLIP-285 will move this logic into the `HighAvailabilityServices`. Merging both classes makes the move easier because it aligns it with the other `LeaderContender` implementations. I couldn't find any reason why we need this class. There was a [brief discussion in PR #9832](https://github.com/apache/flink/pull/9832#discussion_r334866031) for FLINK-11843 which introduced this change. But even there, we already discussed having a `start()` method, instead. ## Brief change log Moved code from `DispatcherRunnerLeaderElectionLifecycleManager` back into `DefaultDispatcherRunner`. ## Verifying this change * `DefaultDispatcherRunnerTest.testLeaderElectionStarted` was added to check the lifecycle explicitly. This test is good to check that the `LeaderElectionService` is closed as part of the `DefaultDispatcherRunner.close()` call. * Various tests within `DefaultDispatcherRunnerTest` would fail without the start method being called. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? not applicable -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] zentol commented on a diff in pull request #21737: [FLINK-30760][runtime] Fixes wrongly used @GuardedBy annotation
zentol commented on code in PR #21737:
URL: https://github.com/apache/flink/pull/21737#discussion_r1082457711
##
flink-runtime/src/main/java/org/apache/flink/runtime/leaderelection/DefaultLeaderElectionService.java:
##
@@ -48,9 +48,11 @@
private final LeaderElectionDriverFactory leaderElectionDriverFactory;
/** The leader contender which applies for leadership. */
+@GuardedBy("lock")
private volatile LeaderContender leaderContender;
Review Comment:
urgh. I'd rather roll these 2 back :see_no_evil:
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] XComp commented on a diff in pull request #21738: [FLINK-30761][coordination,test] Replaces JVM assert with Preconditions in leader election code
XComp commented on code in PR #21738:
URL: https://github.com/apache/flink/pull/21738#discussion_r1082412814
##
flink-runtime/src/test/java/org/apache/flink/runtime/leaderelection/TestingLeaderElectionService.java:
##
@@ -48,7 +49,7 @@ public synchronized CompletableFuture
getConfirmationFutur
@Override
public synchronized void start(LeaderContender contender) {
-assert (!getStartFuture().isDone());
+Preconditions.checkState(getStartFuture().isDone());
Review Comment:
args - good catch. :+1: fixed
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-web] mbalassi closed pull request #602: Blog post on the Delegation Token Framework
mbalassi closed pull request #602: Blog post on the Delegation Token Framework URL: https://github.com/apache/flink-web/pull/602 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] XComp commented on a diff in pull request #21737: [FLINK-30760][runtime] Fixes wrongly used @GuardedBy annotation
XComp commented on code in PR #21737:
URL: https://github.com/apache/flink/pull/21737#discussion_r1082408148
##
flink-runtime/src/main/java/org/apache/flink/runtime/leaderelection/DefaultLeaderElectionService.java:
##
@@ -48,9 +48,11 @@
private final LeaderElectionDriverFactory leaderElectionDriverFactory;
/** The leader contender which applies for leadership. */
+@GuardedBy("lock")
private volatile LeaderContender leaderContender;
Review Comment:
I know, I just hesitated to add this annotation because it would generate
warnings in several locations within the class. But I added `@Nullable` now for
the other two fields as well to make it consistent. PTAL - I'm curious whether
you consider this of too much of a change.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] XComp commented on a diff in pull request #21737: [FLINK-30760][runtime] Fixes wrongly used @GuardedBy annotation
XComp commented on code in PR #21737:
URL: https://github.com/apache/flink/pull/21737#discussion_r1082408148
##
flink-runtime/src/main/java/org/apache/flink/runtime/leaderelection/DefaultLeaderElectionService.java:
##
@@ -48,9 +48,11 @@
private final LeaderElectionDriverFactory leaderElectionDriverFactory;
/** The leader contender which applies for leadership. */
+@GuardedBy("lock")
private volatile LeaderContender leaderContender;
Review Comment:
I know, I just hesitated to add this annotation because it would generate
warnings in several locations within the class. But I added `@Nullable` now for
the other two fields as well to make it consistent. PTAL
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] XComp commented on a diff in pull request #21737: [FLINK-30760][runtime] Fixes wrongly used @GuardedBy annotation
XComp commented on code in PR #21737:
URL: https://github.com/apache/flink/pull/21737#discussion_r1082408148
##
flink-runtime/src/main/java/org/apache/flink/runtime/leaderelection/DefaultLeaderElectionService.java:
##
@@ -48,9 +48,11 @@
private final LeaderElectionDriverFactory leaderElectionDriverFactory;
/** The leader contender which applies for leadership. */
+@GuardedBy("lock")
private volatile LeaderContender leaderContender;
Review Comment:
I know, I just hesitated to add this annotation because it would generate
warnings in several locations within the class. But I added `@Nullable` now for
the other two fields as well to make it consistent.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] pnowojski commented on a diff in pull request #20151: [FLINK-26803][checkpoint] Merging channel state files
pnowojski commented on code in PR #20151:
URL: https://github.com/apache/flink/pull/20151#discussion_r1082365656
##
flink-streaming-java/src/main/java/org/apache/flink/streaming/api/environment/ExecutionCheckpointingOptions.java:
##
@@ -280,4 +280,13 @@ public class ExecutionCheckpointingOptions {
.booleanType()
.defaultValue(false)
.withDescription("Flag to enable approximate local
recovery.");
+
+public static final ConfigOption
CHANNEL_STATE_NUMBER_OF_SUBTASKS_SHARE_FILE =
+
ConfigOptions.key("execution.checkpointing.channel-state.number-of-subtasks-share-file")
+.intType()
+.defaultValue(5)
+.withDescription(
+"Defines the maximum number of subtasks that share
the same channel state file. "
++ "It can reduce the number of small files
when enable unaligned checkpoint. "
++ "Each subtask will create a new channel
state file when this is configured to 1.");
Review Comment:
> number-of-subtasks-share-file
This sounds a bit strange in english. Maybe let's rename it to:
> execution.checkpointing.channel-state.subtasks-per-file
? and renaming the config option and getters as well? @dawidwys maybe you
have some better idea?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] mbalassi merged pull request #21694: [FLINK-30704][filesystems][s3] Add S3 delegation token support
mbalassi merged PR #21694: URL: https://github.com/apache/flink/pull/21694 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #21739: [FLINK-30673][docs][table] Add documentation for "EXPLAIN PLAN_ADVICE" statement
flinkbot commented on PR #21739: URL: https://github.com/apache/flink/pull/21739#issuecomment-1398198832 ## CI report: * e19d7dc89412bb6cd9bcf781a8938e9023e23048 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] LadyForest opened a new pull request, #21739: [FLINK-30673][docs][table] Add documentation for "EXPLAIN PLAN_ADVICE" statement
LadyForest opened a new pull request, #21739: URL: https://github.com/apache/flink/pull/21739 ## What is the purpose of the change This pull request adds documentation for `EXPLAIN PLAN_ADVICE` statement. ## Brief change log Add doc. ## Verifying this change This change is already covered by existing tests. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): No - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: No - The serializers: No - The runtime per-record code paths (performance sensitive): No - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: No - The S3 file system connector: No ## Documentation - Does this pull request introduces a new feature? Yes - If yes, how is the feature documented? docs -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] zentol commented on a diff in pull request #21738: [FLINK-30761][coordination,test] Replaces JVM assert with Preconditions in leader election code
zentol commented on code in PR #21738:
URL: https://github.com/apache/flink/pull/21738#discussion_r1082324266
##
flink-runtime/src/test/java/org/apache/flink/runtime/leaderelection/TestingLeaderElectionService.java:
##
@@ -48,7 +49,7 @@ public synchronized CompletableFuture
getConfirmationFutur
@Override
public synchronized void start(LeaderContender contender) {
-assert (!getStartFuture().isDone());
+Preconditions.checkState(getStartFuture().isDone());
Review Comment:
```suggestion
Preconditions.checkState(!getStartFuture().isDone());
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] zentol commented on a diff in pull request #21737: [FLINK-30760][runtime] Fixes wrongly used @GuardedBy annotation
zentol commented on code in PR #21737:
URL: https://github.com/apache/flink/pull/21737#discussion_r1082321263
##
flink-runtime/src/main/java/org/apache/flink/runtime/leaderelection/DefaultLeaderElectionService.java:
##
@@ -48,9 +48,11 @@
private final LeaderElectionDriverFactory leaderElectionDriverFactory;
/** The leader contender which applies for leadership. */
+@GuardedBy("lock")
private volatile LeaderContender leaderContender;
Review Comment:
this is also nullable; see constructor.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-connector-kafka] zentol commented on a diff in pull request #1: [FLINK-30052][Connectors/Kafka] Move existing Kafka connector code from Flink repo to dedicated Kafka repo
zentol commented on code in PR #1: URL: https://github.com/apache/flink-connector-kafka/pull/1#discussion_r1082317243 ## flink-connector-kafka/pom.xml: ## @@ -18,259 +18,292 @@ specific language governing permissions and limitations under the License. --> http://maven.apache.org/POM/4.0.0; -xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance; -xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd;> - - 4.0.0 - - - flink-connectors - org.apache.flink - 1.16-SNAPSHOT - - - flink-connector-kafka Review Comment: can we make the whitespace changes in a separate commit? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #21738: [FLINK-30761][coordination,test] Replaces JVM assert with Preconditions in leader election code
flinkbot commented on PR #21738: URL: https://github.com/apache/flink/pull/21738#issuecomment-1398166208 ## CI report: * b6fb5cacd48f5c91c7cf27ea45395696b2eb04f8 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-connector-cassandra] zentol commented on pull request #3: [FLINK-26822] Add Cassandra Source
zentol commented on PR #3: URL: https://github.com/apache/flink-connector-cassandra/pull/3#issuecomment-1398165894 > So I think I'll try to reuse this code, migrate it to Flink and update it to the latest Cassandra version and push it in this PR. Sounds good to me so far. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-connector-cassandra] zentol commented on pull request #3: [FLINK-26822] Add Cassandra Source
zentol commented on PR #3: URL: https://github.com/apache/flink-connector-cassandra/pull/3#issuecomment-1398165328 > I don't think it is an ASF rule but fair enough, FYI; By and large it should be viewed as a legal requirement. By copying code from cassandra you have to adhere to their licensing, which among other state that you must have prominent notices for changes to a file. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] XComp opened a new pull request, #21738: [FLINK-30761][coordination,test] Replaces JVM assert with Preconditions in leader election code
XComp opened a new pull request, #21738: URL: https://github.com/apache/flink/pull/21738 ## What is the purpose of the change The intention is to make the code more robust to test failures. We do no enable asserts in the test runs. The JVM has asserts disabled by default. That would mean that invalid state would go unnoticed if we continue to use assert instead of Preconditions. ## Brief change log * replaced `assert` with Precondition checks ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? not applicable -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #21737: [FLINK-30760][runtime] Fixes wrongly used @GuardedBy annotation
flinkbot commented on PR #21737: URL: https://github.com/apache/flink/pull/21737#issuecomment-1398141726 ## CI report: * 826f33a2bd51e93a65956d5bb50d64c99eb55f3f UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] XComp opened a new pull request, #21737: [FLINK-30760][runtime] Fixes wrongly used @GuardedBy annotation
XComp opened a new pull request, #21737: URL: https://github.com/apache/flink/pull/21737 ## What is the purpose of the change The @GuardedBy annotations were assigned to some public methods which are not called under the specified lock. @GuardedBy should be used by methods that are only allowed to be called within the context of the lock that is specified in the annotation. This is a preparation task for FLINK-26522/FLIP-285 where introduce new internal methods that actually need to be properly annotated by the `@GuardedBy` annotation. ## Brief change log * removes the annotations in methods that are called outside of the lock ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? not applicable -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] pnowojski commented on pull request #20151: [FLINK-26803][checkpoint] Merging channel state files
pnowojski commented on PR #20151: URL: https://github.com/apache/flink/pull/20151#issuecomment-1398086486 Thanks, it looks good. Once you squash fixup commits I will do the last pass and hopefully merge. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] ZhongFuCheng3y commented on pull request #21553: [FLINK-30492][doc] fix incorrect dependency artifactId in hive overview.
ZhongFuCheng3y commented on PR #21553: URL: https://github.com/apache/flink/pull/21553#issuecomment-1398010881 > @reswqa @ZhongFuCheng3y Hive requires the `flink-table-planner_2.12-.jar`, so for example ` flink-table-planner_2.12-1.16.0.jar`. See https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/connectors/table/hive/overview/#moving-the-planner-jar > > That means that if you want to run this locally, you should not include `flink-table-api-java-bridge_2.12` but you should include flink-table-api-scala-bridge_2.12, per https://nightlies.apache.org/flink/flink-docs-master/docs/dev/configuration/overview/#flink-apis > > That's what I tried to say by mention that Hive still requires Scala (hence it still has the Scala suffix), which implies that you will also need to use all other artifacts in the Scala version. ths! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #21736: [FLINK-27518][tests] Refactor migration tests to support version update automatically
flinkbot commented on PR #21736: URL: https://github.com/apache/flink/pull/21736#issuecomment-1397936174 ## CI report: * f7edc0bb36dda4c6144c97a73c8167c0e2bf0a0e UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] gaoyunhaii commented on pull request #21736: [FLINK-27518][tests] Refactor migration tests to support version update automatically
gaoyunhaii commented on PR #21736: URL: https://github.com/apache/flink/pull/21736#issuecomment-1397934193 @XComp could you have a look at the PR? Very thanks! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] gaoyunhaii opened a new pull request, #21736: [FLINK-27518][tests] Refactor migration tests to support version update automatically
gaoyunhaii opened a new pull request, #21736: URL: https://github.com/apache/flink/pull/21736 ## What is the purpose of the change This PR refactors the state migration tests so that when cutting branch, we need only add new version and could generates the states of stale version automatically. In general, there are two options: 1. Similar to the configuration document generator, we could have a module that depends on all the modules containing migration tests and run generation with this module. 2. Introduce tools to generate states, and each module config the tools separately. We finally choose the option 2. This is because Maven have a bad support for depending on the tests classes of other modules, we could only use the `test-jar`, which do not support transitive dependency and make it hard to manage these transitive dependencies. Except for the generating, during the refactoring we also make each migration tests use a dynamic version lists: `[start, FlinkVersion.last()]`, which free us from manually change the list on cutting branch for each version. ## Brief change log - Introduce a new framework of migration tests. - Introduce tools to scan the test classes of the configured module and generating snapshots. - Refactor existing tests based on the new framework. ## Verifying this change Manually verified the process of - Add version 1.18 to `FlinkVersion`. - Generating states automatically via `mvn clean package -Pgenerate-snapshots -Dgenerate.version=1.17 -nsu -DskipRat -Dcheckstyle.skip -Drat.ignoreErrors=true -DspotlessFiles=ineffective -Dfast -DskipTests -pl flink-core -am` - Run the existing tests and verified the tests including the ones against 1.17 are all executed successfully. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): **no** - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: **no** - The serializers: **no** - The runtime per-record code paths (performance sensitive): **no** - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: **no** - The S3 file system connector: **no** ## Documentation - Does this pull request introduce a new feature? **Yes** - If yes, how is the feature documented? **docs** -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] swuferhong commented on a diff in pull request #21724: [FLINK-30727][table-planner] Fix JoinReorderITCaseBase.testBushyTreeJoinReorder failed
swuferhong commented on code in PR #21724:
URL: https://github.com/apache/flink/pull/21724#discussion_r1082114927
##
flink-table/flink-table-planner/src/test/java/org/apache/flink/table/planner/runtime/stream/sql/join/JoinReorderITCase.java:
##
@@ -42,6 +45,12 @@ public class JoinReorderITCase extends JoinReorderITCaseBase
{
private StreamExecutionEnvironment env;
+@AfterEach
+public void after() {
Review Comment:
> This is the root cause? Do you reproduce failed test locally?
This error can not be reproduce in local. I think the root cause is the
`StreamTestSink.clear();` not be called after tests finished.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] swuferhong commented on pull request #21724: [FLINK-30727][table-planner] Fix JoinReorderITCaseBase.testBushyTreeJoinReorder failed
swuferhong commented on PR #21724: URL: https://github.com/apache/flink/pull/21724#issuecomment-1397929362 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] JingGe commented on a diff in pull request #21322: [FLINK-30025][table] Unified the max display column width for SqlClient and Table APi in both Streaming and Batch execMode
JingGe commented on code in PR #21322:
URL: https://github.com/apache/flink/pull/21322#discussion_r1082088415
##
flink-table/flink-table-api-java/src/main/java/org/apache/flink/table/api/internal/TableEnvironmentImpl.java:
##
@@ -926,7 +926,7 @@ private TableResultInternal
executeQueryOperation(QueryOperation operation) {
DataTypeUtils.expandCompositeTypeToSchema(
sinkOperation.getConsumedDataType()),
resultProvider.getRowDataStringConverter(),
-PrintStyle.DEFAULT_MAX_COLUMN_WIDTH,
Review Comment:
It will be removed while removing deprecated
sql-client.display.max-column-width. A follow-up ticket has been created:
https://issues.apache.org/jira/browse/FLINK-30758
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] JingGe commented on a diff in pull request #21322: [FLINK-30025][table] Unified the max display column width for SqlClient and Table APi in both Streaming and Batch execMode
JingGe commented on code in PR #21322:
URL: https://github.com/apache/flink/pull/21322#discussion_r1082086891
##
flink-table/flink-table-api-java/src/main/java/org/apache/flink/table/api/config/TableConfigOptions.java:
##
@@ -102,6 +102,16 @@ private TableConfigOptions() {}
+ "the session time zone is used during
conversion. The input of option is either a full name "
+ "such as \"America/Los_Angeles\", or a
custom timezone id such as \"GMT-08:00\".");
+@Documentation.TableOption(execMode = Documentation.ExecMode.STREAMING)
+public static final ConfigOption PRINT_MAX_COLUMN_WIDTH =
Review Comment:
deprecate sql-client.display.max-column-width
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] LadyForest commented on pull request #21727: [FLINK-30752][python] Support 'EXPLAIN PLAN_ADVICE' statement in PyFlink
LadyForest commented on PR #21727: URL: https://github.com/apache/flink/pull/21727#issuecomment-1397885340 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] lincoln-lil closed pull request #21676: [FLINK-30662][table] Planner supports delete
lincoln-lil closed pull request #21676: [FLINK-30662][table] Planner supports delete URL: https://github.com/apache/flink/pull/21676 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] fsk119 commented on a diff in pull request #21717: [FLINK-29945][sql-client] Supports to submit SQL to a embedded SQL Ga…
fsk119 commented on code in PR #21717: URL: https://github.com/apache/flink/pull/21717#discussion_r1082055861 ## flink-table/flink-sql-client/src/test/resources/sql/table.q: ## @@ -79,7 +79,10 @@ show tables; # test SHOW CREATE TABLE show create table orders; -CREATE TABLE `default_catalog`.`default_database`.`orders` ( ++-+ Review Comment: In the FLIP, we do reach an agreement about the presentation. BTW, I think it's the first version of the presentation when the input line is too long. From my experience, we should support printing the results with multiple lines. 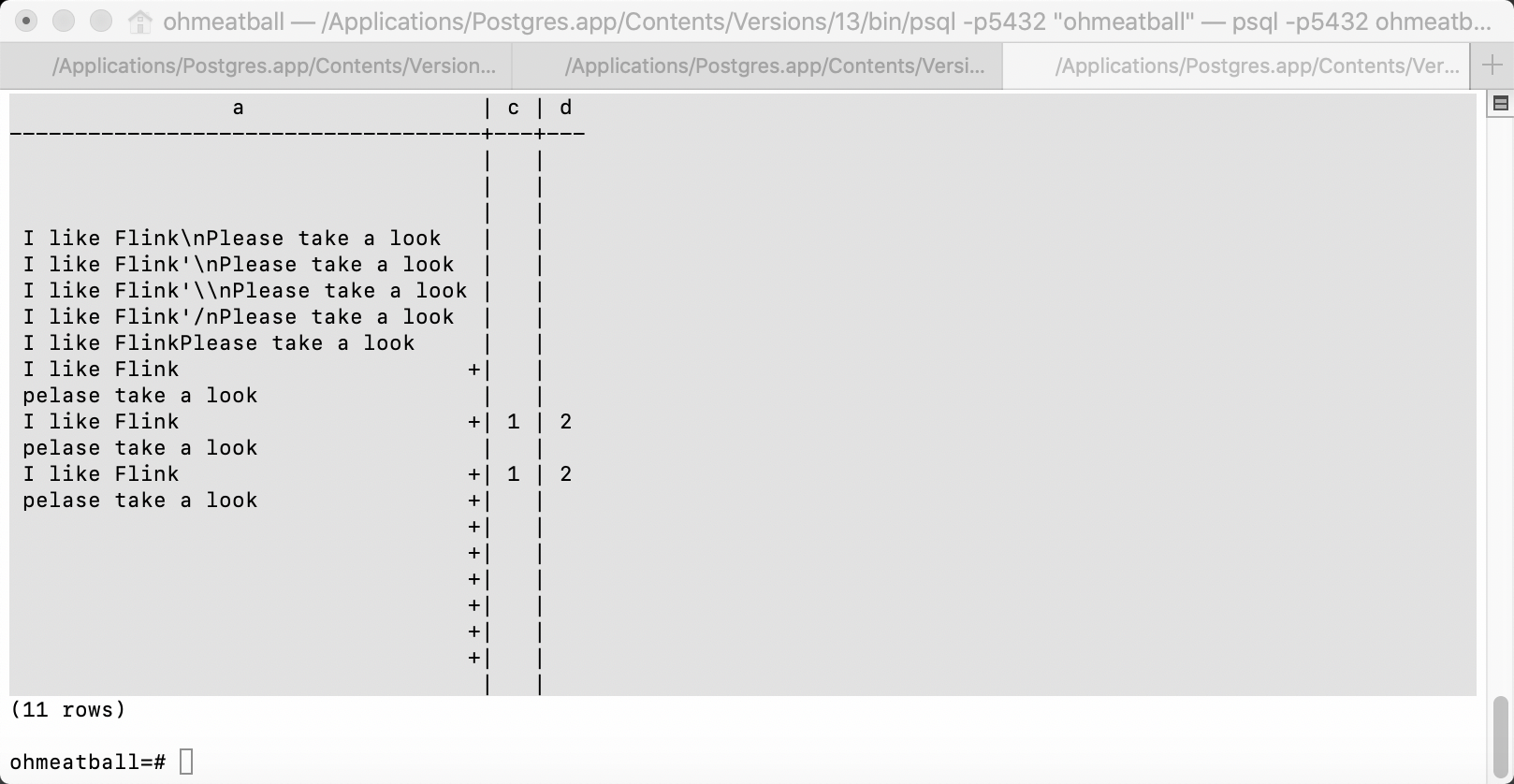 In PG/Presto, the client uses '+' to indicate the current line is part of the last line. Considering the current change is so large, I think we can move the improvements to the future. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-ml] jiangxin369 commented on pull request #201: [FLINK-27716] Add Python API docs in ML
jiangxin369 commented on PR #201: URL: https://github.com/apache/flink-ml/pull/201#issuecomment-1397846787 @lindong28 Could you help to review this PR? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] 1996fanrui commented on a diff in pull request #20151: [FLINK-26803][checkpoint] Merging channel state files
1996fanrui commented on code in PR #20151: URL: https://github.com/apache/flink/pull/20151#discussion_r1082041845 ## flink-runtime/src/main/java/org/apache/flink/runtime/checkpoint/channel/ChannelStateWriteRequestExecutorImpl.java: ## @@ -51,27 +66,40 @@ class ChannelStateWriteRequestExecutorImpl implements ChannelStateWriteRequestEx private final Thread thread; private volatile Exception thrown = null; private volatile boolean wasClosed = false; -private final String taskName; + +private final Map> unreadyQueues = +new ConcurrentHashMap<>(); + +private final JobID jobID; +private final Set subtasks; +private final AtomicBoolean isRegistering = new AtomicBoolean(true); +private final int numberOfSubtasksShareFile; Review Comment: Sorry, after address your next [comment](https://github.com/apache/flink/pull/20151#discussion_r1081119337), I found we can add the `lock.notifyAll()` during close. When the executor is closed, the while loop inside of `waitAndTakeUnsafe` will be finished, then `waitAndTakeUnsafe` will return `null`, and the `executor thread` can be finished. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] 1996fanrui commented on a diff in pull request #20151: [FLINK-26803][checkpoint] Merging channel state files
1996fanrui commented on code in PR #20151:
URL: https://github.com/apache/flink/pull/20151#discussion_r1082043383
##
flink-runtime/src/main/java/org/apache/flink/runtime/checkpoint/channel/ChannelStateWriteRequestExecutorImpl.java:
##
@@ -107,49 +119,78 @@ void run() {
try {
closeAll(
this::cleanupRequests,
-() ->
-dispatcher.fail(
-thrown == null ? new
CancellationException() : thrown));
+() -> {
+Throwable cause;
+synchronized (lock) {
+cause = thrown == null ? new
CancellationException() : thrown;
+}
+dispatcher.fail(cause);
+});
} catch (Exception e) {
-//noinspection NonAtomicOperationOnVolatileField
-thrown = ExceptionUtils.firstOrSuppressed(e, thrown);
+synchronized (lock) {
+//noinspection NonAtomicOperationOnVolatileField
+thrown = ExceptionUtils.firstOrSuppressed(e, thrown);
+}
}
FileSystemSafetyNet.closeSafetyNetAndGuardedResourcesForThread();
}
LOG.debug("loop terminated");
}
private void loop() throws Exception {
-while (!wasClosed) {
+while (true) {
try {
-ChannelStateWriteRequest request = deque.take();
-// The executor will end the registration, when the start
request comes.
-// Because the checkpoint can be started after all tasks are
initiated.
-if (request instanceof CheckpointStartRequest &&
isRegistering()) {
-checkState(
-isRegistering.compareAndSet(true, false),
-"Transition isRegistering failed.");
+ChannelStateWriteRequest request;
+boolean completeRegister = false;
+synchronized (lock) {
+if (wasClosed) {
+return;
+}
+request = waitAndTakeUnsafe();
+// The executor will end the registration, when the start
request comes.
+// Because the checkpoint can be started after all tasks
are initiated.
+if (request instanceof CheckpointStartRequest) {
+completeRegister = completeRegister();
+}
+}
+if (completeRegister) {
onRegistered.accept(this);
}
dispatcher.dispatch(request);
} catch (InterruptedException e) {
-if (!wasClosed) {
-LOG.debug(
-"Channel state executor is interrupted while
waiting for a request (continue waiting)",
-e);
-} else {
-Thread.currentThread().interrupt();
+synchronized (lock) {
+if (!wasClosed) {
+LOG.debug(
+"Channel state executor is interrupted while
waiting for a request (continue waiting)",
+e);
+} else {
+Thread.currentThread().interrupt();
+}
}
}
}
}
+private ChannelStateWriteRequest waitAndTakeUnsafe() throws
InterruptedException {
+ChannelStateWriteRequest request;
+while (true) {
Review Comment:
Thanks for your review, updated.
I didn't squash commits, and add a new fixup commit, it should be easy to
review. And I can squash them and rebase master after you think it's ok.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] 1996fanrui commented on a diff in pull request #20151: [FLINK-26803][checkpoint] Merging channel state files
1996fanrui commented on code in PR #20151:
URL: https://github.com/apache/flink/pull/20151#discussion_r1082043383
##
flink-runtime/src/main/java/org/apache/flink/runtime/checkpoint/channel/ChannelStateWriteRequestExecutorImpl.java:
##
@@ -107,49 +119,78 @@ void run() {
try {
closeAll(
this::cleanupRequests,
-() ->
-dispatcher.fail(
-thrown == null ? new
CancellationException() : thrown));
+() -> {
+Throwable cause;
+synchronized (lock) {
+cause = thrown == null ? new
CancellationException() : thrown;
+}
+dispatcher.fail(cause);
+});
} catch (Exception e) {
-//noinspection NonAtomicOperationOnVolatileField
-thrown = ExceptionUtils.firstOrSuppressed(e, thrown);
+synchronized (lock) {
+//noinspection NonAtomicOperationOnVolatileField
+thrown = ExceptionUtils.firstOrSuppressed(e, thrown);
+}
}
FileSystemSafetyNet.closeSafetyNetAndGuardedResourcesForThread();
}
LOG.debug("loop terminated");
}
private void loop() throws Exception {
-while (!wasClosed) {
+while (true) {
try {
-ChannelStateWriteRequest request = deque.take();
-// The executor will end the registration, when the start
request comes.
-// Because the checkpoint can be started after all tasks are
initiated.
-if (request instanceof CheckpointStartRequest &&
isRegistering()) {
-checkState(
-isRegistering.compareAndSet(true, false),
-"Transition isRegistering failed.");
+ChannelStateWriteRequest request;
+boolean completeRegister = false;
+synchronized (lock) {
+if (wasClosed) {
+return;
+}
+request = waitAndTakeUnsafe();
+// The executor will end the registration, when the start
request comes.
+// Because the checkpoint can be started after all tasks
are initiated.
+if (request instanceof CheckpointStartRequest) {
+completeRegister = completeRegister();
+}
+}
+if (completeRegister) {
onRegistered.accept(this);
}
dispatcher.dispatch(request);
} catch (InterruptedException e) {
-if (!wasClosed) {
-LOG.debug(
-"Channel state executor is interrupted while
waiting for a request (continue waiting)",
-e);
-} else {
-Thread.currentThread().interrupt();
+synchronized (lock) {
+if (!wasClosed) {
+LOG.debug(
+"Channel state executor is interrupted while
waiting for a request (continue waiting)",
+e);
+} else {
+Thread.currentThread().interrupt();
+}
}
}
}
}
+private ChannelStateWriteRequest waitAndTakeUnsafe() throws
InterruptedException {
+ChannelStateWriteRequest request;
+while (true) {
Review Comment:
Thanks for your review, updated.
I didn't squash commits, and add a new fixup commit, it should be easy to
review. And I can squash them after you think it's ok.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-connector-kafka] mas-chen commented on pull request #1: [FLINK-30052][Connectors/Kafka] Move existing Kafka connector code from Flink repo to dedicated Kafka repo
mas-chen commented on PR #1: URL: https://github.com/apache/flink-connector-kafka/pull/1#issuecomment-1397828588 CI now passes on my fork -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] 1996fanrui commented on a diff in pull request #20151: [FLINK-26803][checkpoint] Merging channel state files
1996fanrui commented on code in PR #20151: URL: https://github.com/apache/flink/pull/20151#discussion_r1082041845 ## flink-runtime/src/main/java/org/apache/flink/runtime/checkpoint/channel/ChannelStateWriteRequestExecutorImpl.java: ## @@ -51,27 +66,40 @@ class ChannelStateWriteRequestExecutorImpl implements ChannelStateWriteRequestEx private final Thread thread; private volatile Exception thrown = null; private volatile boolean wasClosed = false; -private final String taskName; + +private final Map> unreadyQueues = +new ConcurrentHashMap<>(); + +private final JobID jobID; +private final Set subtasks; +private final AtomicBoolean isRegistering = new AtomicBoolean(true); +private final int numberOfSubtasksShareFile; Review Comment: Sorry, after address your next [comment](https://github.com/apache/flink/pull/20151#discussion_r1081119337), I found we can add the `lock.notifyAll()` here. When the executor is closed, the while loop inside of `waitAndTakeUnsafe` will be finished, then `waitAndTakeUnsafe` will return `null`, and the `executor thread` can be finished. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #21735: [hotfix] [docs] Fix a typo in a query that erroneously tries to perform an aggregation on a string column
flinkbot commented on PR #21735: URL: https://github.com/apache/flink/pull/21735#issuecomment-1397810857 ## CI report: * 37175760368c64b665e16e5cf8b7eb4f4e951fee UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] karanasher opened a new pull request, #21735: [hotfix] [docs] Fix a typo in a query that erroneously tries to perform an aggregation on a string column
karanasher opened a new pull request, #21735: URL: https://github.com/apache/flink/pull/21735 Fix a typo in a query that erroneously tries to perform an aggregation on a string column. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] 1996fanrui commented on a diff in pull request #20151: [FLINK-26803][checkpoint] Merging channel state files
1996fanrui commented on code in PR #20151:
URL: https://github.com/apache/flink/pull/20151#discussion_r1082023420
##
flink-runtime/src/main/java/org/apache/flink/runtime/checkpoint/channel/ChannelStateWriteRequestExecutorImpl.java:
##
@@ -51,27 +66,40 @@ class ChannelStateWriteRequestExecutorImpl implements
ChannelStateWriteRequestEx
private final Thread thread;
private volatile Exception thrown = null;
private volatile boolean wasClosed = false;
-private final String taskName;
+
+private final Map>
unreadyQueues =
+new ConcurrentHashMap<>();
+
+private final JobID jobID;
+private final Set subtasks;
+private final AtomicBoolean isRegistering = new AtomicBoolean(true);
+private final int numberOfSubtasksShareFile;
Review Comment:
This is code about `lock.wait()`, if we add the `lock.notifyAll()`, the
`lock.wait()` will return directly. And the `request` is still null,
`lock.wait` will be blocked again. So the `lock.notifyAll()` doesn't work.
That's why I think the `thread.interrupt()` is enough here.
```
private ChannelStateWriteRequest waitAndTakeUnsafe() throws
InterruptedException {
ChannelStateWriteRequest request;
while (true) {
request = deque.pollFirst();
if (request == null) {
lock.wait();
} else {
return request;
}
}
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] morhidi closed pull request #463: [FLINK-30119] Breaking change: Flink Kubernetes Operator should store…
morhidi closed pull request #463: [FLINK-30119] Breaking change: Flink Kubernetes Operator should store… URL: https://github.com/apache/flink-kubernetes-operator/pull/463 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] morhidi commented on pull request #463: [FLINK-30119] Breaking change: Flink Kubernetes Operator should store…
morhidi commented on PR #463: URL: https://github.com/apache/flink-kubernetes-operator/pull/463#issuecomment-1397797194 After discussing it with Clara, I'm colsing this for the time being. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] dchristle commented on pull request #21729: [FLINK-30751] [docs] Remove references to disableDataSync in RocksDB documentation
dchristle commented on PR #21729: URL: https://github.com/apache/flink/pull/21729#issuecomment-1397381115 Hi @Myasuka, Thanks for reviewing this PR! I split the changes into separate commits. The first commit removes `disableDataSync`, and the last commit aligns the PyFlink RocksDB documentation with its Java equivalent, as you requested. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] dchristle commented on a diff in pull request #21729: [FLINK-30751] [docs] Remove references to disableDataSync in RocksDB documentation
dchristle commented on code in PR #21729: URL: https://github.com/apache/flink/pull/21729#discussion_r1081619201 ## flink-python/pyflink/datastream/state_backend.py: ## @@ -956,16 +956,20 @@ class PredefinedOptions(Enum): determined to be beneficial for performance under different settings. Some of these settings are based on experiments by the Flink community, some follow -guides from the RocksDB project. +guides from the RocksDB project. Some configurations are enabled unconditionally (e.g. +setUseFsync(false), which disables syncing to storage) so they do not appear here. See the +documentation for the createBaseCommonDBOptions() and createBaseCommonColumnOptions() methods Review Comment: That makes sense. I originally made this change to make PyFlink documentation match closely to the same description from the Java documentation, but mentioning the Java classes & non-public methods probably adds confusion. I made this change in the most recent commits. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] RyanSkraba commented on pull request #19970: [FLINK-27970][tests][JUnit5 migration] flink-hadoop-bulk
RyanSkraba commented on PR #19970: URL: https://github.com/apache/flink/pull/19970#issuecomment-1397364945 Hello! I've rebased this PR to master and fixed the merge conflicts in the meantime. I will be mostly away from my computer for a couple of weeks, but I'll check in if anything changes! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] RyanSkraba commented on pull request #21289: [FLINK-29452] Allow unit tests to be executed independently
RyanSkraba commented on PR #21289: URL: https://github.com/apache/flink/pull/21289#issuecomment-1397363704 Hello! I've rebased this PR to master. I don't believe there are any remaining requested changes that I haven't addressed (by comment or other). I will be mostly away from my computer for a couple of weeks, but I'll check in if anything changes! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] dchristle commented on a diff in pull request #21729: [FLINK-30751] [docs] Remove references to disableDataSync in RocksDB documentation
dchristle commented on code in PR #21729: URL: https://github.com/apache/flink/pull/21729#discussion_r1081578012 ## flink-python/pyflink/datastream/state_backend.py: ## @@ -1000,21 +1000,24 @@ class PredefinedOptions(Enum): The following options are set: +- BlockBasedTableConfig.setBlockCacheSize(256 MBytes) +- BlockBasedTableConfig.setBlockSize(128 KBytes) +- BlockBasedTableConfig.setFilterPolicy(BloomFilter( +`BLOOM_FILTER_BITS_PER_KEY`, +`BLOOM_FILTER_BLOCK_BASED_MODE`) - setLevelCompactionDynamicLevelBytes(true) -- setTargetFileSizeBase(256 MBytes) +- setMaxBackgroundJobs(4) - setMaxBytesForLevelBase(1 GByte) -- setWriteBufferSize(64 MBytes) -- setIncreaseParallelism(4) -- setMinWriteBufferNumberToMerge(3) -- setMaxWriteBufferNumber(4) -- setUseFsync(false) - setMaxOpenFiles(-1) -- BlockBasedTableConfig.setBlockCacheSize(256 MBytes) -- BlockBasedTableConfigsetBlockSize(128 KBytes) +- setMaxWriteBufferNumber(4) Review Comment: Originally, I wanted to remove just the erroneous `disableDataSync`, but in doing this, I noticed other errors like the missing Bloom filter or that the Python documentation implies `setUseFSync(false)` is set while the Java docs don't (not technically a mistake, but it's confusing & not easy to see from the code). Sorting isn't strictly necessary, but it _was_ part of how I found the Bloom filter setting was undocumented & manually verified each group of options now matches its description. It lets readers quickly determine whether a particular setting they have in mind is changed or not. Since it is easier to see at a glance when a new config is added, or an old one removed, future maintainers have a lower probability of introducing bugs or making the documentation & code diverge like it did for the Bloom filter. It isn't strictly necessary to sort in this PR, either, but the overhead of creating a separate PR/separate JIRA issue seems too high for such a simple change. I can add these other non-idealities that I fixed into the JIRA issue description. Would that be an OK path forward, rather than deferring these minor polishes into separate PRs? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] RyanSkraba commented on pull request #19897: [FLINK-27885][tests][JUnit5 migration] flink-csv
RyanSkraba commented on PR #19897: URL: https://github.com/apache/flink/pull/19897#issuecomment-1397317096 Hello! I've rebased this PR to master. I don't believe there are any remaining requested changes that I haven't addressed (by comment or other). I will be mostly away from my computer for a couple of weeks, but I'll check in if anything changes! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] mbalassi commented on pull request #21732: [FLINK-30754][tests] Fix ExceptionThrowingDelegationTokenProvider/Receiver multi-threaded test issues
mbalassi commented on PR #21732: URL: https://github.com/apache/flink/pull/21732#issuecomment-1397310760 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] dawidwys commented on a diff in pull request #21635: [FLINK-30613] Improve resolving schema compatibility -- Milestone one
dawidwys commented on code in PR #21635:
URL: https://github.com/apache/flink/pull/21635#discussion_r1081546445
##
flink-python/src/main/java/org/apache/flink/table/runtime/typeutils/serializers/python/MapDataSerializer.java:
##
@@ -227,25 +225,22 @@ public void readSnapshot(int readVersion, DataInputView
in, ClassLoader userCode
@Override
public TypeSerializer restoreSerializer() {
-return new MapDataSerializer(
-previousKeyType,
-previousValueType,
-previousKeySerializer,
-previousValueSerializer);
+return new MapDataSerializer(keyType, valueType, keySerializer,
valueSerializer);
}
@Override
public TypeSerializerSchemaCompatibility
resolveSchemaCompatibility(
-TypeSerializer newSerializer) {
-if (!(newSerializer instanceof MapDataSerializer)) {
+TypeSerializerSnapshot oldSerializerSnapshot) {
+if (!(oldSerializerSnapshot instanceof BaseMapSerializerSnapshot))
{
Review Comment:
Why has the type changed in the check?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] dawidwys commented on a diff in pull request #21635: [FLINK-30613] Improve resolving schema compatibility -- Milestone one
dawidwys commented on code in PR #21635:
URL: https://github.com/apache/flink/pull/21635#discussion_r1081544400
##
flink-python/src/main/java/org/apache/flink/table/runtime/typeutils/serializers/python/RowDataSerializer.java:
##
@@ -194,31 +193,33 @@ public void readSnapshot(int readVersion, DataInputView
in, ClassLoader userCode
@Override
public RowDataSerializer restoreSerializer() {
return new RowDataSerializer(
-previousTypes,
-
nestedSerializersSnapshotDelegate.getRestoredNestedSerializers());
+types,
nestedSerializersSnapshotDelegate.getRestoredNestedSerializers());
}
@Override
public TypeSerializerSchemaCompatibility
resolveSchemaCompatibility(
-TypeSerializer newSerializer) {
-if (!(newSerializer instanceof RowDataSerializer)) {
+TypeSerializerSnapshot oldSerializerSnapshot) {
+if (!(oldSerializerSnapshot instanceof RowDataSerializerSnapshot))
{
return TypeSerializerSchemaCompatibility.incompatible();
}
-RowDataSerializer newRowSerializer = (RowDataSerializer)
newSerializer;
-if (!Arrays.equals(previousTypes, newRowSerializer.fieldTypes)) {
+RowDataSerializerSnapshot oldRowDataSerializerSnapshot =
+(RowDataSerializerSnapshot) oldSerializerSnapshot;
+if (!Arrays.equals(types, oldRowDataSerializerSnapshot.types)) {
return TypeSerializerSchemaCompatibility.incompatible();
}
CompositeTypeSerializerUtil.IntermediateCompatibilityResult
intermediateResult =
CompositeTypeSerializerUtil.constructIntermediateCompatibilityResult(
-newRowSerializer.fieldSerializers,
+
oldRowDataSerializerSnapshot.nestedSerializersSnapshotDelegate
+.getNestedSerializerSnapshots(),
nestedSerializersSnapshotDelegate
.getNestedSerializerSnapshots());
if (intermediateResult.isCompatibleWithReconfiguredSerializer()) {
-RowDataSerializer reconfiguredCompositeSerializer =
restoreSerializer();
+org.apache.flink.table.runtime.typeutils.RowDataSerializer
Review Comment:
Is that correct? This looks wrong.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] dawidwys commented on a diff in pull request #21635: [FLINK-30613] Improve resolving schema compatibility -- Milestone one
dawidwys commented on code in PR #21635:
URL: https://github.com/apache/flink/pull/21635#discussion_r1081541284
##
flink-scala/src/main/scala/org/apache/flink/api/scala/typeutils/ScalaEnumSerializerSnapshot.scala:
##
@@ -80,25 +80,26 @@ class ScalaEnumSerializerSnapshot[E <: Enumeration] extends
TypeSerializerSnapsh
new EnumValueSerializer(enumObject)
}
- override def resolveSchemaCompatibility(
- newSerializer: TypeSerializer[E#Value]):
TypeSerializerSchemaCompatibility[E#Value] = {
+ override def resolveSchemaCompatibility(oldSerializerSnapshot:
TypeSerializerSnapshot[E#Value])
+ : TypeSerializerSchemaCompatibility[E#Value] = {
Preconditions.checkState(enumClass != null)
-Preconditions.checkState(previousEnumConstants != null)
+Preconditions.checkState(enumConstants != null)
-if (!newSerializer.isInstanceOf[EnumValueSerializer[E]]) {
+if (!oldSerializerSnapshot.isInstanceOf[ScalaEnumSerializerSnapshot[E]]) {
return TypeSerializerSchemaCompatibility.incompatible()
}
-val newEnumSerializer = newSerializer.asInstanceOf[EnumValueSerializer[E]]
-if (!enumClass.equals(newEnumSerializer.enum.getClass)) {
+val oldEnumSerializerSnapshot =
+ oldSerializerSnapshot.asInstanceOf[ScalaEnumSerializerSnapshot[E]]
+if (!enumClass.equals(oldEnumSerializerSnapshot.enumClass)) {
return TypeSerializerSchemaCompatibility.incompatible()
}
-for ((previousEnumName, index) <- previousEnumConstants) {
+for ((enumName, index) <- oldEnumSerializerSnapshot.enumConstants) {
try {
-val newEnumName = newEnumSerializer.enum(index).toString
-if (previousEnumName != newEnumName) {
+val oldEnumName = enumConstants(index)._1
Review Comment:
```suggestion
val enumName = enumConstants(index)._1
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] dawidwys commented on a diff in pull request #21635: [FLINK-30613] Improve resolving schema compatibility -- Milestone one
dawidwys commented on code in PR #21635:
URL: https://github.com/apache/flink/pull/21635#discussion_r1081540937
##
flink-scala/src/main/scala/org/apache/flink/api/scala/typeutils/ScalaEnumSerializerSnapshot.scala:
##
@@ -80,25 +80,26 @@ class ScalaEnumSerializerSnapshot[E <: Enumeration] extends
TypeSerializerSnapsh
new EnumValueSerializer(enumObject)
}
- override def resolveSchemaCompatibility(
- newSerializer: TypeSerializer[E#Value]):
TypeSerializerSchemaCompatibility[E#Value] = {
+ override def resolveSchemaCompatibility(oldSerializerSnapshot:
TypeSerializerSnapshot[E#Value])
+ : TypeSerializerSchemaCompatibility[E#Value] = {
Preconditions.checkState(enumClass != null)
-Preconditions.checkState(previousEnumConstants != null)
+Preconditions.checkState(enumConstants != null)
-if (!newSerializer.isInstanceOf[EnumValueSerializer[E]]) {
+if (!oldSerializerSnapshot.isInstanceOf[ScalaEnumSerializerSnapshot[E]]) {
return TypeSerializerSchemaCompatibility.incompatible()
}
-val newEnumSerializer = newSerializer.asInstanceOf[EnumValueSerializer[E]]
-if (!enumClass.equals(newEnumSerializer.enum.getClass)) {
+val oldEnumSerializerSnapshot =
+ oldSerializerSnapshot.asInstanceOf[ScalaEnumSerializerSnapshot[E]]
+if (!enumClass.equals(oldEnumSerializerSnapshot.enumClass)) {
return TypeSerializerSchemaCompatibility.incompatible()
}
-for ((previousEnumName, index) <- previousEnumConstants) {
+for ((enumName, index) <- oldEnumSerializerSnapshot.enumConstants) {
Review Comment:
```suggestion
for ((oldEnumName, index) <- oldEnumSerializerSnapshot.enumConstants) {
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] dawidwys commented on a diff in pull request #21635: [FLINK-30613] Improve resolving schema compatibility -- Milestone one
dawidwys commented on code in PR #21635:
URL: https://github.com/apache/flink/pull/21635#discussion_r1081536771
##
flink-table/flink-table-runtime/src/main/java/org/apache/flink/table/runtime/typeutils/RowDataSerializer.java:
##
@@ -328,26 +327,27 @@ public void readSnapshot(int readVersion, DataInputView
in, ClassLoader userCode
@Override
public RowDataSerializer restoreSerializer() {
return new RowDataSerializer(
-previousTypes,
-
nestedSerializersSnapshotDelegate.getRestoredNestedSerializers());
+types,
nestedSerializersSnapshotDelegate.getRestoredNestedSerializers());
}
@Override
public TypeSerializerSchemaCompatibility
resolveSchemaCompatibility(
-TypeSerializer newSerializer) {
-if (!(newSerializer instanceof RowDataSerializer)) {
+TypeSerializerSnapshot oldSerializerSnapshot) {
+if (!(oldSerializerSnapshot instanceof RowDataSerializerSnapshot))
{
return TypeSerializerSchemaCompatibility.incompatible();
}
-RowDataSerializer newRowSerializer = (RowDataSerializer)
newSerializer;
-if (!Arrays.equals(previousTypes, newRowSerializer.types)) {
+RowDataSerializerSnapshot oldRowDataSerializerSnapshot =
+(RowDataSerializerSnapshot) oldSerializerSnapshot;
+if (!Arrays.equals(types, oldRowDataSerializerSnapshot.types)) {
return TypeSerializerSchemaCompatibility.incompatible();
}
CompositeTypeSerializerUtil.IntermediateCompatibilityResult
intermediateResult =
CompositeTypeSerializerUtil.constructIntermediateCompatibilityResult(
-newRowSerializer.fieldSerializers,
+
oldRowDataSerializerSnapshot.nestedSerializersSnapshotDelegate
Review Comment:
shouldn't the order of serializers be reversed here?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-connector-aws] boring-cyborg[bot] commented on pull request #36: [FLINK-30378][docs] Use modified sql_connector_download_table shortcode
boring-cyborg[bot] commented on PR #36: URL: https://github.com/apache/flink-connector-aws/pull/36#issuecomment-1397233856 Awesome work, congrats on your first merged pull request! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-connector-aws] zentol merged pull request #36: [FLINK-30378][docs] Use modified sql_connector_download_table shortcode
zentol merged PR #36: URL: https://github.com/apache/flink-connector-aws/pull/36 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] zentol merged pull request #21492: [FLINK-30378][docs] Add v2 sql_connector_download_table shortcode
zentol merged PR #21492: URL: https://github.com/apache/flink/pull/21492 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] zentol commented on pull request #17834: [FLINK-24941][datadog] Support Boolean gauges
zentol commented on PR #17834: URL: https://github.com/apache/flink/pull/17834#issuecomment-1397207313 So gauges are a bit annoying. Ideally we would only have Number gauges because really nothing else is properly supported by a majority of systems. Boolean gauges are usually a mistake from the get-go as well. Lets take the `isBackpressured` metric. This metric tells you whether the task is back-pressured right now at this very moment. That's a terrible metric to make any decision, and you should rather use `backPressuredTimeMsPerSecond` because it's not susceptible to bad luck. `isBackpressured` is only accurate if you are either 100% or 0% back-pressured; for everything in-between it's quite inaccurate (especially since the sampling interval is the reporting interval, aka typically in the order of seconds) (edited) That's why the PR didn't receive any attention. In a way it'd only enable users to rely on bad metrics. Sure, consistency across reporters isn't a bad argument, but this consistency should still provide some real value. Mapping booleans to ints isn't necessarily sound as well, because aggregating them isn't obvious. If we really wanted to supported gauges we'd ideally map them to a distribution I guess. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-connector-cassandra] echauchot commented on a diff in pull request #3: [FLINK-26822] Add Cassandra Source
echauchot commented on code in PR #3:
URL:
https://github.com/apache/flink-connector-cassandra/pull/3#discussion_r1081463284
##
flink-connector-cassandra/src/main/java/org/apache/flink/connector/cassandra/source/split/CassandraSplitSerializer.java:
##
@@ -0,0 +1,63 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.connector.cassandra.source.split;
+
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+
+import java.io.ByteArrayInputStream;
+import java.io.ByteArrayOutputStream;
+import java.io.IOException;
+import java.io.ObjectInputStream;
+import java.io.ObjectOutputStream;
+
+/** Serializer for {@link CassandraSplit}. */
+public class CassandraSplitSerializer implements
SimpleVersionedSerializer {
+
+public static final CassandraSplitSerializer INSTANCE = new
CassandraSplitSerializer();
+
+public static final int CURRENT_VERSION = 0;
+
+private CassandraSplitSerializer() {}
+
+@Override
+public int getVersion() {
+return CURRENT_VERSION;
+}
+
+@Override
+public byte[] serialize(CassandraSplit cassandraSplit) throws IOException {
+try (ByteArrayOutputStream byteArrayOutputStream = new
ByteArrayOutputStream();
+ObjectOutputStream objectOutputStream =
+new ObjectOutputStream(byteArrayOutputStream)) {
+objectOutputStream.writeObject(cassandraSplit);
Review Comment:
Makes sense
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] luoyuxia commented on a diff in pull request #21703: [FLINK-29880][hive] Introduce auto compaction for Hive sink in batch mode
luoyuxia commented on code in PR #21703:
URL: https://github.com/apache/flink/pull/21703#discussion_r1081459459
##
flink-connectors/flink-connector-hive/src/test/java/org/apache/flink/connectors/hive/HiveTableCompactSinkITCase.java:
##
@@ -0,0 +1,209 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.connectors.hive;
+
+import org.apache.flink.table.api.SqlDialect;
+import org.apache.flink.table.api.TableEnvironment;
+import org.apache.flink.table.api.TableResult;
+import org.apache.flink.table.catalog.hive.HiveCatalog;
+import org.apache.flink.table.catalog.hive.HiveTestUtils;
+import org.apache.flink.test.junit5.MiniClusterExtension;
+import org.apache.flink.types.Row;
+import org.apache.flink.util.CollectionUtil;
+
+import org.apache.hadoop.hive.conf.HiveConf;
+import org.junit.jupiter.api.AfterEach;
+import org.junit.jupiter.api.BeforeEach;
+import org.junit.jupiter.api.Test;
+import org.junit.jupiter.api.extension.RegisterExtension;
+
+import java.nio.file.Files;
+import java.nio.file.Path;
+import java.nio.file.Paths;
+import java.util.List;
+import java.util.stream.Collectors;
+
+import static org.assertj.core.api.Assertions.assertThat;
+
+/** IT case for Hive table compaction in batch mode. */
+public class HiveTableCompactSinkITCase {
+
+@RegisterExtension
+private static final MiniClusterExtension MINI_CLUSTER = new
MiniClusterExtension();
+
+private TableEnvironment tableEnv;
+private HiveCatalog hiveCatalog;
+private String warehouse;
+
+@BeforeEach
+public void setUp() {
+hiveCatalog = HiveTestUtils.createHiveCatalog();
+hiveCatalog.open();
+warehouse =
hiveCatalog.getHiveConf().getVar(HiveConf.ConfVars.METASTOREWAREHOUSE);
+tableEnv = HiveTestUtils.createTableEnvInBatchMode(SqlDialect.HIVE);
+tableEnv.registerCatalog(hiveCatalog.getName(), hiveCatalog);
+tableEnv.useCatalog(hiveCatalog.getName());
+}
+
+@AfterEach
+public void tearDown() {
+if (hiveCatalog != null) {
+hiveCatalog.close();
+}
+}
+
+@Test
+public void testNoCompaction() throws Exception {
Review Comment:
In deed, I'm intended to add case to cover `ALL_EXCHANGES_BLOCKING` for
it'll increase the test time. We always try to reduce the test time as hive
moudle has cost much time.
Also, from the side of these file compaction pipeline, the shuffle mode
makes no difference. And if we cover the two cases, what about the other
shuffle modes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] luoyuxia commented on a diff in pull request #21703: [FLINK-29880][hive] Introduce auto compaction for Hive sink in batch mode
luoyuxia commented on code in PR #21703:
URL: https://github.com/apache/flink/pull/21703#discussion_r1081459459
##
flink-connectors/flink-connector-hive/src/test/java/org/apache/flink/connectors/hive/HiveTableCompactSinkITCase.java:
##
@@ -0,0 +1,209 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.connectors.hive;
+
+import org.apache.flink.table.api.SqlDialect;
+import org.apache.flink.table.api.TableEnvironment;
+import org.apache.flink.table.api.TableResult;
+import org.apache.flink.table.catalog.hive.HiveCatalog;
+import org.apache.flink.table.catalog.hive.HiveTestUtils;
+import org.apache.flink.test.junit5.MiniClusterExtension;
+import org.apache.flink.types.Row;
+import org.apache.flink.util.CollectionUtil;
+
+import org.apache.hadoop.hive.conf.HiveConf;
+import org.junit.jupiter.api.AfterEach;
+import org.junit.jupiter.api.BeforeEach;
+import org.junit.jupiter.api.Test;
+import org.junit.jupiter.api.extension.RegisterExtension;
+
+import java.nio.file.Files;
+import java.nio.file.Path;
+import java.nio.file.Paths;
+import java.util.List;
+import java.util.stream.Collectors;
+
+import static org.assertj.core.api.Assertions.assertThat;
+
+/** IT case for Hive table compaction in batch mode. */
+public class HiveTableCompactSinkITCase {
+
+@RegisterExtension
+private static final MiniClusterExtension MINI_CLUSTER = new
MiniClusterExtension();
+
+private TableEnvironment tableEnv;
+private HiveCatalog hiveCatalog;
+private String warehouse;
+
+@BeforeEach
+public void setUp() {
+hiveCatalog = HiveTestUtils.createHiveCatalog();
+hiveCatalog.open();
+warehouse =
hiveCatalog.getHiveConf().getVar(HiveConf.ConfVars.METASTOREWAREHOUSE);
+tableEnv = HiveTestUtils.createTableEnvInBatchMode(SqlDialect.HIVE);
+tableEnv.registerCatalog(hiveCatalog.getName(), hiveCatalog);
+tableEnv.useCatalog(hiveCatalog.getName());
+}
+
+@AfterEach
+public void tearDown() {
+if (hiveCatalog != null) {
+hiveCatalog.close();
+}
+}
+
+@Test
+public void testNoCompaction() throws Exception {
Review Comment:
In deed, I'm intended to add case to cover `ALL_EXCHANGES_BLOCKING` for
it'll increase the test time and from the side of these file compaction
pipeline, the shuffle mode makes no difference.
And if we cover the two cases, what about the other shuffle modes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] healchow commented on a diff in pull request #21726: [FLINK-30748][docs]Translate "Overview" page of "Querys" into Chinese
healchow commented on code in PR #21726:
URL: https://github.com/apache/flink/pull/21726#discussion_r1081454537
##
docs/content.zh/docs/dev/table/sql/queries/overview.md:
##
@@ -155,110 +158,116 @@ sink_descriptor =
TableDescriptor.for_connector("filesystem")
t_env.create_temporary_table("RubberOrders", sink_descriptor)
-# run an INSERT SQL on the Table and emit the result to the TableSink
+# 在表上执行一个 INSERT SQL ,SQL结果写入到TableSink
table_env \
.execute_sql("INSERT INTO RubberOrders SELECT product, amount FROM Orders
WHERE product LIKE '%Rubber%'")
```
+
{{< /tab >}}
{{< /tabs >}}
{{< top >}}
-## Execute a Query
+## 执行查询
+通过`TableEnvironment.executeSql()`方法可以执行`SELECT`或`VALUES`语句,并把结果收集到本地.它将`SELECT`语句(或`VALUES`语句)的结果作为`TableResult`返回.和`SELECT`语句相似,`Table.execute()`方法可以执行`Table`对象,并把结果收集到本地客户端.
+`TableResult.collect()`方法返回一个可关闭的行迭代器(row
iterator).除非所有结果数据都被收集完成了,否则`SELECT`作业不会停止,所以应该积极使用`CloseableIterator#close()`方法关闭作业,以防止资源泄露.
`TableResult.print()`可以打印`SELECT`的结果到客户端的控制台中.`TableResult`上的结果数据只能被访问一次.因此`collect()`和`print()`只能二选一.
-A SELECT statement or a VALUES statement can be executed to collect the
content to local through the `TableEnvironment.executeSql()` method. The method
returns the result of the SELECT statement (or the VALUES statement) as a
`TableResult`. Similar to a SELECT statement, a `Table` object can be executed
using the `Table.execute()` method to collect the content of the query to the
local client.
-`TableResult.collect()` method returns a closeable row iterator. The select
job will not be finished unless all result data has been collected. We should
actively close the job to avoid resource leak through the
`CloseableIterator#close()` method.
-We can also print the select result to client console through the
`TableResult.print()` method. The result data in `TableResult` can be accessed
only once. Thus, `collect()` and `print()` must not be called after each other.
+`TableResult.collect()` 和
`TableResult.print()`在不同的checkpointing设置下有一些差异.(流式作业开启checkpointing, 参见
\[checkpointing 设置]\({{< ref "docs/deployment/config" >}}#checkpointing)).
-`TableResult.collect()` and `TableResult.print()` have slightly different
behaviors under different checkpointing settings (to enable checkpointing for a
streaming job, see [checkpointing config]({{< ref "docs/deployment/config"
>}}#checkpointing)).
-* For batch jobs or streaming jobs without checkpointing,
`TableResult.collect()` and `TableResult.print()` have neither exactly-once nor
at-least-once guarantee. Query results are immediately accessible by the
clients once they're produced, but exceptions will be thrown when the job fails
and restarts.
-* For streaming jobs with exactly-once checkpointing, `TableResult.collect()`
and `TableResult.print()` guarantee an end-to-end exactly-once record delivery.
A result will be accessible by clients only after its corresponding checkpoint
completes.
-* For streaming jobs with at-least-once checkpointing, `TableResult.collect()`
and `TableResult.print()` guarantee an end-to-end at-least-once record
delivery. Query results are immediately accessible by the clients once they're
produced, but it is possible for the same result to be delivered multiple times.
+* 对于没有checkpointing的批式或流式作业, `TableResult.collect()` 和 `TableResult.print()`
既不保证精确一次(exactly-once)也不保证至少一次(at-least-once)
.查询结果一旦产生,客户端可以立即访问,但是,作业失败或重启将抛出异常.
Review Comment:
建议使用中文标点,并且在中文与英文之间添加一个空格,以提高阅读体验。比如:
```
* 对于没有 checkpointing 的批式或流式作业,`TableResult.collect()` 和
`TableResult.print()`
既不保证精确一次(exactly-once)也不保证至少一次(at-least-once)。查询结果一旦产生,客户端可以立即访问,但是作业失败或重启时将会抛出异常。
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] healchow commented on a diff in pull request #21726: [FLINK-30748][docs]Translate "Overview" page of "Querys" into Chinese
healchow commented on code in PR #21726:
URL: https://github.com/apache/flink/pull/21726#discussion_r1081454537
##
docs/content.zh/docs/dev/table/sql/queries/overview.md:
##
@@ -155,110 +158,116 @@ sink_descriptor =
TableDescriptor.for_connector("filesystem")
t_env.create_temporary_table("RubberOrders", sink_descriptor)
-# run an INSERT SQL on the Table and emit the result to the TableSink
+# 在表上执行一个 INSERT SQL ,SQL结果写入到TableSink
table_env \
.execute_sql("INSERT INTO RubberOrders SELECT product, amount FROM Orders
WHERE product LIKE '%Rubber%'")
```
+
{{< /tab >}}
{{< /tabs >}}
{{< top >}}
-## Execute a Query
+## 执行查询
+通过`TableEnvironment.executeSql()`方法可以执行`SELECT`或`VALUES`语句,并把结果收集到本地.它将`SELECT`语句(或`VALUES`语句)的结果作为`TableResult`返回.和`SELECT`语句相似,`Table.execute()`方法可以执行`Table`对象,并把结果收集到本地客户端.
+`TableResult.collect()`方法返回一个可关闭的行迭代器(row
iterator).除非所有结果数据都被收集完成了,否则`SELECT`作业不会停止,所以应该积极使用`CloseableIterator#close()`方法关闭作业,以防止资源泄露.
`TableResult.print()`可以打印`SELECT`的结果到客户端的控制台中.`TableResult`上的结果数据只能被访问一次.因此`collect()`和`print()`只能二选一.
-A SELECT statement or a VALUES statement can be executed to collect the
content to local through the `TableEnvironment.executeSql()` method. The method
returns the result of the SELECT statement (or the VALUES statement) as a
`TableResult`. Similar to a SELECT statement, a `Table` object can be executed
using the `Table.execute()` method to collect the content of the query to the
local client.
-`TableResult.collect()` method returns a closeable row iterator. The select
job will not be finished unless all result data has been collected. We should
actively close the job to avoid resource leak through the
`CloseableIterator#close()` method.
-We can also print the select result to client console through the
`TableResult.print()` method. The result data in `TableResult` can be accessed
only once. Thus, `collect()` and `print()` must not be called after each other.
+`TableResult.collect()` 和
`TableResult.print()`在不同的checkpointing设置下有一些差异.(流式作业开启checkpointing, 参见
\[checkpointing 设置]\({{< ref "docs/deployment/config" >}}#checkpointing)).
-`TableResult.collect()` and `TableResult.print()` have slightly different
behaviors under different checkpointing settings (to enable checkpointing for a
streaming job, see [checkpointing config]({{< ref "docs/deployment/config"
>}}#checkpointing)).
-* For batch jobs or streaming jobs without checkpointing,
`TableResult.collect()` and `TableResult.print()` have neither exactly-once nor
at-least-once guarantee. Query results are immediately accessible by the
clients once they're produced, but exceptions will be thrown when the job fails
and restarts.
-* For streaming jobs with exactly-once checkpointing, `TableResult.collect()`
and `TableResult.print()` guarantee an end-to-end exactly-once record delivery.
A result will be accessible by clients only after its corresponding checkpoint
completes.
-* For streaming jobs with at-least-once checkpointing, `TableResult.collect()`
and `TableResult.print()` guarantee an end-to-end at-least-once record
delivery. Query results are immediately accessible by the clients once they're
produced, but it is possible for the same result to be delivered multiple times.
+* 对于没有checkpointing的批式或流式作业, `TableResult.collect()` 和 `TableResult.print()`
既不保证精确一次(exactly-once)也不保证至少一次(at-least-once)
.查询结果一旦产生,客户端可以立即访问,但是,作业失败或重启将抛出异常.
Review Comment:
建议使用中文标点,并且在中文与英文之间添加一个空格,以提高阅读体验。
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] healchow commented on a diff in pull request #21726: [FLINK-30748][docs]Translate "Overview" page of "Querys" into Chinese
healchow commented on code in PR #21726:
URL: https://github.com/apache/flink/pull/21726#discussion_r1081453260
##
docs/content.zh/docs/dev/table/sql/queries/overview.md:
##
@@ -155,110 +158,116 @@ sink_descriptor =
TableDescriptor.for_connector("filesystem")
t_env.create_temporary_table("RubberOrders", sink_descriptor)
-# run an INSERT SQL on the Table and emit the result to the TableSink
+# 在表上执行一个 INSERT SQL ,SQL结果写入到TableSink
table_env \
.execute_sql("INSERT INTO RubberOrders SELECT product, amount FROM Orders
WHERE product LIKE '%Rubber%'")
```
+
{{< /tab >}}
{{< /tabs >}}
{{< top >}}
-## Execute a Query
+## 执行查询
+通过`TableEnvironment.executeSql()`方法可以执行`SELECT`或`VALUES`语句,并把结果收集到本地.它将`SELECT`语句(或`VALUES`语句)的结果作为`TableResult`返回.和`SELECT`语句相似,`Table.execute()`方法可以执行`Table`对象,并把结果收集到本地客户端.
+`TableResult.collect()`方法返回一个可关闭的行迭代器(row
iterator).除非所有结果数据都被收集完成了,否则`SELECT`作业不会停止,所以应该积极使用`CloseableIterator#close()`方法关闭作业,以防止资源泄露.
`TableResult.print()`可以打印`SELECT`的结果到客户端的控制台中.`TableResult`上的结果数据只能被访问一次.因此`collect()`和`print()`只能二选一.
-A SELECT statement or a VALUES statement can be executed to collect the
content to local through the `TableEnvironment.executeSql()` method. The method
returns the result of the SELECT statement (or the VALUES statement) as a
`TableResult`. Similar to a SELECT statement, a `Table` object can be executed
using the `Table.execute()` method to collect the content of the query to the
local client.
-`TableResult.collect()` method returns a closeable row iterator. The select
job will not be finished unless all result data has been collected. We should
actively close the job to avoid resource leak through the
`CloseableIterator#close()` method.
-We can also print the select result to client console through the
`TableResult.print()` method. The result data in `TableResult` can be accessed
only once. Thus, `collect()` and `print()` must not be called after each other.
+`TableResult.collect()` 和
`TableResult.print()`在不同的checkpointing设置下有一些差异.(流式作业开启checkpointing, 参见
\[checkpointing 设置]\({{< ref "docs/deployment/config" >}}#checkpointing)).
-`TableResult.collect()` and `TableResult.print()` have slightly different
behaviors under different checkpointing settings (to enable checkpointing for a
streaming job, see [checkpointing config]({{< ref "docs/deployment/config"
>}}#checkpointing)).
-* For batch jobs or streaming jobs without checkpointing,
`TableResult.collect()` and `TableResult.print()` have neither exactly-once nor
at-least-once guarantee. Query results are immediately accessible by the
clients once they're produced, but exceptions will be thrown when the job fails
and restarts.
-* For streaming jobs with exactly-once checkpointing, `TableResult.collect()`
and `TableResult.print()` guarantee an end-to-end exactly-once record delivery.
A result will be accessible by clients only after its corresponding checkpoint
completes.
-* For streaming jobs with at-least-once checkpointing, `TableResult.collect()`
and `TableResult.print()` guarantee an end-to-end at-least-once record
delivery. Query results are immediately accessible by the clients once they're
produced, but it is possible for the same result to be delivered multiple times.
+* 对于没有checkpointing的批式或流式作业, `TableResult.collect()` 和 `TableResult.print()`
既不保证精确一次(exactly-once)也不保证至少一次(at-least-once)
.查询结果一旦产生,客户端可以立即访问,但是,作业失败或重启将抛出异常.
+* 对于checkpointing设置为精确一次(exactly-once)的流式作业, `TableResult.collect()` 和
`TableResult.print()` 保证端到端(end-to-end)的数据只传递一次.相应的checkpoint完成后,客户端才能访问结果.
+* 对于checkpointing设置为至少一次(at-least-once)的流式作业, `TableResult.collect()` 和
`TableResult.print()` 保证端到端(end-to-end)的数据至少传递一次.
查询结果一旦产生,客户端可以立即访问,但是可能会有同一条数据出现多次的情况.
{{< tabs "88a003e1-16ea-43cc-9d42-d43ef1351e53" >}}
{{< tab "Java" >}}
+
```java
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
tableEnv.executeSql("CREATE TABLE Orders (`user` BIGINT, product STRING,
amount INT) WITH (...)");
-// execute SELECT statement
+// 执行`SELECT`语句
TableResult tableResult1 = tableEnv.executeSql("SELECT * FROM Orders");
-// use try-with-resources statement to make sure the iterator will be closed
automatically
+// 使用 try-with-resources 确保iterator会自动关闭
try (CloseableIterator it = tableResult1.collect()) {
while(it.hasNext()) {
Row row = it.next();
-// handle row
+// 处理数据
}
}
-// execute Table
+// 执行表
TableResult tableResult2 = tableEnv.sqlQuery("SELECT * FROM Orders").execute();
tableResult2.print();
```
+
{{< /tab >}}
{{< tab "Scala" >}}
+
```scala
val env = StreamExecutionEnvironment.getExecutionEnvironment()
val tableEnv = StreamTableEnvironment.create(env, settings)
-// enable checkpointing
+// 启用 checkpointing
tableEnv.getConfig
.set(ExecutionCheckpointingOptions.CHECKPOINTING_MODE,
[GitHub] [flink] zentol merged pull request #21723: [FLINK-30749][security][runtime] Fix delegation token provider enabled flag documentation
zentol merged PR #21723: URL: https://github.com/apache/flink/pull/21723 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-connector-cassandra] echauchot commented on pull request #3: [FLINK-26822] Add Cassandra Source
echauchot commented on PR #3: URL: https://github.com/apache/flink-connector-cassandra/pull/3#issuecomment-1397142509 > > I did not author the RingRange and SplitsGenerator classes. I got them from the Apache Beam Cassandra connector. > > If you're copying stuff from other projects it please add some notice/attribution to the files and update the Flink source notice accordingly. ah yes I forgot this Flink guideline. I don't think it is an ASF rule but fair enough, I'll add it to the javadoc and notice. > > > Back in 2017 I coded a [splitter for Cassandra Beam connector](https://github.com/echauchot/beam/blob/bfa33b85b6b310556ffa5c44c99bef50575b2c56/sdks/java/io/cassandra/src/main/java/org/apache/beam/sdk/io/cassandra/CassandraIO.java#L346) that works [with tokens](https://github.com/echauchot/beam/blob/BEAM-245-CassandraIO/sdks/java/io/cassandra/src/main/java/org/apache/beam/sdk/io/cassandra/DataSizeEstimates.java) also but that is simpler and supports all the Cassandra partitionners. Would you prefer that we use this other approach ? > > Not sure? Why didn't it make it into Beam? Do you know why the Beam code is written the way it is? Actually, another splitting approach was opted in by the reviewer in 2017. But short after there was another author who changed the splitting to something similar to my 2017 token based code. So when I thought about coding the split for Flink connector I decided to take the version of the code that was merged to Beam master. But it is true that it is over complicated, redundant and not supporting the non-default Cassandra partitioner. The approach I had in 2017 was the same as the Cassandra Spark connector written by datastax (tokens + cassandra size estimates statistics). So I think I'll try to reuse this code, migrate it to Flink and update it to the latest Cassandra version and push it in this PR. WDYT ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] LadyForest commented on pull request #21717: [FLINK-29945][sql-client] Supports to submit SQL to a embedded SQL Ga…
LadyForest commented on PR #21717: URL: https://github.com/apache/flink/pull/21717#issuecomment-1397141360 P.S. Wrong cmd will get CLI blocked forever. The stacktrace is attached ```text Flink SQL> desc extended foo; Exception in thread "main" org.apache.flink.table.client.SqlClientException: Could not read from command line. at org.apache.flink.table.client.cli.CliClient.getAndExecuteStatements(CliClient.java:221) at org.apache.flink.table.client.cli.CliClient.executeInteractive(CliClient.java:186) at org.apache.flink.table.client.cli.CliClient.executeInInteractiveMode(CliClient.java:132) at org.apache.flink.table.client.SqlClient.openCli(SqlClient.java:157) at org.apache.flink.table.client.SqlClient.start(SqlClient.java:102) at org.apache.flink.table.client.SqlClient.startClient(SqlClient.java:193) at org.apache.flink.table.client.SqlClient.main(SqlClient.java:167) Caused by: org.apache.flink.table.client.gateway.SqlExecutionException: Failed to get response. at org.apache.flink.table.client.gateway.ExecutorImpl.getResponse(ExecutorImpl.java:325) at org.apache.flink.table.client.gateway.ExecutorImpl.getSessionConfig(ExecutorImpl.java:184) at org.apache.flink.table.client.cli.CliClient.printExecutionException(CliClient.java:408) at org.apache.flink.table.client.cli.CliClient.executeStatement(CliClient.java:272) at org.apache.flink.table.client.cli.CliClient.getAndExecuteStatements(CliClient.java:206) ... 6 more Caused by: org.apache.flink.runtime.rest.util.RestClientException: [org.apache.flink.runtime.rest.handler.RestHandlerException: Failed to getSessionConfig. at org.apache.flink.table.gateway.rest.handler.session.GetSessionConfigHandler.handleRequest(GetSessionConfigHandler.java:66) at org.apache.flink.table.gateway.rest.handler.AbstractSqlGatewayRestHandler.respondToRequest(AbstractSqlGatewayRestHandler.java:84) at org.apache.flink.table.gateway.rest.handler.AbstractSqlGatewayRestHandler.respondToRequest(AbstractSqlGatewayRestHandler.java:52) at org.apache.flink.runtime.rest.handler.AbstractHandler.respondAsLeader(AbstractHandler.java:196) at org.apache.flink.runtime.rest.handler.LeaderRetrievalHandler.lambda$channelRead0$0(LeaderRetrievalHandler.java:83) at java.util.Optional.ifPresent(Optional.java:159) at org.apache.flink.util.OptionalConsumer.ifPresent(OptionalConsumer.java:45) at org.apache.flink.runtime.rest.handler.LeaderRetrievalHandler.channelRead0(LeaderRetrievalHandler.java:80) at org.apache.flink.runtime.rest.handler.LeaderRetrievalHandler.channelRead0(LeaderRetrievalHandler.java:49) at org.apache.flink.shaded.netty4.io.netty.channel.SimpleChannelInboundHandler.channelRead(SimpleChannelInboundHandler.java:99) at org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:379) at org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:365) at org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:357) at org.apache.flink.runtime.rest.handler.router.RouterHandler.routed(RouterHandler.java:115) at org.apache.flink.runtime.rest.handler.router.RouterHandler.channelRead0(RouterHandler.java:94) at org.apache.flink.runtime.rest.handler.router.RouterHandler.channelRead0(RouterHandler.java:55) at org.apache.flink.shaded.netty4.io.netty.channel.SimpleChannelInboundHandler.channelRead(SimpleChannelInboundHandler.java:99) at org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:379) at org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:365) at org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:357) at org.apache.flink.shaded.netty4.io.netty.handler.codec.MessageToMessageDecoder.channelRead(MessageToMessageDecoder.java:103) at org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:379) at org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:365) at org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:357) at
[GitHub] [flink] LadyForest commented on a diff in pull request #21717: [FLINK-29945][sql-client] Supports to submit SQL to a embedded SQL Ga…
LadyForest commented on code in PR #21717:
URL: https://github.com/apache/flink/pull/21717#discussion_r1081032613
##
flink-table/flink-sql-client/src/main/java/org/apache/flink/table/client/cli/parser/SqlCommandParserImpl.java:
##
@@ -18,35 +18,136 @@
package org.apache.flink.table.client.cli.parser;
-import org.apache.flink.table.api.SqlParserException;
-import org.apache.flink.table.client.gateway.Executor;
+import org.apache.flink.sql.parser.impl.FlinkSqlParserImplTokenManager;
+import org.apache.flink.sql.parser.impl.SimpleCharStream;
+import org.apache.flink.sql.parser.impl.Token;
+import org.apache.flink.table.api.SqlParserEOFException;
import org.apache.flink.table.client.gateway.SqlExecutionException;
-import org.apache.flink.table.operations.Operation;
+import java.io.StringReader;
+import java.util.Iterator;
import java.util.Optional;
-/** SqlCommandParserImpl wrappers an {@link Executor} supports parse a
statement to an Operation. */
-public class SqlCommandParserImpl implements SqlCommandParser {
-private final Executor executor;
+import static org.apache.flink.sql.parser.impl.FlinkSqlParserImplConstants.EOF;
+import static
org.apache.flink.sql.parser.impl.FlinkSqlParserImplConstants.IDENTIFIER;
+import static
org.apache.flink.sql.parser.impl.FlinkSqlParserImplConstants.SEMICOLON;
-public SqlCommandParserImpl(Executor executor) {
-this.executor = executor;
-}
+/**
+ * The {@link SqlCommandParserImpl} uses {@link
FlinkSqlParserImplTokenManager} to do lexical
+ * analysis. It cannot recognize special hive keywords yet because Hive has a
slightly different
+ * vocabulary compared to Flink's, which causes the The {@link
SqlCommandParserImpl}
Review Comment:
Nit: remove duplicated "The"
##
flink-table/flink-sql-client/src/main/java/org/apache/flink/table/client/cli/parser/SqlCommandParserImpl.java:
##
@@ -18,35 +18,136 @@
package org.apache.flink.table.client.cli.parser;
-import org.apache.flink.table.api.SqlParserException;
-import org.apache.flink.table.client.gateway.Executor;
+import org.apache.flink.sql.parser.impl.FlinkSqlParserImplTokenManager;
+import org.apache.flink.sql.parser.impl.SimpleCharStream;
+import org.apache.flink.sql.parser.impl.Token;
+import org.apache.flink.table.api.SqlParserEOFException;
import org.apache.flink.table.client.gateway.SqlExecutionException;
-import org.apache.flink.table.operations.Operation;
+import java.io.StringReader;
+import java.util.Iterator;
import java.util.Optional;
-/** SqlCommandParserImpl wrappers an {@link Executor} supports parse a
statement to an Operation. */
-public class SqlCommandParserImpl implements SqlCommandParser {
-private final Executor executor;
+import static org.apache.flink.sql.parser.impl.FlinkSqlParserImplConstants.EOF;
+import static
org.apache.flink.sql.parser.impl.FlinkSqlParserImplConstants.IDENTIFIER;
+import static
org.apache.flink.sql.parser.impl.FlinkSqlParserImplConstants.SEMICOLON;
-public SqlCommandParserImpl(Executor executor) {
-this.executor = executor;
-}
+/**
+ * The {@link SqlCommandParserImpl} uses {@link
FlinkSqlParserImplTokenManager} to do lexical
+ * analysis. It cannot recognize special hive keywords yet because Hive has a
slightly different
+ * vocabulary compared to Flink's, which causes the The {@link
SqlCommandParserImpl}
+ * misunderstanding some Hive's keywords to IDENTIFIER. But the ClientParser
is only responsible to
+ * check whether the statement is completed or not and only cares about a few
statements. So it's
+ * acceptable to tolerate the inaccuracy here.
+ */
+public class SqlCommandParserImpl implements SqlCommandParser {
-@Override
-public Optional parseCommand(String stmt) throws
SqlParserException {
+public Optional parseStatement(String statement) throws
SqlExecutionException {
// normalize
-stmt = stmt.trim();
+statement = statement.trim();
// meet empty statement, e.g ";\n"
-if (stmt.isEmpty() || stmt.equals(";")) {
+if (statement.isEmpty() || statement.equals(";")) {
return Optional.empty();
+} else {
+return Optional.of(getCommand(new
TokenIterator(statement.trim(;
Review Comment:
Nit: no need to `trim` again?
##
flink-table/flink-sql-client/src/test/java/org/apache/flink/table/client/cli/parser/SqlCommandParserImplTest.java:
##
@@ -28,105 +28,99 @@
import java.util.Arrays;
import java.util.List;
-import java.util.Optional;
import static org.apache.flink.core.testutils.FlinkAssertions.anyCauseMatches;
-import static
org.apache.flink.table.client.cli.parser.StatementType.BEGIN_STATEMENT_SET;
-import static org.apache.flink.table.client.cli.parser.StatementType.CLEAR;
-import static org.apache.flink.table.client.cli.parser.StatementType.END;
-import static org.apache.flink.table.client.cli.parser.StatementType.EXPLAIN;
-import
[GitHub] [flink] luoyuxia commented on a diff in pull request #21703: [FLINK-29880][hive] Introduce auto compaction for Hive sink in batch mode
luoyuxia commented on code in PR #21703:
URL: https://github.com/apache/flink/pull/21703#discussion_r1081412503
##
docs/content/docs/connectors/table/hive/hive_read_write.md:
##
@@ -558,6 +558,70 @@ use more threads to speed the gathering.
**NOTE:**
- Only `BATCH` mode supports to auto gather statistic, `STREAMING` mode
doesn't support it yet.
+### File Compaction
+
+The Hive sink also supports file compactions, which allows applications to
reduce the number of files generated while writing into Hive.
+
+ Stream Mode
+
+In stream mode, the behavior is same to `FileSystem` sink. Please refer to
[File Compaction]({{< ref "docs/connectors/table/filesystem"
>}}#file-compaction) for more details.
+
+ Batch Mode
+
+When it's in batch mode and auto compaction is enabled, after finishing
writing files, Flink will calculate the average size of written files for each
partition. And if the average size is less than the
+threshold configured, Flink will then try to compact these files to files with
a target size. The following is the table's options for file compactions.
Review Comment:
I accpet it except that I still think we should use `a target size` instead
of `the target size`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] luoyuxia commented on a diff in pull request #21601: [FLINK-29720][hive] Supports native avg function for hive dialect
luoyuxia commented on code in PR #21601:
URL: https://github.com/apache/flink/pull/21601#discussion_r1081360275
##
docs/content.zh/docs/connectors/table/hive/hive_functions.md:
##
@@ -73,6 +73,31 @@ Some Hive built-in functions in older versions have [thread
safety issues](https
We recommend users patch their own Hive to fix them.
{{< /hint >}}
+## Use Native Hive Aggregate Functions via HiveModule
+
+For Hive's built-in aggregation function, Flink currently uses sort-based
aggregation strategy. Compared to hash-based aggregation strategy, the
performance is one to two times worse, so from Flink 1.17, we have implemented
some of Hive's aggregation functions natively in Flink.
+These functions will use the hash-agg strategy to improve performance.
Currently, only five functions are supported, namely sum/count/avg/min/max, and
more aggregation functions will be supported in the future.
+Users can use the native aggregation function by turning on the option
`table.exec.hive.native-agg-function.enabled`, which brings significant
performance improvement to the job.
Review Comment:
I think we also should remind user that when
`table.exec.hive.native-agg-function.enabled` = `true`, there'll be some
incompatibility issue, e.g, some dataypes may not be supported in native
implementation.
##
docs/content.zh/docs/connectors/table/hive/hive_functions.md:
##
@@ -73,6 +73,31 @@ Some Hive built-in functions in older versions have [thread
safety issues](https
We recommend users patch their own Hive to fix them.
{{< /hint >}}
+## Use Native Hive Aggregate Functions via HiveModule
Review Comment:
May be we can add a link for `HiveModule` like
[HiveModule]({{< ref "docs/dev/table/modules" >}}#hivemodule)
##
docs/content.zh/docs/connectors/table/hive/hive_functions.md:
##
@@ -73,6 +73,31 @@ Some Hive built-in functions in older versions have [thread
safety issues](https
We recommend users patch their own Hive to fix them.
{{< /hint >}}
+## Use Native Hive Aggregate Functions via HiveModule
+
+For Hive's built-in aggregation function, Flink currently uses sort-based
aggregation strategy. Compared to hash-based aggregation strategy, the
performance is one to two times worse, so from Flink 1.17, we have implemented
some of Hive's aggregation functions natively in Flink.
+These functions will use the hash-agg strategy to improve performance.
Currently, only five functions are supported, namely sum/count/avg/min/max, and
more aggregation functions will be supported in the future.
+Users can use the native aggregation function by turning on the option
`table.exec.hive.native-agg-function.enabled`, which brings significant
performance improvement to the job.
+
+
+
+
+Key
+Default
+Type
+Description
+
+
+
+
+table.exec.hive.native-agg-function.enabled
+false
+Boolean
+Enabling native aggregate function for hive dialect to use
hash-agg strategy that can improve the aggregation performance. This is a
job-level option, user can enable it per-job.
Review Comment:
Maynot precise. Not only for hive dialect, but also for HiveModule is
loaded.
```suggestion
Enabling to use native aggregate function to use hash-agg
strategy which can improve the aggregation performance after loading
HiveModule. This is a job-level option, user can enable it per-job.
```
##
docs/content.zh/docs/connectors/table/hive/hive_functions.md:
##
@@ -73,6 +73,31 @@ Some Hive built-in functions in older versions have [thread
safety issues](https
We recommend users patch their own Hive to fix them.
{{< /hint >}}
+## Use Native Hive Aggregate Functions via HiveModule
Review Comment:
If HiveModule is loaded with a higher priority than CoreMoudle, Flink will
try to use the Hive built-in function first. And then for Hive built-in
aggregation function, Flink will use sort-based aggregation strategy.
So, I think the title `Use Native Hive Aggregate Functions via HiveModule`
is not correct.
May be can be `Use Native Hive Aggregate Functions`. And add some
explaination about it.
May be we can put the sentence
`
If HiveModule is loaded with a higher priority than CoreMoudle, Flink will
try to use the Hive built-in function first. And then for Hive built-in
aggregation functio
` in here.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org