On 01/07/22(Fri) 07:13, Sebastien Marie wrote:
> On Mon, Jun 27, 2022 at 06:29:55PM +0200, Martin Pieuchot wrote:
> > On 27/06/22(Mon) 18:04, Caspar Schutijser wrote:
> > > On Sun, Jun 26, 2022 at 10:03:59PM +0200, Martin Pieuchot wrote:
> > > > On 26/06/22(Sun) 20:36, Caspar Schutijser wrote:
> > > > > A laptop of mine (dmesg below) frequently hangs. After some bisecting
> > > > > and extensive testing I think I found the commit that causes this:
> > > > > mpi@'s
> > > > > "Always acquire the `vmobjlock' before incrementing an object's
> > > > > reference."
> > > > > commit from 2022-04-28.
> > > > >
> > > > > My definition of "the system hangs":
> > > > > * Display is frozen
> > > > > * Switching to ttyC0 using Ctrl+Alt+F1 doesn't do anything
> > > > > * System does not respond to keyboard or mouse input
> > > > > * Pressing the power button for 1-2 seconds doesn't achieve anything
> > > > > (usually this initiates a system shutdown)
> > > > > * And also the fan starts spinning
> > > > >
> > > > > The system sometimes hangs very soon after booting the system, I've
> > > > > seen it happen once while I was typing my username in xenodm to log
> > > > > in.
> > > > > But sometimes it takes a couple of hours.
> > > > >
> > > > > For some reason I put
> > > > > "@reboot while sleep 1 ; do sync ; done"
> > > > > in my crontab and it *seems* (I'm not sure) that the hangs occur more
> > > > > frequently this way. Not sure if that is useful information.
> > > > >
> > > > > I don't see similar problems on my other machines.
> > > > >
> > > > > It looks like when the system hangs, it's stuck spinning in the new
> > > > > code that was added in that commit; to confirm that I added some code
> > > > > (see the diff below) to enter ddb if it's spinning there for 10
> > > > > seconds
> > > > > (and then it indeed enters ddb). If my thinking and diff make sense
> > > > > I think that indeed confirms that is the problem.
> > > > >
> > > > > Any tips for debugging this?
> > > >
> > > > I believe I introduced a deadlock. If you can reproduce it could you
> > > > get us the output of `ps' in ddb(4) and the trace of all the active
> > > > processes.
> > > >
> > > > I guess one is waiting for the KERNEL_LOCK() while holding the uobj's
> > > > vmobjlock.
> > >
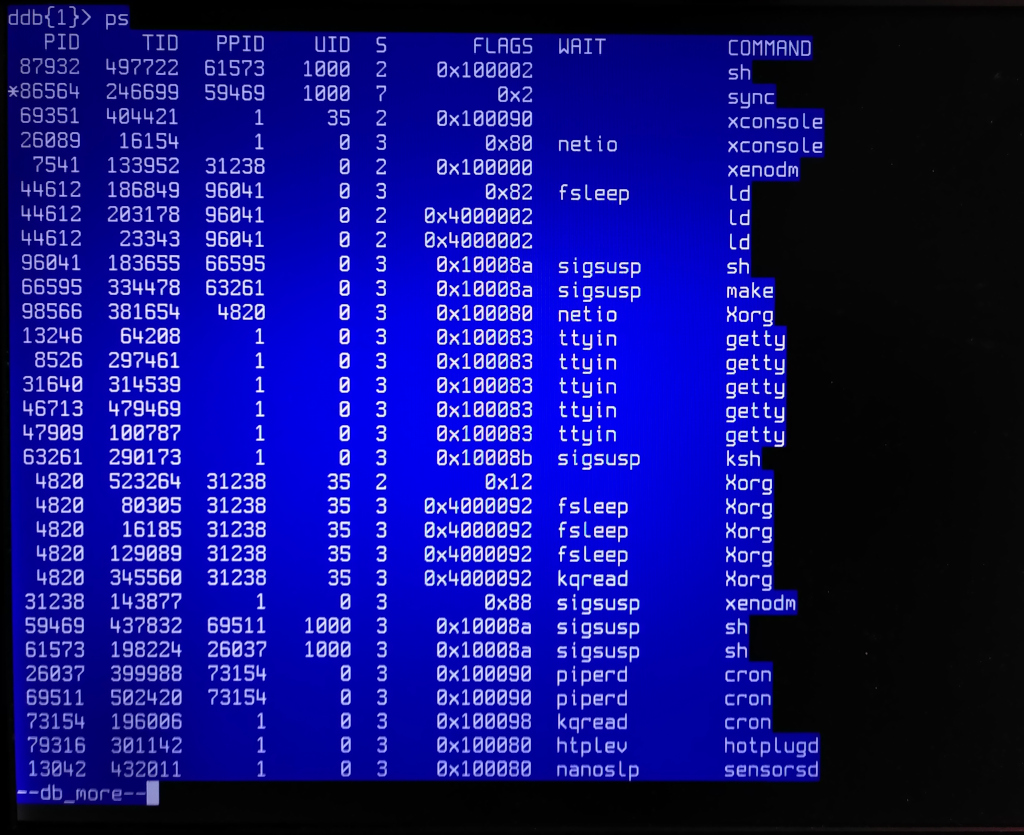
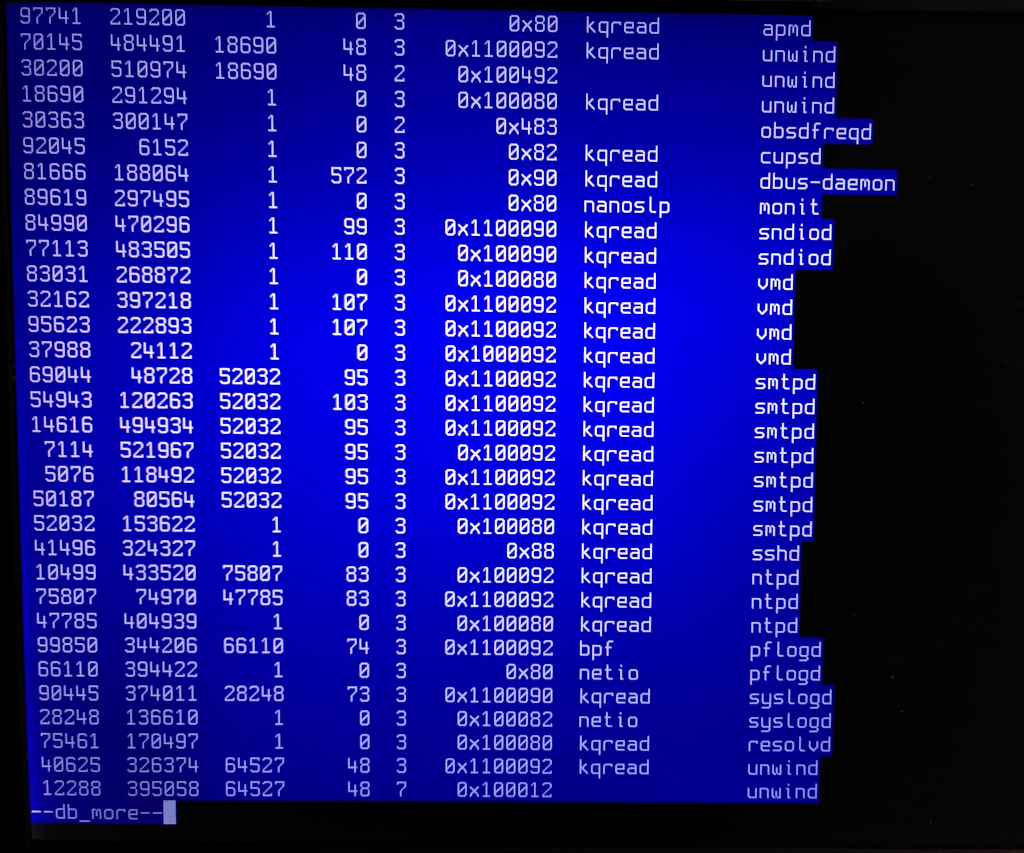
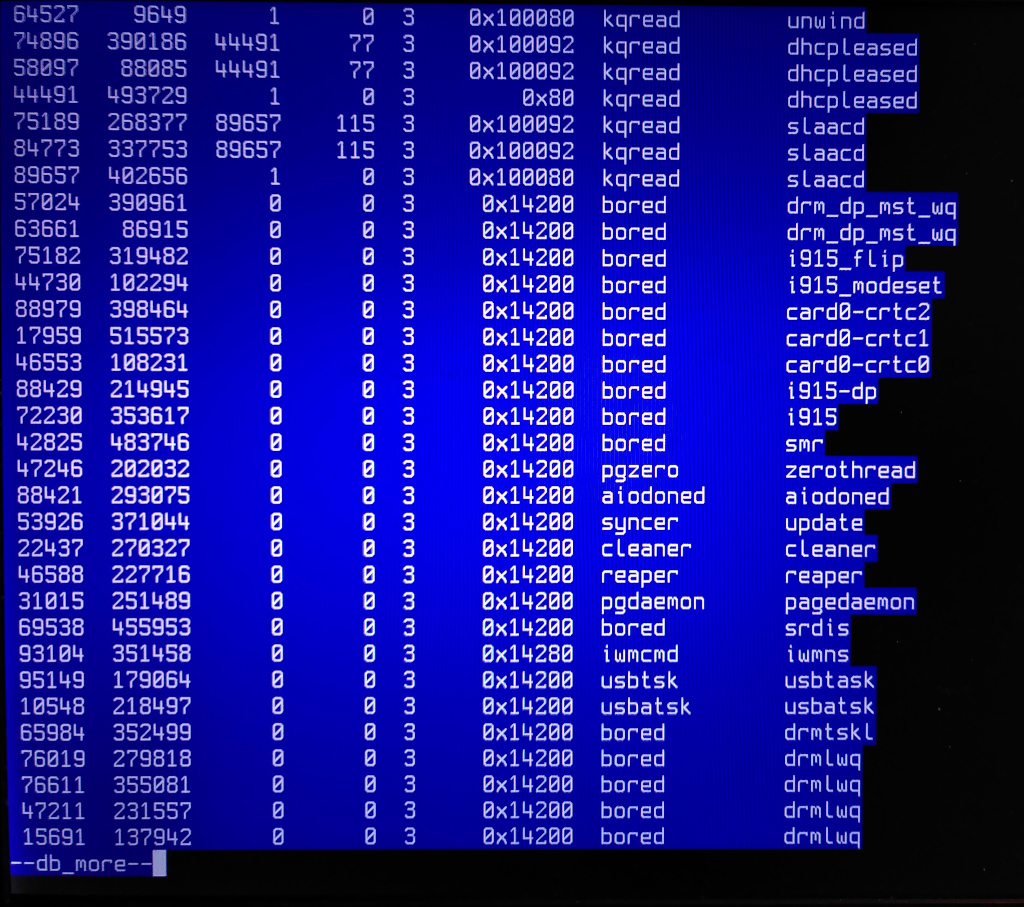
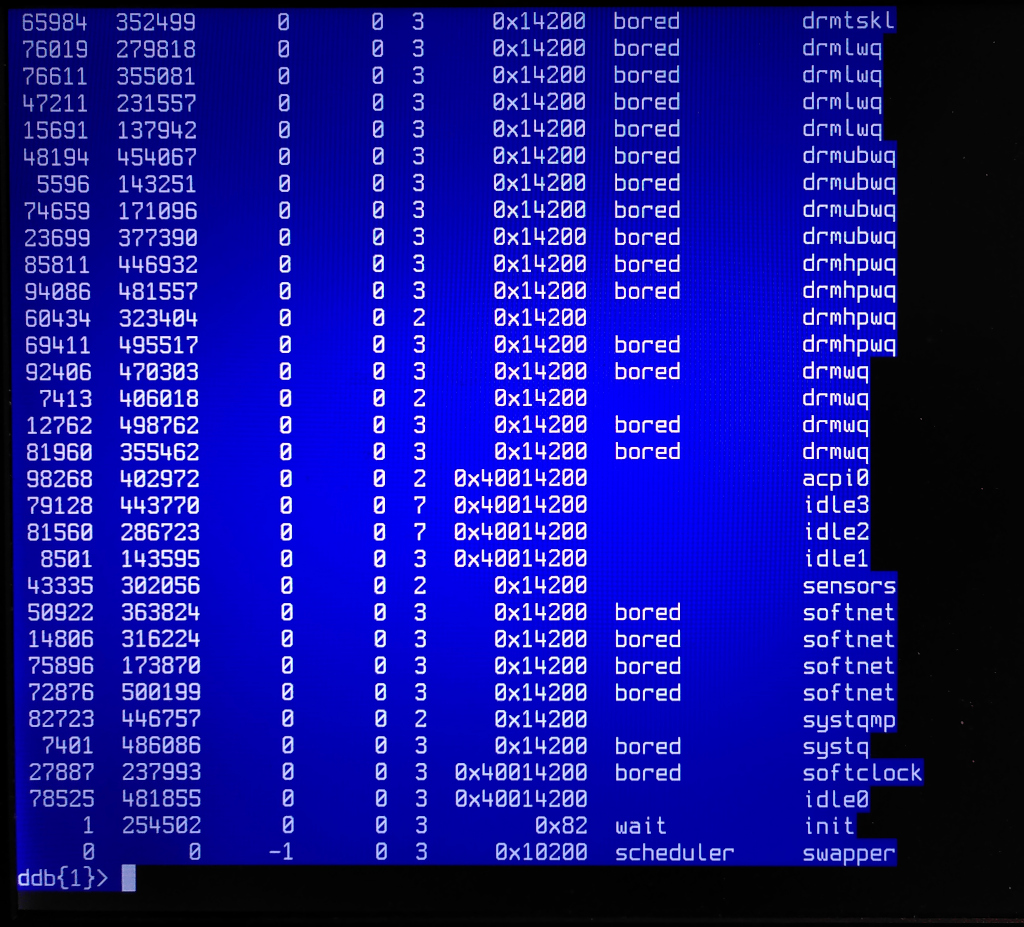
> > > "ps" output (pictures only):
> > > https://temp.schutijser.com/~caspar/2022-06-27-ddb/ps-1.jpg
> > > https://temp.schutijser.com/~caspar/2022-06-27-ddb/ps-2.jpg
> > > https://temp.schutijser.com/~caspar/2022-06-27-ddb/ps-3.jpg
> > > https://temp.schutijser.com/~caspar/2022-06-27-ddb/ps-4.jpg
> > >
> > >
> > > traces of active processes (I hope; if this is not correct I'm happy
> > > to run different commands; pictures and transcription follow):
> > > https://temp.schutijser.com/~caspar/2022-06-27-ddb/trace-1.jpg
> > >
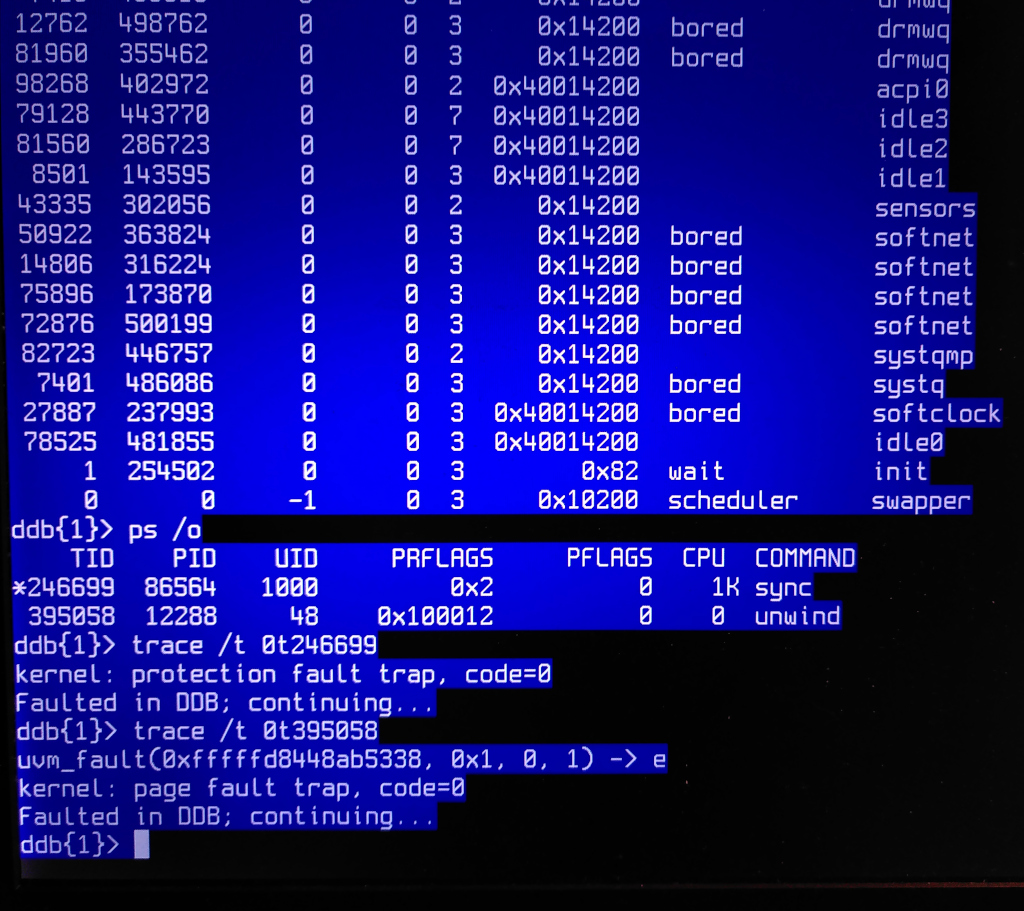
> > > ddb{1}> ps /o
> > > TID PID UID PRFLAGS PFLAGS CPU COMMAND
> > > *246699 86564 1000 0x2 0 1K sync
> > > 395058 12288 48 0x100012 0 0 unwind
> > > ddb{1}> trace /t 0t246699
> > > kernel: protection fault trap, code=0
> > > Faulted in DDB; continuing...
> > > ddb{1}> trace /t 0t395058
> > > uvm_fault(0xfffffd8448ab5338, 0x1, 0, 1) -> e
> > > kernel: page fault trap, code=0
> > > Faulted in DDB; continuing...
> > > ddb{1}>
> >
> > Is it a hang or a panic/fault? Here's a possible fix. The idea is to
> > make the list private to the sync function such that we could sleep on
> > the lock without lock ordering reversal.
> >
> > That means multiple sync could be started in parallel, this should be
> > fine as the objects are refcounted and only the first flush result in
> > I/O.
>
> I think there is one drawback: you can't sleep while iterating on
> LIST_FOREACH(uvn_wlist): if the list is modified while sleeping, on wakeup
> pointers might be changed.
>
> see below.
>
> > Index: uvm/uvm_vnode.c
> > ===================================================================
> > RCS file: /cvs/src/sys/uvm/uvm_vnode.c,v
> > retrieving revision 1.124
> > diff -u -p -r1.124 uvm_vnode.c
> > --- uvm/uvm_vnode.c 3 May 2022 21:20:35 -0000 1.124
> > +++ uvm/uvm_vnode.c 27 Jun 2022 16:21:28 -0000
> > @@ -1444,39 +1437,22 @@ uvm_vnp_setsize(struct vnode *vp, off_t
> > * uvm_vnp_sync: flush all dirty VM pages back to their backing vnodes.
> > *
> > * => called from sys_sync with no VM structures locked
> > - * => only one process can do a sync at a time (because the uvn
> > - * structure only has one queue for sync'ing). we ensure this
> > - * by holding the uvn_sync_lock while the sync is in progress.
> > - * other processes attempting a sync will sleep on this lock
> > - * until we are done.
> > */
> > void
> > uvm_vnp_sync(struct mount *mp)
> > {
> > + SIMPLEQ_HEAD(, uvm_vnode) sync_q;
> > struct uvm_vnode *uvn;
> > struct vnode *vp;
> >
> > - /*
> > - * step 1: ensure we are only ones using the uvn_sync_q by locking
> > - * our lock...
> > - */
> > - rw_enter_write(&uvn_sync_lock);
> > + SIMPLEQ_INIT(&sync_q);
> >
> > - /*
> > - * step 2: build up a simpleq of uvns of interest based on the
> > - * write list. we gain a reference to uvns of interest.
> > - */
> > - SIMPLEQ_INIT(&uvn_sync_q);
> > + KERNEL_ASSERT_LOCKED();
> > LIST_FOREACH(uvn, &uvn_wlist, u_wlist) {
> > vp = uvn->u_vnode;
> > if (mp && vp->v_mount != mp)
> > continue;
> >
> > - /* Spin to ensure `uvn_wlist' isn't modified concurrently. */
> > - while (rw_enter(uvn->u_obj.vmobjlock, RW_WRITE|RW_NOSLEEP)) {
> > - CPU_BUSY_CYCLE();
> > - }
> > -
> > /*
> > * If the vnode is "blocked" it means it must be dying, which
> > * in turn means its in the process of being flushed out so
> > @@ -1485,6 +1461,7 @@ uvm_vnp_sync(struct mount *mp)
> > * note that uvn must already be valid because we found it on
> > * the wlist (this also means it can't be ALOCK'd).
> > */
> > + rw_enter(uvn->u_obj.vmobjlock, RW_WRITE);
>
> using rw_enter(9) without RW_NOSLEEP might introduce a sleeping-point (if the
> lock is already taken).
>
> the previous construct was using a busy cycle to avoid the sleep (but I think
> it
> is also one reason of the deadlock: no progess was possible for others).
>
> a possible construct could be:
>
> for (;;) {
> LIST_FOREACH(uvn, &uvn_wlist, u_wlist) {
> vp = uvn->u_vnode;
> if (mp && vp->v_mount != mp)
> continue;
>
> if (rw_enter(uvn->u_obj.vmobjlock, RW_WRITE|RW_NOSLEEP)
> != 0)
> /* ignore locked uvn for now */
> continue;
>
> /* ... */
> }
>
> /* no more uvn in uvn_wlist */
> if (LIST_EMPTY(&uvn_wlist))
> break;
>
> /* there are still uvn, let's others make progress */
> sched_yield();
> }
>
>
> the loop will process all unlocked uvn, sleep only at end of the loop, and
> restart the uvn_wlist processing.
This might have drawbacks. We could endup synching vnodes forever. I'd
like to start reverting the chunk that causes a deadlock then see how we
can fix it properly. Do you agree?
Index: uvm/uvm_vnode.c
===================================================================
RCS file: /cvs/src/sys/uvm/uvm_vnode.c,v
retrieving revision 1.124
diff -u -p -r1.124 uvm_vnode.c
--- uvm/uvm_vnode.c 3 May 2022 21:20:35 -0000 1.124
+++ uvm/uvm_vnode.c 4 Jul 2022 10:47:27 -0000
@@ -1472,11 +1472,6 @@ uvm_vnp_sync(struct mount *mp)
if (mp && vp->v_mount != mp)
continue;
- /* Spin to ensure `uvn_wlist' isn't modified concurrently. */
- while (rw_enter(uvn->u_obj.vmobjlock, RW_WRITE|RW_NOSLEEP)) {
- CPU_BUSY_CYCLE();
- }
-
/*
* If the vnode is "blocked" it means it must be dying, which
* in turn means its in the process of being flushed out so
@@ -1485,10 +1480,8 @@ uvm_vnp_sync(struct mount *mp)
* note that uvn must already be valid because we found it on
* the wlist (this also means it can't be ALOCK'd).
*/
- if ((uvn->u_flags & UVM_VNODE_BLOCKED) != 0) {
- rw_exit(uvn->u_obj.vmobjlock);
+ if ((uvn->u_flags & UVM_VNODE_BLOCKED) != 0)
continue;
- }
/*
* gain reference. watch out for persisting uvns (need to
@@ -1497,7 +1490,6 @@ uvm_vnp_sync(struct mount *mp)
if (uvn->u_obj.uo_refs == 0)
vref(vp);
uvn->u_obj.uo_refs++;
- rw_exit(uvn->u_obj.vmobjlock);
SIMPLEQ_INSERT_HEAD(&uvn_sync_q, uvn, u_syncq);
}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}