Thanks everyone for your replies. I sincerely appreciate it. We are testing with different pg_num and filestore_split_multiple settings. Early indications are .... well not great. Regardless it is nice to understand the symptoms better so we try to design around it.
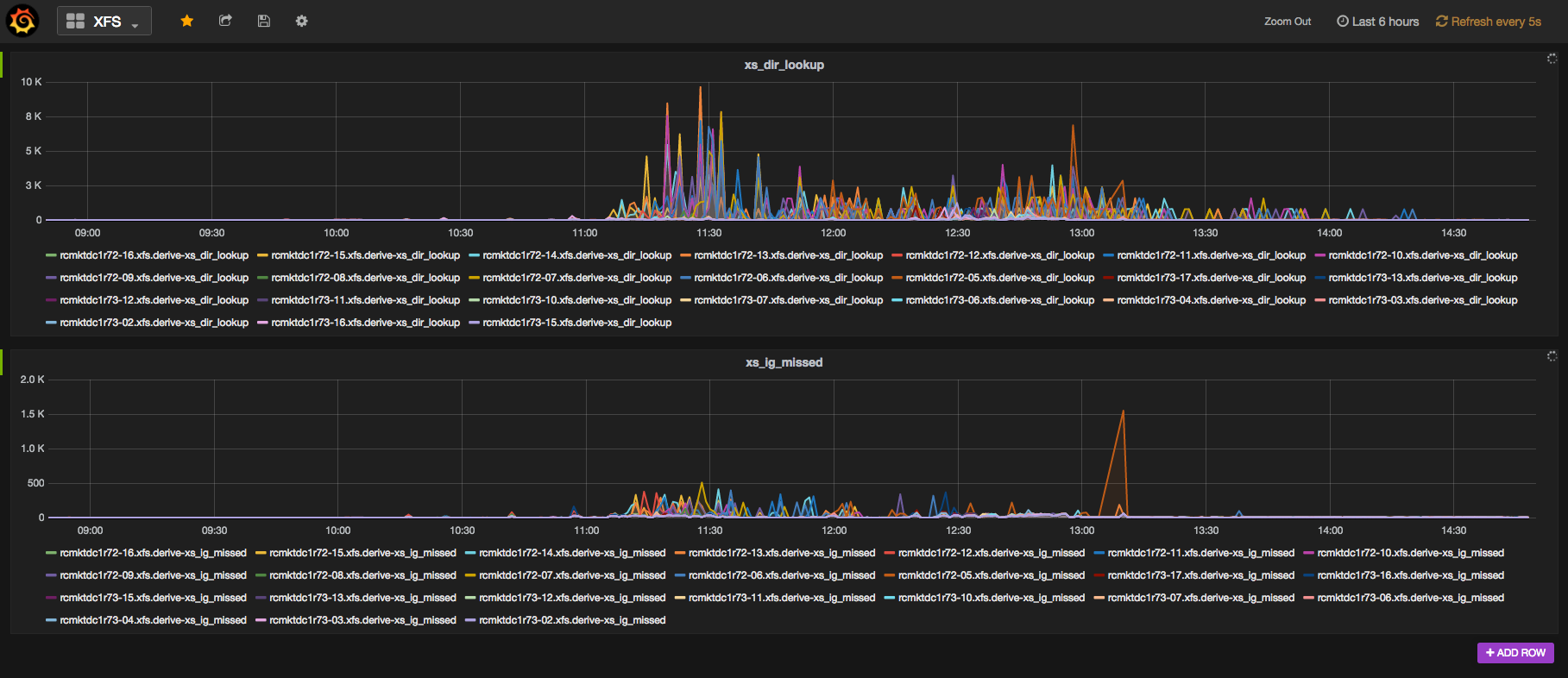
Best Regards, Wade On Mon, Jun 20, 2016 at 2:32 AM Blair Bethwaite <[email protected]> wrote: > On 20 June 2016 at 09:21, Blair Bethwaite <[email protected]> > wrote: > > slow request issues). If you watch your xfs stats you'll likely get > > further confirmation. In my experience xs_dir_lookups balloons (which > > means directory lookups are missing cache and going to disk). > > Murphy's a bitch. Today we upgraded a cluster to latest Hammer in > preparation for Jewel/RHCS2. Turns out when we last hit this very > problem we had only ephemerally set the new filestore merge/split > values - oops. Here's what started happening when we upgraded and > restarted a bunch of OSDs: > > https://au-east.erc.monash.edu.au/swift/v1/public/grafana-ceph-xs_dir_lookup.png > > Seemed to cause lots of slow requests :-/. We corrected it about > 12:30, then still took a while to settle. > > -- > Cheers, > ~Blairo >
{kind=link}
_______________________________________________ ceph-users mailing list [email protected] http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com