Sorry, late to the party here. I agree, up the merge and split thresholds. We're as high as 50/12. I chimed in on an RH ticket here. One of those things you just have to find out as an operator since it's not well documented :(
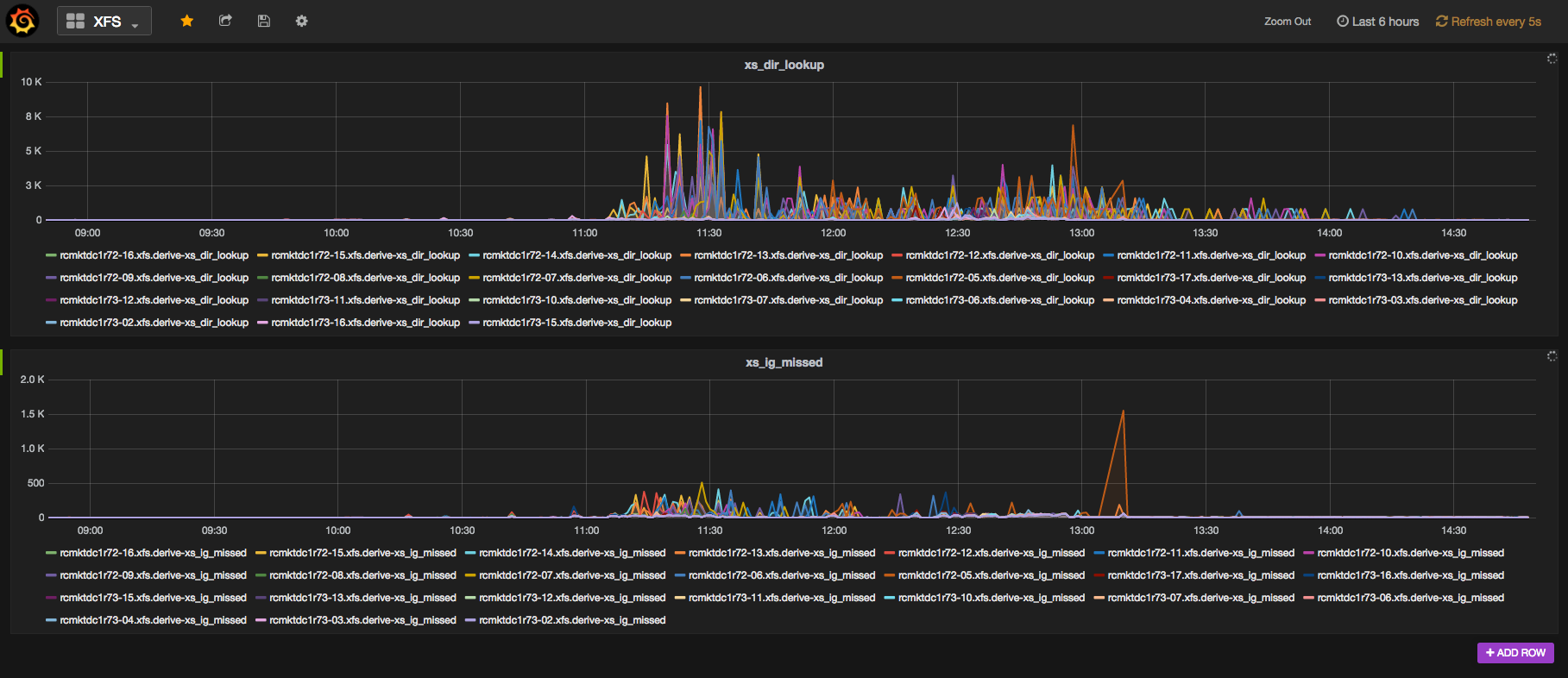
https://bugzilla.redhat.com/show_bug.cgi?id=1219974 We have over 200 million objects in this cluster, and it's still doing over 15000 write IOPS all day long with 302 spinning drives + SATA SSD journals. Having enough memory and dropping your vfs_cache_pressure should also help. Keep in mind that if you change the values, it won't take effect immediately. It only merges them back if the directory is under the calculated threshold and a write occurs (maybe a read, I forget). Warren From: ceph-users <[email protected]<mailto:[email protected]>> on behalf of Wade Holler <[email protected]<mailto:[email protected]>> Date: Monday, June 20, 2016 at 2:48 PM To: Blair Bethwaite <[email protected]<mailto:[email protected]>>, Wido den Hollander <[email protected]<mailto:[email protected]>> Cc: Ceph Development <[email protected]<mailto:[email protected]>>, "[email protected]<mailto:[email protected]>" <[email protected]<mailto:[email protected]>> Subject: Re: [ceph-users] Dramatic performance drop at certain number of objects in pool Thanks everyone for your replies. I sincerely appreciate it. We are testing with different pg_num and filestore_split_multiple settings. Early indications are .... well not great. Regardless it is nice to understand the symptoms better so we try to design around it. Best Regards, Wade On Mon, Jun 20, 2016 at 2:32 AM Blair Bethwaite <[email protected]<mailto:[email protected]>> wrote: On 20 June 2016 at 09:21, Blair Bethwaite <[email protected]<mailto:[email protected]>> wrote: > slow request issues). If you watch your xfs stats you'll likely get > further confirmation. In my experience xs_dir_lookups balloons (which > means directory lookups are missing cache and going to disk). Murphy's a bitch. Today we upgraded a cluster to latest Hammer in preparation for Jewel/RHCS2. Turns out when we last hit this very problem we had only ephemerally set the new filestore merge/split values - oops. Here's what started happening when we upgraded and restarted a bunch of OSDs: https://au-east.erc.monash.edu.au/swift/v1/public/grafana-ceph-xs_dir_lookup.png Seemed to cause lots of slow requests :-/. We corrected it about 12:30, then still took a while to settle. -- Cheers, ~Blairo This email and any files transmitted with it are confidential and intended solely for the individual or entity to whom they are addressed. If you have received this email in error destroy it immediately. *** Walmart Confidential ***
{kind=link}
_______________________________________________ ceph-users mailing list [email protected] http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com