### TL;DR This is a fix for what I think is a regression since the introduction of HarfBuzz in JDK 9. The problem is that the algorithm which converts the glyph vector produced by the layout engine into a corresponding character vector (in `ExtendedTextSourceLabel::createCharinfo()`) still assumes that "*each glyph maps to a single character*". But this is not true any more with HarfBuzz and as this example demonstrates, can lead to improper clustering of characters which can result to bad line breaking decisions.
I ran the corresponding JTreg and JCK test on Linux but because this area is heavily dependent on the OS and concrete fonts I'd like to kindly ask you to run your internal test suites in this area if possible. In the following you can find a longer (maybe a bit too long :) description of this problem which I merely wrote for my own memory. ### Full description A customer reported a regression in JDK 9+ which leads to bad/wrong line breaks for text in the Khmer language. Khmer is a [complex script](https://en.wikipedia.org/wiki/Khmer_script) which was only added to the Unicode standard 3.0 in 1999 (in the [Unicode block U+1780..U+17FF](https://en.wikipedia.org/wiki/Khmer_(Unicode_block))) and I personally don't understand Khmer at all :) Fortunately, the customer could provide a [simple reproducer](https://bugs.openjdk.org/secure/attachment/115218/KhmerTest.java) which I could further condense to the following example: "បានស្នើសុំនៅតែត្រូវបានបដិសេធ" (according to Google translate, this means "*Requested but still denied*"). If we use OpenJDK's [`LineBreakMeasurer`](https://docs.oracle.com/en/java/javase/24/docs/api/java.desktop/java/awt/font/LineBreakMeasurer.html) to layout that paragraph (notice that Khmer has no spaces between words) to fit within a specific "wrapping width", the output may look as follows with JDK 8 (the exact output depends on the font and the wrapping width): Segment: បានស្នើសុំ 0 10 Segment: នៅតែត្រូវ 10 9 Segment: បានបដិសេ 19 8 Segment: ធ 27 1 I ran with both, the logical [DIALOG](https://docs.oracle.com/en/java/javase/24/docs/api/java.desktop/java/awt/Font.html#DIALOG) font or directly with `/usr/share/fonts/truetype/ttf-khmeros-core/KhmerOS.ttf` on Ubuntu 22.04 (on my system DIALOG will automatically fall back to the KhmerOS font for characters from the Khmer Unicode code block). I also tried with the [Noto Khmer](https://fonts.google.com/noto/specimen/Noto+Serif+Khmer) fonts but the results were similar, so I'll stick to KhmerOS for the reminder of this blog. As you can see, the paragraph was broken after the 10th, 19th, and 27th characters respectively. However, with JDK 9+, the output regresses to: Segment: បានស្នើសុំ 0 10 Segment: នៅតែ 10 4 Segment: ត 14 1 Segment: ្រូវបានបដិសេធ 15 13 We now have a premature break after 14 characters, a segment with just a single character and the last line is too long. In order to verify if there's a difference in the layout and rendering of this sentence between JDK 8 and 9+ I [extended the initial reproducer](./src/java/KhmerTestSwing.java) to paint the whole sentence as well as the single line segments into a Swing `JPanel`. Here's the result for JDK 8: 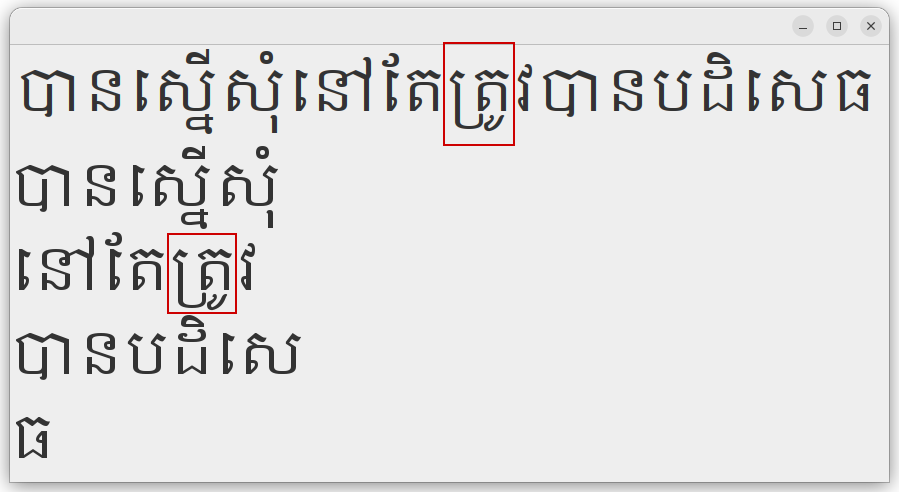 And JDK 9+:  As can be seen, the whole sentence is laid out and rendered correctly in JDK 9+ as well, as long as it completely fits into a single line. However, in JDK 9+ there's an issue with line breaking at the "ត្រូ" ligature (highlighted with a red box in the above pictures). This specific ligature is composed from the glyphs of four Unicode code points, namely `U+178F` ("ត", KHMER LETTER TA), `U+17D2` ("្", KHMER SIGN COENG), `U+179A` ("រ", KHMER LETTER RO) and `U+17BC` ("ូ", KHMER VOWEL SIGN UU) ". If rendered correctly, `U+179A` is reordered (visually) before `U+178F` and `U+17BC` below `U+179A`. The visual reordering of `U+179A` before `U+178F` is controlled by `U+17D2` which is not itself represented visually. In OpenJDK, all this complex text layout is performed by a so called text layout or shaping engine. Up to and including JDK 8, OpenJDK used the [ICU Layout Engine](https://unicode-org.github.io/icu/userguide/layoutengine/) for this task. In JDK 9, the ICU layout engine was deprecated and replaced by [Harfbuzz](https://github.com/harfbuzz/harfbuzz) (see [JEP 258: HarfBuzz Font-Layout Engine](https://bugs.openjdk.org/browse/JDK-8064530)). Whenever OpenJDK will have to do complex text layout, it will eventually call into tha native layout engine. For the current JDK 25 this looks as follows: at sun.font.HBShaper.shape(HBShaper.java:460) at sun.font.SunLayoutEngine.layout(SunLayoutEngine.java:182) at sun.font.GlyphLayout$EngineRecord.layout(GlyphLayout.java:669) at sun.font.GlyphLayout.layout(GlyphLayout.java:459) at sun.font.GlyphLayout.layout(GlyphLayout.java:357) at sun.font.ExtendedTextSourceLabel.createGV(ExtendedTextSourceLabel.java:333) at sun.font.ExtendedTextSourceLabel.getGV(ExtendedTextSourceLabel.java:319) at sun.font.ExtendedTextSourceLabel.createCharinfo(ExtendedTextSourceLabel.java:638) at sun.font.ExtendedTextSourceLabel.getCharinfo(ExtendedTextSourceLabel.java:563) at sun.font.ExtendedTextSourceLabel.getLineBreakIndex(ExtendedTextSourceLabel.java:486) at java.awt.font.TextMeasurer.calcLineBreak(TextMeasurer.java:330) at java.awt.font.TextMeasurer.getLineBreakIndex(TextMeasurer.java:566) at java.awt.font.LineBreakMeasurer.nextOffset(LineBreakMeasurer.java:360) at java.awt.font.LineBreakMeasurer.nextOffset(LineBreakMeasurer.java:329) at KhmerTestSwing.main(KhmerTestSwing.java:82) Notice that since JDK 22, this is done through a new FFM based interface defined in [`HBShaper_Panama.c`](https://github.com/openjdk/jdk/blob/jdk25/src/java.desktop/share/native/libfontmanager/HBShaper_Panama.c) (see [8318364: Add an FFM-based implementation of harfbuzz OpenType layout](https://bugs.openjdk.org/browse/JDK-8318364)) by default, but can still be configured to use the old JNI-based interface (in [`HBShaper.c`](https://github.com/openjdk/jdk/blob/jdk25/src/java.desktop/share/native/libfontmanager/HBShaper.c)) with the `-Dsun.font.layout.ffm=false` system property. In the end, they both call into the bundled, native HarfBuzz function [`hb_shape_full(..)`](https://github.com/openjdk/jdk/blob/6c48f4ed707bf0b15f9b6098de30db8aae6fa40f/src/java.desktop/share/native/libharfbuzz/hb-shape.cc#L127) which takes a font and a buffer of characters (i.e. Unicode code points) as input and returns a buffer of font glyphs along with their metrics and some meta-information as output (here you can find the original [HarfBuzz upstream version](https://github.com/harfbuzz/harfbuzz/blob/0a257b0188ce8b002b51d9955713cd7136ca4769/src/hb-shape.cc#L127)). HarfBuzz has a [nice documentation](https://harfbuzz.github.io/index.html) which explains a lot of the concepts involved in complex text layout (called "shaping" in HarfBuzz). The relevant part for this discussion is the section on [Clusters and shaping](https://harfbuzz.github.io/clusters.html#clusters-and-shaping) which basically explains the implementation and usage of the [`hb_shape_full()](https://harfbuzz.github.io/harfbuzz-hb-shape.html#hb-shape-full) function. Previously, in JDK 8, `SunLayoutEngine::layout()` called the native `SunLayoutEngine::nativeLayout()` function which called right into the native, bundled ICU method [`LayoutEngine::layoutChars()`](https://github.com/openjdk/jdk8u-dev/blob/89b85a8f5b0f8e4f7763cf9b4d15e051d6e9f43f/jdk/src/share/native/sun/font/layout/LayoutEngine.cpp#L553) (here's the original [ICU upstream version](https://github.com/unicode-org/icu/blob/8fbc9902bd2ec278ae471b8215cdcc2d1cf13555/source/layout/LayoutEngine.cpp#L442)). The ICU Layout engine is documented [here](https://unicode-org.github.io/icu/userguide/layoutengine/). The GitHub HarfBuzz organization contains the [`icu-le-hb`](https://github.com/harfbuzz/icu-le-hb) repository which provides a library exposing the ICU Layout Engine API by using HarfBuzz as internal implementation. Its [`LayoutEngine::layoutChars()`](https://github.com/harfbuzz/icu-le-hb/blob/01b8e255d08a9ea2c2a0665f2b673fe9e71c7ec1/src/LayoutEngine.cpp#L180) method demonstrates how HarfBuzz can be invoked to simulate ICU's layout functionality. We'll revisit its implementation later in this document. ### The ICU layout engine In order to identify the differences between the two layout engines, we can use the system property `-Dsun.java2d.debugfonts=true` on JDK 9+. For JDK 8, we have to recompile the JDK and set the private, boolean [`DEBUG`](https://github.com/openjdk/jdk8u-dev/blob/89b85a8f5b0f8e4f7763cf9b4d15e051d6e9f43f/jdk/src/share/classes/sun/font/ExtendedTextSourceLabel.java#L640) field in the `sun.font.ExtendedTextSourceLabel` class to true in order to get a similar output. In JDK 8 this will result in the following output from the method [`ExtendedTextSourceLabel::createCharinfo()`](https://github.com/openjdk/jdk8u-dev/blob/89b85a8f5b0f8e4f7763cf9b4d15e051d6e9f43f/jdk/src/share/classes/sun/font/ExtendedTextSourceLabel.java#L618) which translates from the Glyph information computed by the layout engine back to character information: number of glyphs: 30 glyphinfo.len: 240 indices.len: 30 g: 0 v: 455, x: 0.0, a: 68.115234, n: 0 g: 1 v: 65534, x: 68.115234, a: 0.0, n: 1 g: 2 v: 581, x: 68.115234, a: 45.410156, n: 2 g: 3 v: 627, x: 113.52539, a: 22.705078, n: 6 g: 4 v: 593, x: 136.23047, a: 68.115234, n: 3 g: 5 v: 402, x: 205.07812, a: 0.0, n: 4 g: 6 v: 65535, x: 204.3457, a: 0.0, n: 5 g: 7 v: 714, x: 203.61328, a: 0.0, n: 6 g: 8 v: 593, x: 204.3457, a: 68.115234, n: 7 g: 9 v: 621, x: 271.72852, a: 0.0, n: 8 g: 10 v: 632, x: 271.72852, a: 0.0, n: 9 g: 11 v: 627, x: 272.46094, a: 22.705078, n: 11 g: 12 v: 503, x: 295.16602, a: 68.115234, n: 10 g: 13 v: 65534, x: 363.28125, a: 0.0, n: 11 g: 14 v: 628, x: 363.28125, a: 22.705078, n: 13 g: 15 v: 577, x: 385.98633, a: 45.410156, n: 12 g: 16 v: 409, x: 431.39648, a: 22.705078, n: 15 g: 17 v: 65535, x: 454.10156, a: 0.0, n: 16 g: 18 v: 577, x: 454.10156, a: 45.410156, n: 14 g: 19 v: 622, x: 498.04688, a: 0.0, n: 17 g: 20 v: 590, x: 499.51172, a: 22.705078, n: 18 g: 21 v: 455, x: 522.2168, a: 68.115234, n: 19 g: 22 v: 65534, x: 590.33203, a: 0.0, n: 20 g: 23 v: 581, x: 590.33203, a: 45.410156, n: 21 g: 24 v: 582, x: 635.7422, a: 45.410156, n: 22 g: 25 v: 572, x: 681.15234, a: 45.410156, n: 23 g: 26 v: 617, x: 725.09766, a: 0.0, n: 24 g: 27 v: 627, x: 726.5625, a: 22.705078, n: 26 g: 28 v: 593, x: 749.2676, a: 68.115234, n: 25 g: 29 v: 580, x: 817.3828, a: 45.410156, n: 27 First, there's the glyph list produced by layout engine. It contains 30 glyphs (two more than the 28 characters of our input text). For each glyph, we see its glyph ID in the font that is used, the x-position of that glyph in the final image and the [advance](https://docs.oracle.com/en/java/javase/24/docs/api/java.desktop/java/awt/font/GlyphMetrics.html#getAdvance()), i.e. its space up to the next glyph (notice that the advance can be zero). E.g. we can easily verify that the first glyph with the number 455 (i.e. "បា") corresponds to the the ligature of the first two characters `U+1794` ("ប", KHMER LETTER BA) and `U+17B6` ("ា", KHMER VOWEL SIGN AA) in our `KhmerOS.ttf` font by uploading that font file to https://fontdrop.info/ and searching for the glyph number 455 (the glyph name is `uni1794.a` which indicates that it is a ligature of the unicode character `U+1794` and the vowel AA). The last column in the output is the [cluster number](https://harfbuzz.github.io/clusters.html#clusters-and-shaping) to which the corresponding glyph belongs to. So in our example, the zeroth glyph belongs to the zeroth cluster, while glyph one belongs to the first cluster. Glyph one is interesting, because we can't find a glyph with index 65534 in the font. Actually, glyph indices which are greater or equal to 65534 (i.e. `0xFFFE` and `0xFFFF`) denote "*invisible glyphs*". These constants are e.g. defined e.g. in [`sun.font.CharToGlyphMapper`](https://github.com/openjdk/jdk/blob/2b756ab1e8cfacc5cf5d9c6dfdf1d1c9a6ecf4b1/src/java.desktop/share/classes/sun/font/CharToGlyphMapper.java#L45-L46): public static final int INVISIBLE_GLYPH_ID = 0xffff; public static final int INVISIBLE_GLYPHS = 0xfffe; // and above The ICU Layout Engine inserts these "invisible glyphs" for characters that were substituted by ligatures in [`LigatureSubstitutionSubtable::process()`](https://github.com/openjdk/jdk8u-dev/blob/89b85a8f5b0f8e4f7763cf9b4d15e051d6e9f43f/jdk/src/share/native/sun/font/layout/LigatureSubstSubtables.cpp#L90) (depending on whether the [OpenType `IgnoreMarks` lookup flag](https://github.com/openjdk/jdk8u-dev/blob/89b85a8f5b0f8e4f7763cf9b4d15e051d6e9f43f/jdk/src/share/native/sun/font/layout/LigatureSubstSubtables.cpp#L90) is set, it will insert either `0xFFFE` or `0xFFFF` otherwise). The glyph list is then followed by a character list which displays for every character its Unicode code point, its x/y position, its x/y advance and its visual bounding box (omitted here for brevity): char info for 28 characters ch: 1794 x: 0.0 y: 0.0 xa: 68.115234 ya: 0.0 .. ch: 17b6 x: 68.115234 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 1793 x: 68.115234 y: 0.0 xa: 45.410156 ya: 0.0 .. ch: 179f x: 113.52539 y: 0.0 xa: 90.82031 ya: 0.0 .. ch: 17d2 x: 204.3457 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 1793 x: 204.3457 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 17be x: 204.3457 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 179f x: 204.3457 y: 0.0 xa: 68.115234 ya: 0.0 .. ch: 17bb x: 272.46094 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 17c6 x: 272.46094 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 1793 x: 272.46094 y: 0.0 xa: 90.82031 ya: 0.0 .. ch: 17c5 x: 363.28125 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 178f x: 363.28125 y: 0.0 xa: 68.115234 ya: 0.0 .. ch: 17c2 x: 431.39648 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 178f x: 431.39648 y: 0.0 xa: 68.115234 ya: 0.0 .. ch: 17d2 x: 499.51172 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 179a x: 499.51172 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 17bc x: 499.51172 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 179c x: 499.51172 y: 0.0 xa: 22.705078 ya: 0.0 .. ch: 1794 x: 522.2168 y: 0.0 xa: 68.115234 ya: 0.0 .. ch: 17b6 x: 590.33203 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 1793 x: 590.33203 y: 0.0 xa: 45.410156 ya: 0.0 .. ch: 1794 x: 635.7422 y: 0.0 xa: 45.410156 ya: 0.0 .. ch: 178a x: 681.15234 y: 0.0 xa: 45.410156 ya: 0.0 .. ch: 17b7 x: 726.5625 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 179f x: 726.5625 y: 0.0 xa: 90.82031 ya: 0.0 .. ch: 17c1 x: 817.3828 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 1792 x: 817.3828 y: 0.0 xa: 45.410156 ya: 0.0 .. >From the output, we can infer that the first two characters (i.e. `U+1794` >("ប", KHMER LETTER BA) and `U+17B6` ("ា", KHMER VOWEL SIGN AA)) are visually >represented by a single glyph (i.e. the ligature "បា"), because `U+17B6`'s >advance is zero (i.e. the "visual representation" of `U+17B6` is already >"contained" in the ligature glyph for `U+1794`). For the character combination >which causes problems in JDK 9+, we get the following information: ch: 178f x: 431.39648 y: 0.0 xa: 68.115234 ya: 0.0 .. ch: 17d2 x: 499.51172 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 179a x: 499.51172 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 17bc x: 499.51172 y: 0.0 xa: 0.0 ya: 0.0 .. ``` I.e., visually, they are represented by a single ligature starting at x-position `431.39648` with a width of `68.115234` which is fully accounted to the first character `U+178f`. The following three characters start at `499.51172` (i.e. `431.39648 + 68.115234`) with a zero advance. The ligature is composed from the following four glyphs (taken from the glyph listing above): g: 16 v: 409, x: 431.39648, a: 22.705078, n: 15 g: 17 v: 65535, x: 454.10156, a: 0.0, n: 16 g: 18 v: 577, x: 454.10156, a: 45.410156, n: 14 g: 19 v: 622, x: 498.04688, a: 0.0, n: 17 By inspecting the font, we can find that `409` is the glyph for `U+179a`, `577` for `U+178f` and `622` for `U+17bc`. Notice how `U+179a` was visually re-ordered before `U+178f` and how `U+17d2` was replaced by the invisible glyph `65535` because it has no visible representation. ### The HarfBuzz layout engine With HarfBuzz in JDK 9+, the glyph list looks slightly different: number of glyphs: 25 glyphinfo.len: 200 indices.len: 25 g: 0 v: 455, x: 0.0, a: 68.115234, n: 0 g: 1 v: 581, x: 68.115234, a: 45.410156, n: 2 g: 2 v: 627, x: 113.52539, a: 22.705078, n: 3 g: 3 v: 593, x: 136.23047, a: 68.115234, n: 3 g: 4 v: 402, x: 205.07812, a: 0.0, n: 3 g: 5 v: 714, x: 203.61328, a: 0.0, n: 3 g: 6 v: 593, x: 204.3457, a: 68.115234, n: 7 g: 7 v: 621, x: 271.72852, a: 0.0, n: 8 g: 8 v: 632, x: 271.72852, a: 0.0, n: 9 g: 9 v: 627, x: 272.46094, a: 22.705078, n: 10 g: 10 v: 503, x: 295.16602, a: 68.115234, n: 10 g: 11 v: 628, x: 363.28125, a: 22.705078, n: 12 g: 12 v: 577, x: 385.98633, a: 45.410156, n: 12 g: 13 v: 409, x: 431.39648, a: 22.705078, n: 14 g: 14 v: 577, x: 454.10156, a: 45.410156, n: 14 g: 15 v: 554, x: 499.51172, a: 0.0, n: 17 g: 16 v: 590, x: 499.51172, a: 22.705078, n: 18 g: 17 v: 455, x: 522.2168, a: 68.115234, n: 19 g: 18 v: 581, x: 590.33203, a: 45.410156, n: 21 g: 19 v: 582, x: 635.7422, a: 45.410156, n: 22 g: 20 v: 572, x: 681.15234, a: 45.410156, n: 23 g: 21 v: 617, x: 725.09766, a: 0.0, n: 24 g: 22 v: 627, x: 726.5625, a: 22.705078, n: 25 g: 23 v: 593, x: 749.2676, a: 68.115234, n: 25 g: 24 v: 580, x: 817.3828, a: 45.410156, n: 27 First, we only have 25 glyphs, i.e. fewer glyphs than characters. That's because HarfBuzz is not inserting invisible glyphs for characters which have been substituted by ligatures or which have no visible representation. Second, the [cluster numbers](https://harfbuzz.github.io/clusters.html#clusters-and-shaping) are monotonically increasing and non-contiguous (because some cluster numbers are missing). The difference in the number of clusters and their ordering is because OpenJDK is using HarfBuzz's default [cluster level](https://harfbuzz.github.io/working-with-harfbuzz-clusters.html) one (i.e. [`HB_BUFFER_CLUSTER_LEVEL_MONOTONE_CHARACTERS`](https://harfbuzz.github.io/harfbuzz-hb-buffer.html#hb-buffer-cluster-level-t)) which "merges" clusters. If we change the cluster level in [`HBShaper_Panama.c`](https://github.com/openjdk/jdk/blob/6e91ccd1c3926094a9b6d8f9177d895aba3424a1/src/java.desktop/share/native/libfontmanager/HBShaper_Panama.c#L118) to `HB_BUFFER_CLUSTER_LEVEL_CHARACTERS`, we will get the same cluster numbers like with ICU in JDK 8, but it turns out, that this doesn't make any difference for the final layout and breaking decisions, so we wont follow this path any further. There's a final difference for glyph number 15 which is part of the character sequence that is broken incorrectly in JDK 9+. With HarfBuzz `U+17BC` gets replaced by glyph `554` (i.e. `uni17bc.alt`) whereas ICU replaces it by the glyph `622` (i.e. `uni17bc`) in JDK 8. However, from looking at the font, we can see that both glyphs have the same shape and are both representations of the same Unicode code point (as their names imply). The only difference between them is that the glyph `554` starts at a lower y-position and this can be clearly seen in the screenshots at the beginning of this article. But substituting one with the other doesn't make any different for the line breaking behaviour so we will ignore this difference for now (although it is interesting and the ICU choice in JDK 8 seems to be visually more appealing). Notice that apart from the mentioned differences, both layouts (i.e. the glyphs and their exact positions and dimensions) are exactly the same which I find quite impressing! Still, the resulting character list looks quite different: char info for 28 characters ch: 1794 x: 0.0 y: 0.0 xa: 68.115234 ya: 0.0 .. ch: 17b6 x: 68.115234 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 1793 x: 68.115234 y: 0.0 xa: 45.410156 ya: 0.0 .. ch: 179f x: 113.52539 y: 0.0 xa: 90.82031 ya: 0.0 .. ch: 17d2 x: 204.3457 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 1793 x: 204.3457 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 17be x: 204.3457 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 179f x: 204.3457 y: 0.0 xa: 68.115234 ya: 0.0 .. ch: 17bb x: 272.46094 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 17c6 x: 272.46094 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 1793 x: 272.46094 y: 0.0 xa: 90.82031 ya: 0.0 .. ch: 17c5 x: 363.28125 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 178f x: 363.28125 y: 0.0 xa: 68.115234 ya: 0.0 .. ch: 17c2 x: 431.39648 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 178f x: 431.39648 y: 0.0 xa: 431.39648 ya: 0.0 .. ch: 17d2 x: 862.79297 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 179a x: 862.79297 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 17bc x: 862.79297 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 179c x: 862.79297 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 1794 x: 862.79297 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 17b6 x: 862.79297 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 1793 x: 862.79297 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 1794 x: 862.79297 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 178a x: 862.79297 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 17b7 x: 862.79297 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 179f x: 862.79297 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 17c1 x: 862.79297 y: 0.0 xa: 0.0 ya: 0.0 .. ch: 1792 x: 862.79297 y: 0.0 xa: 0.0 ya: 0.0 .. ``` Starting from character 15 (`U+178f`) all subsequent characters are grouped into the same, huge cluster with an advance of zero. This is the reason, why in our reproducer, the last segment can't be broken up any more and is much too long. ### The difference between ICU and HarfBuzz The only remaining difference are the missing invisible glyphs in the resulting glyph vector when using HarfBuzz. But they only seem to impact line breaking and not the general layout as can be seen when we render the whole example sentence in one line. And indeed, manually inserting an invisible glyph at index 14 fixes line breaking in JDK 9+. Also, if we take a closer look at the [`icu-le-hb`](https://github.com/harfbuzz/icu-le-hb) library mentioned before which wraps HarfBuzz with a ICU Layout Engine compatible API, we can see that its [`LayoutEngine::layoutChars()`](https://github.com/harfbuzz/icu-le-hb/blob/01b8e255d08a9ea2c2a0665f2b673fe9e71c7ec1/src/LayoutEngine.cpp#L204) method contains the following comment: /* ICU LE generates at least one glyph for each and every input 16bit codepoint. * Do the same by inserting fillers. */ So one possibility to fix our problem would be to integrate this post-processing of the glyph vector after the call to `hb_shape_full()` into OpenJDK as well. One the other hand, we can also take a look on how the resulting glyph vector is processed in OpenJDK and how the corresponding code is handling invisible glyphs. The comments on `ExtendedTextSourceLabel::createCharinfo()` differ as follows between [JDK 8](https://github.com/openjdk/jdk8u-dev/blob/89b85a8f5b0f8e4f7763cf9b4d15e051d6e9f43f/jdk/src/share/classes/sun/font/ExtendedTextSourceLabel.java#L553) and [JDK 9+](https://github.com/openjdk/jdk/blob/c1198bba0e8cbdaa47c821263d122d0ba4dd6759/src/java.desktop/share/classes/sun/font/ExtendedTextSourceLabel.java#L569): /* * This takes the glyph info record obtained from the glyph vector and converts it into a similar record * adjusted to represent character data instead. For economy we don't use glyph info records in this processing. * * Here are some constraints: * - there can be more glyphs than characters (glyph insertion, perhaps based on normalization, has taken place) -* - there can not be fewer glyphs than characters (0xffff glyphs are inserted for characters ligaturized away) +* - there can be fewer glyphs than characters +* Some layout engines may insert 0xffff glyphs for characters ligaturized away, but +* not all do, and it cannot be relied upon. * - each glyph maps to a single character, when multiple glyphs exist for a character they all map to it, but * no two characters map to the same glyph * - multiple glyphs mapping to the same character need not be in sequence (thai, tamil have split characters) * - glyphs may be arbitrarily reordered (Indic reorders glyphs) This only documents one of the differences that we've already detected by looking at the debug output, namely the missing invisible glyphs which are only inserted by the old ICU engine. But it still claims that "*each glyph maps to a single character*" which isn't true any more with HarfBuzz which doesn't add invisible glyphs for ligaturized characters any more. Also, the following part of the comment which describes the algorithm hasn't changed between 8 and 9+: /* ... * 3) we consume clusters in the following way: * a) the first element is always consumed * b) subsequent elements are consumed if: * i) their advance is zero * ii) their character index <= the character index of any character seen in this cluster * iii) the minimum character index seen in this cluster isn't adjacent to the previous cluster I don't think point `iii)` is required any more with HarfBuzz, because with the `HB_BUFFER_CLUSTER_LEVEL_MONOTONE_CHARACTERS` cluster level, the cluster numbers (which initially correspond to the character indices, before they can be merged during the layout) are guaranteed to be monotonic, so we don't have situations like the following (taken from the JDK 8 glyph list above) where glyph `3` has a cluster index of `6` which is bigger than glyph `4`'s cluster index: g: 3 v: 627, x: 113.52539, a: 22.705078, n: 6 g: 4 v: 593, x: 136.23047, a: 68.115234, n: 3 g: 5 v: 402, x: 205.07812, a: 0.0, n: 4 g: 6 v: 65535, x: 204.3457, a: 0.0, n: 5 g: 7 v: 714, x: 203.61328, a: 0.0, n: 6 Here's the abridged and commented code for the consumption of a [cluster](https://harfbuzz.github.io/clusters.html) from [`ExtendedTextSourceLabel::createCharinfo()`](https://github.com/openjdk/jdk/blob/c1198bba0e8cbdaa47c821263d122d0ba4dd6759/src/java.desktop/share/classes/sun/font/ExtendedTextSourceLabel.java#L637): while (gx != gxlimit) { // gx = glyph index, gxlimit = max. glyph index int clusterExtraGlyphs = 0; // consumed glyphs minIndex = indices[gx]; // min. char index maxIndex = minIndex; // max. char index // advance to next glyph gx += xdelta; while (gx != gxlimit && // more glyphs? ((glyphinfo[gp + advx] == 0) || // i) advance == 0? (indices[gx] <= maxIndex) || // ii) char index <= maxIndex? (maxIndex - minIndex > clusterExtraGlyphs))) { // iii) THIS IS WRONG in JDK 9+ ++clusterExtraGlyphs; // have an extra glyph in this cluster ... // adjust min, max index minIndex = Math.min(minIndex, indices[gx]); maxIndex = Math.max(maxIndex, indices[gx]); // get ready to examine next glyph gx += xdelta; } // done with cluster, gx and gp are set for next glyph But even worse, condition `iii)` isn't just unnecessary with HarfBuzz, it can lead to errors, just like in our case, where we have the following glyph list: g: 13 v: 409, x: 431.39648, a: 22.705078, n: 14 g: 14 v: 577, x: 454.10156, a: 45.410156, n: 14 g: 15 v: 554, x: 499.51172, a: 0.0, n: 17 Here we consume glyph `13` as first glyph from cluster `14` and glyph `14` because it has the same cluster index (i.e. `14`, condition `ii`). Next, we also consume glyph `15` because it has zero advance (condition `i`). But this now also increases `maxIndex` (the maximum character index) to `17`, although we've only consumed two extra glyphs until now. This means that `maxIndex - minIndex` will be bigger than `clusterExtraGlyphs` and we will continue to consume further glyphs until the end of the sentence (resulting in the huge last cluster which can't be broken up any more). Notice that if we had an additional invisible glyph (with zero advance) in the list before glyph `15` (just like in JDK 8), it would have been added to the cluster because of rule `i` and also increased `clusterExtraGlyphs` by one, which would have invalidated the condition `maxIndex - minIndex > clusterExtraGlyphs` after the insertion of glyph `15`. So, to cut a (very) long story short, removing condition `iii` from the above while loop, will fix this issue (and hopefully don't be harmful for any other cases). ------------- Commit messages: - 8361381: GlyphLayout behavior differs on JDK 11+ compared to JDK 8 Changes: https://git.openjdk.org/jdk/pull/26825/files Webrev: https://webrevs.openjdk.org/?repo=jdk&pr=26825&range=00 Issue: https://bugs.openjdk.org/browse/JDK-8361381 Stats: 3 lines in 1 file changed: 1 ins; 1 del; 1 mod Patch: https://git.openjdk.org/jdk/pull/26825.diff Fetch: git fetch https://git.openjdk.org/jdk.git pull/26825/head:pull/26825 PR: https://git.openjdk.org/jdk/pull/26825
{kind=link}
{kind=link}