liu-hai commented on issue #13903: URL: https://github.com/apache/dolphinscheduler/issues/13903#issuecomment-1502550482
I also encountered the same bug, hope to fix soon, datax task node more than 2G of data will be killed halfway through the first run Here is my datax node configuration: [ 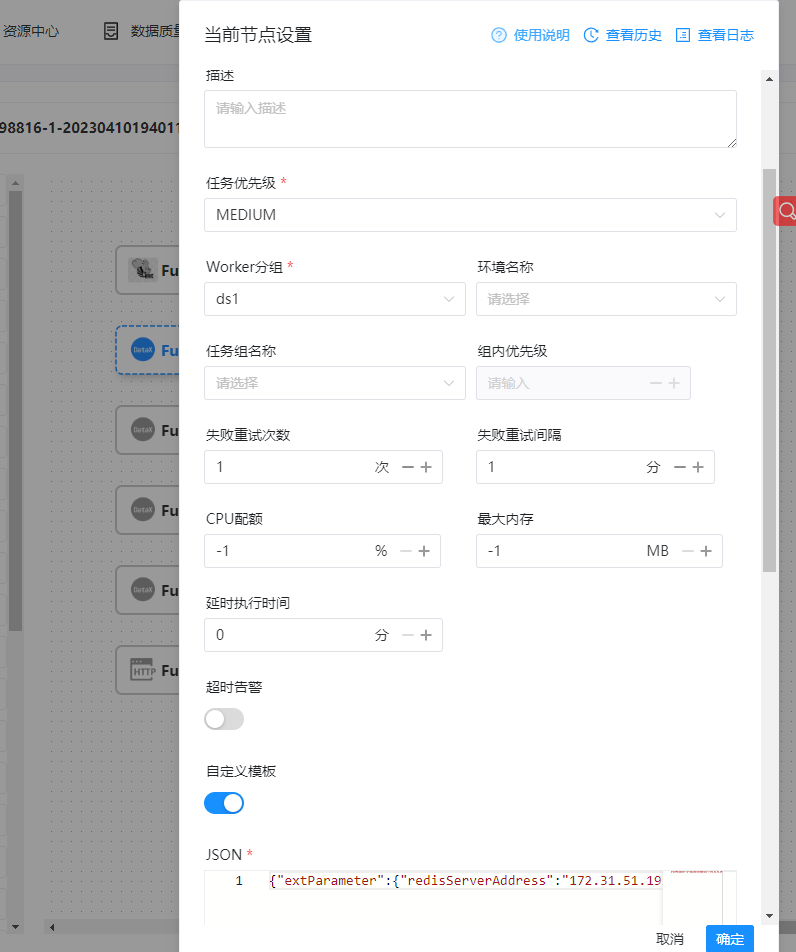 ](url) [ 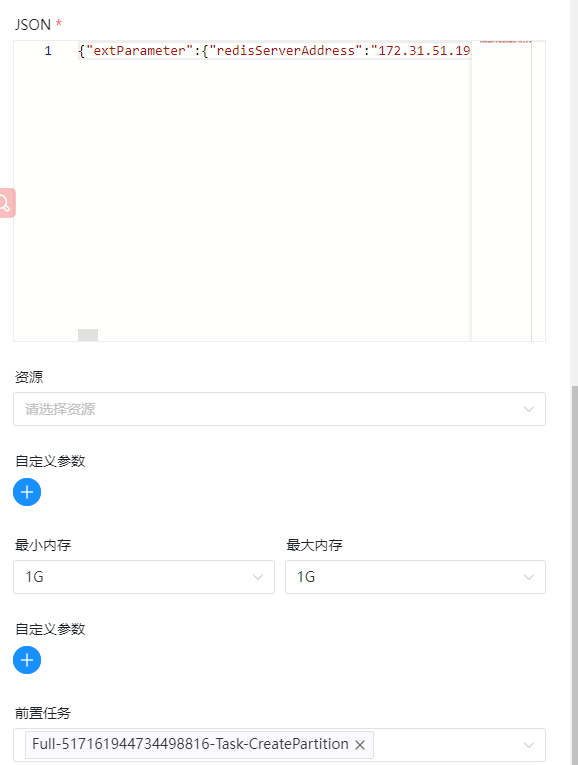 ](url) job.json configuration : `{ "reader": { "parameter": { "password": "*******", "column": [ "RowKey", "DataId", "DataType", "ChannelIndex", "FlowName", "SubFlowName", "ChannelTag1", "ChannelTag2", "CaptureType", "CaptureAngle", "Inputer", "DeviceSN", "DeviceIndex", "StartEventTime", "EventTime", "CaptureTime", "LPRClass", "LPR", "LPRColor", "VehicleClass", "VehicleType" ], "connection": [ { "jdbcUrl": [ "jdbc:mysql://170.31.11.193:3306/enshi_its" ], "table": [ "`VehiclePassCPT_t`" ] } ], "splitPk": "", "username": "root" }, "name": "mysqlreader" }, "writer": { "parameter": { "path": "/vision01/user/hive/warehouse/dcm_first.db/ods_vehiclepasscpt_t_vv5/dt=$[yyyyMMdd]", "fileName": "ods_vehiclepasscpt_t_vv5", "hadoopConfig": { "dfs.namenode.rpc-address.maxvision01.nn2": "170.31.11.202:8020", "dfs.namenode.rpc-address.maxvision01.nn1": "170.31.11.201:8020", "dfs.client.failover.proxy.provider.maxvision01": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider", "dfs.nameservices": "maxvision01", "dfs.ha.namenodes.maxvision01": "nn1,nn2" }, "column": [ { "name": "rowkey", "type": "string" }, { "name": "dataid", "type": "string" }, { "name": "datatype", "type": "int" }, { "name": "channelindex", "type": "int" }, { "name": "flowname", "type": "string" }, { "name": "subflowname", "type": "string" }, { "name": "channeltag1", "type": "string" }, { "name": "channeltag2", "type": "string" }, { "name": "capturetype", "type": "int" }, { "name": "captureangle", "type": "int" }, { "name": "inputer", "type": "string" }, { "name": "devicesn", "type": "string" }, { "name": "deviceindex", "type": "int" }, { "name": "starteventtime", "type": "string" }, { "name": "eventtime", "type": "string" }, { "name": "capturetime", "type": "string" }, { "name": "lprclass", "type": "int" }, { "name": "lpr", "type": "string" }, { "name": "lprcolor", "type": "int" }, { "name": "vehicleclass", "type": "int" }, { "name": "vehicletype", "type": "string" } ], "defaultFS": "hdfs://vision01", "writeMode": "truncate", "fieldDelimiter": "|", "fileType": "text" }, "name": "hdfswriter" } }` The following is the node run log, you can see that it was killed in the middle of the run, 不知道什么原因被杀死了,因为节点配置了失败重试次数为1,第一次失败之后重试又可以成功,只要mysql表的数据量大一点这个问题就必然出现,我这边是将mysql数据往hive写 [ 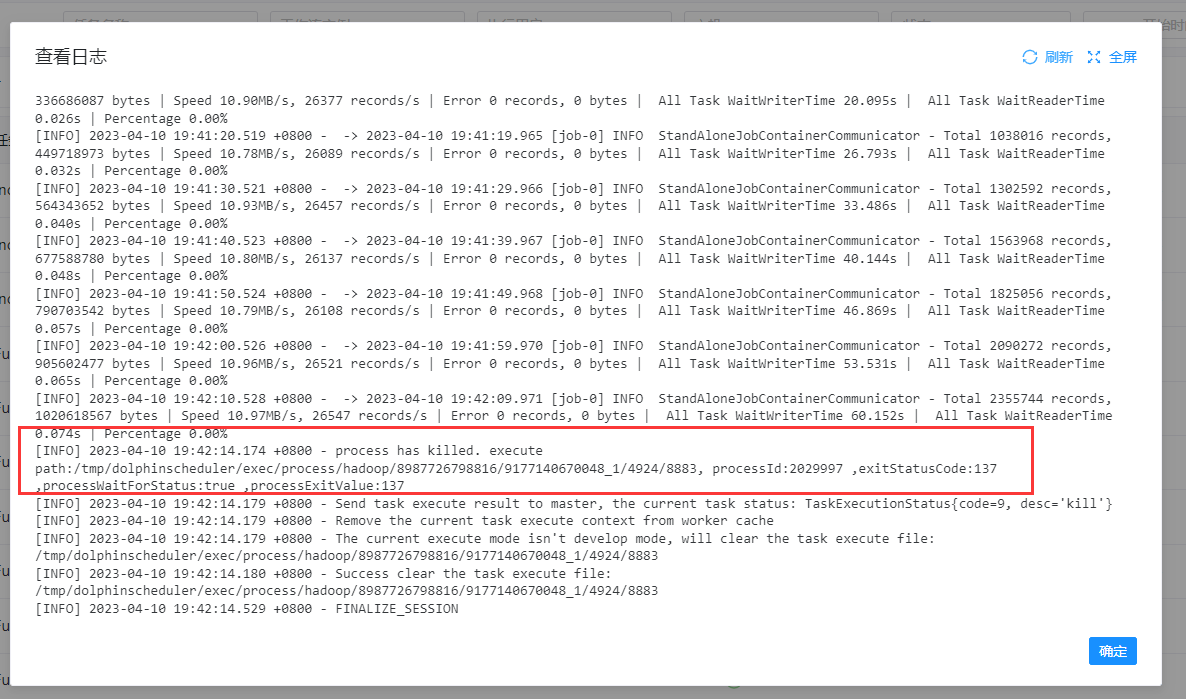 ](url) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}