dmarkhas opened a new issue #10687:
URL: https://github.com/apache/druid/issues/10687
When using index_hadoop to ingest a parquet file with null values in a
metric column, the useDefaultValueForNull=false is not respected when rollup is
enabled.
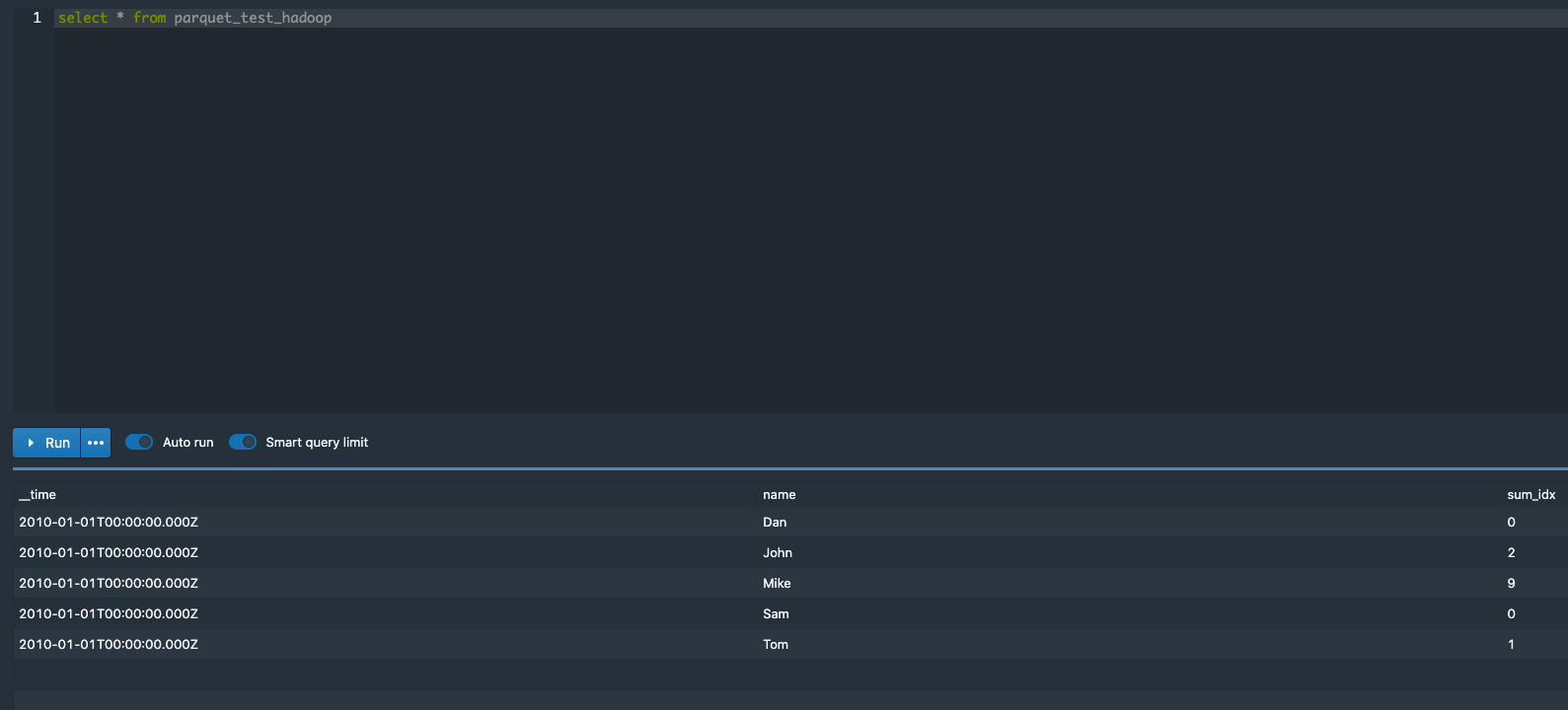
longSum aggregations for dimensions where the metric values are all null,
are calculated as 0 instead of null.
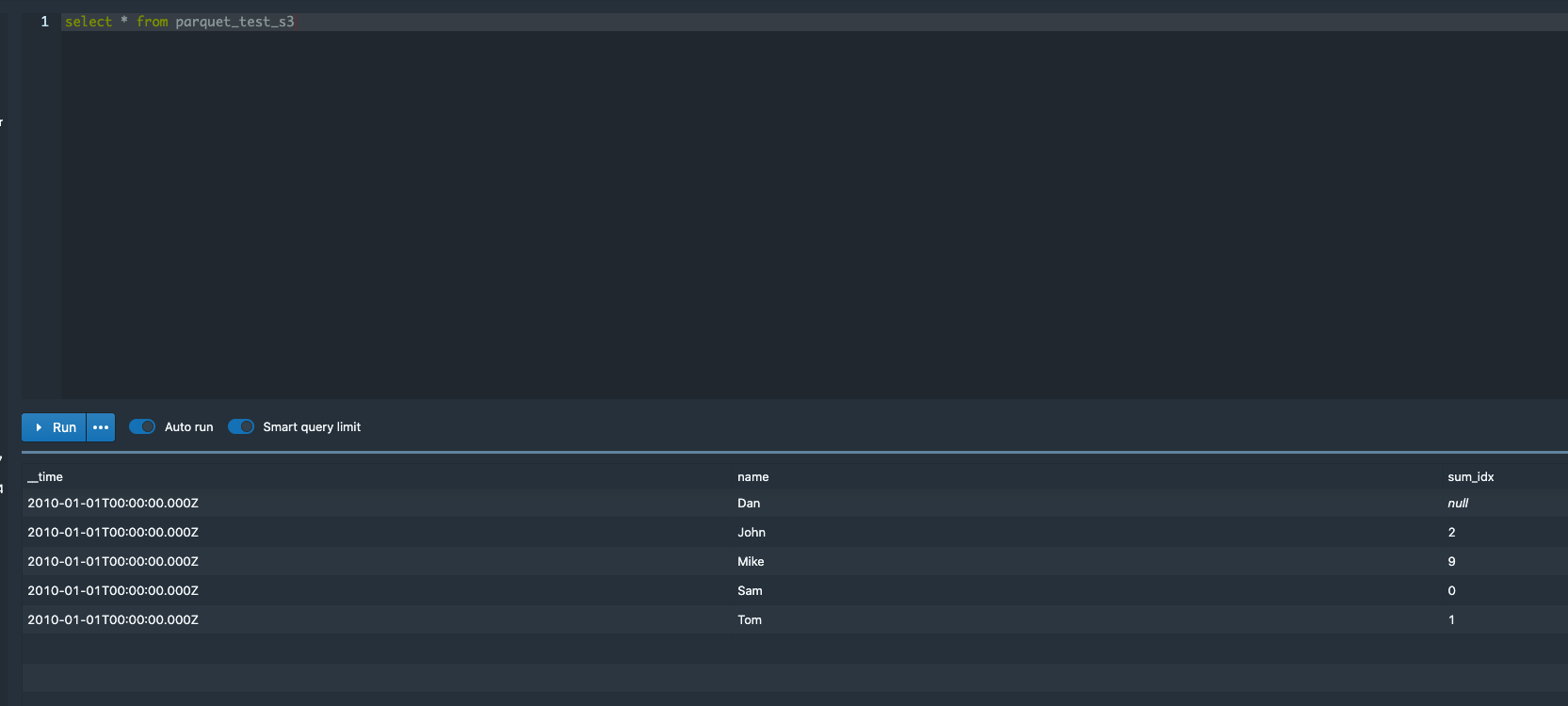
Ingesting the same file with index_parallel from local storage or natively
from S3, results in the correct behaviour and the longSum aggregations are
calculated as null.
### Affected Version
0.19.0
### Description
The parquet file has 3 columns - name (string), age (int), index (int) and
was created with the following Spark code:
```
val dfdata = Seq(Row("Dan",35, null), Row("Dan",34, null), Row("John",20,
2), Row("Mike",30, 9), Row("Sam",40, 0), Row("Tom", 17, 1))
val dfSchema = List(StructField("name", StringType, true),
StructField("age", IntegerType, true), StructField("index", IntegerType, true))
val df = spark.createDataFrame(spark.sparkContext.parallelize(dfdata),
StructType(dfSchema))
```
As you can see, the "index" column is null for all records with name =
'Dan', thus I would expect the longSum aggregation of "index" to be null for
these rows.
The parquet file itself is attached.
The ingestion spec used for ingestion via hadoop:
```
{
"type": "index_hadoop",
"spec": {
"ioConfig": {
"type": "hadoop",
"inputSpec": {
"type": "static",
"paths":"s3a://<BUCKET>/part-00000-5933233a-9db6-4bbb-8529-fa9687c9b2f1-c000.gz.parquet",
"inputFormat":
"org.apache.druid.data.input.parquet.DruidParquetInputFormat"
}
},
"tuningConfig" : {
"type": "hadoop"
},
"dataSchema": {
"dataSource": "parquet_test_hadoop",
"parser": {
"type": "parquet",
"parseSpec": {
"format": "parquet",
"dimensionsSpec": {
"dimensions": ["name"],
"dimensionExclusions": []
},
"timestampSpec": {
"missingValue": "2010-01-01T00:00:00.000Z",
"format": "auto",
"column": "timestamp"
}
}
},
"metricsSpec":[
{"name":"sum_idx", "type":"longSum","fieldName":"index"}
],
"granularitySpec": {
"type": "uniform",
"queryGranularity": "DAY",
"rollup": true,
"segmentGranularity": "DAY"
}
}
}
}
```
The ingestion spec used to ingest natively from S3:
```
{
"type": "index_parallel",
"spec": {
"dataSchema": {
"dataSource": "parquet_test_s3",
"timestampSpec": {
"column": "timestamp",
"format": "auto",
"missingValue": "2010-01-01T00:00:00.000Z"
},
"dimensionsSpec": {
"dimensions": ["name"]
},
"metricsSpec": [
{
"type": "longSum",
"name": "sum_idx",
"fieldName": "index"
}
],
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "DAY",
"queryGranularity": "DAY",
"rollup": true
}
},
"ioConfig": {
"type": "index_parallel",
"inputSource": {
"type": "s3",
"uris": [
"s3://<BUCKET>/part-00000-5933233a-9db6-4bbb-8529-fa9687c9b2f1-c000.gz.parquet"
],
"properties": {
"accessKeyId": {
"type": "default",
"password": "<ACCESS_KEY>"
},
"secretAccessKey": {
"type": "default",
"password": "<SECRET_KEY>"
}
}
},
"inputFormat": {
"type": "parquet"
}
},
"tuningConfig": {
"type": "index_parallel"
}
},
"dataSource": "parquet_test_s3"
}
```
useDefaultValueForNull is not respected for hadoop ingestion:
useDefaultValueForNull is respected for native ingestion:
[part-00000-5933233a-9db6-4bbb-8529-fa9687c9b2f1-c000.gz.parquet.gz](https://github.com/apache/druid/files/5709576/part-00000-5933233a-9db6-4bbb-8529-fa9687c9b2f1-c000.gz.parquet.gz)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}