jasonk000 opened a new pull request #12177:
URL: https://github.com/apache/druid/pull/12177
### Overview and benefits
This introduces a `tree` to the `flattenSpec` which allows faster JSON
parsing than `jq` and `path` parsing types in the event that a simple
hierarchical lookup is required.
For one of our high-volume ingestion tasks, this reduces middle manager CPU
load by 25%. This task presently has 3 `root` fields and 8 additional `path`
fields of the form
```
{
"type": "path",
"name": "task_detail",
"expr": "$.metadata.detail"
},
```
Replacing this with a hierarchical lookup as follows:
```
{
"type": "tree",
"name": "task_detail",
"exprs": ["metadata", "detail"]
},
```
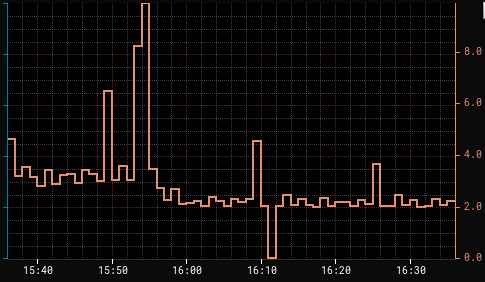
In this sample, a switch to the new `tree` spec is submitted at 15.54, and
after a moment or two the CPU shifts down at a notably lower total utilization
from 3 cores to 2.3 cores.
### Implementation decision
The goal is to introduce the ability to (1) provide a list of expressions
instead of a single expression, and, a new `tree` type.
```
{
"type": "tree", <-- new type
"name": "task_detail",
"exprs": ["metadata", "detail"] <-- name of json keys to traverse as a
List<String>
},
```
The crux of the change is this tree extractor for loop (below) and the
requisite parser configuration to ensure it is called.
```
public Function<JsonNode, Object> makeJsonTreeExtractor(final List<String>
exprs)
{
String[] exprsArray = exprs.toArray(new String[0]);
return node -> {
JsonNode target = node;
for (String expr : exprsArray) {
target = target.get(expr);
if (target == null) {
break;
}
}
return valueConversionFunction(target);
};
}
```
Key consideration was to avoid any backwards compatibility issues with
deployments, so I opted for using a separate `exprs` parameter rather than
overload the `expr` parameter.
### Changes required
The change adds enum entries, the required field spec to parse `List<String>
exprs` to configuration, and validate that `exprs` is only provided for the
`tree` type.
Then, tie it all into the `ObjectFlatteners` and `JSONFlattenerMaker` with a
new `makeJsonTreeExtractor` that iterates each of the keys as a hierarchy in
the dataset.
#### Supporting changes
- Update a lot of tests to explicitly verify the parameters are loaded.
- Update `docs/ingestion-data-formats.md` to include a description of the
`tree` type and the `exprs` parameter.
- Update Avro, Orc, and Parquet flatteners to acknowledge `tree` but only
work with a depth of 1; (would welcome guidance here).
- Added benchmarks to `FlattenJSONBenchmark` to confirm improvements in
flattener layer
### Additional supporting data
On flamegraphs, `Flattener` related code before the change makes up ~49% of
the `task-runner-xx` threads utilisation; after the change only ~16% of the
`task-runner-xx` thread is used running `Flattener` related code.
<hr>
This PR has:
- [x] been self-reviewed.
- [x] added documentation for new or modified features or behaviors.
- [x] added Javadocs for most classes and all non-trivial methods. Linked
related entities via Javadoc links.
- [ ] N/A added or updated version, license, or notice information in
[licenses.yaml](https://github.com/apache/druid/blob/master/dev/license.md)
- [ ] N/A added comments explaining the "why" and the intent of the code
wherever would not be obvious for an unfamiliar reader.
- [x] added unit tests or modified existing tests to cover new code paths,
ensuring the threshold for [code
coverage](https://github.com/apache/druid/blob/master/dev/code-review/code-coverage.md)
is met.
- [ ] added integration tests.
- [x] been tested in a test Druid cluster.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}