harishraju-govindaraju opened a new issue #4745: URL: https://github.com/apache/hudi/issues/4745
**_Tips before filing an issue_** - Have you gone through our [FAQs](https://hudi.apache.org/learn/faq/)? - Join the mailing list to engage in conversations and get faster support at [email protected]. - If you have triaged this as a bug, then file an [issue](https://issues.apache.org/jira/projects/HUDI/issues) directly. **Describe the problem you faced** Bulk Insert is very slow. Our source folder is stored as CSV Gzip and we are reading this to load into Hudi Managed table. Not sure where the time is taken. Can some one please educate me if this is taking time to read or to write to hudi ? 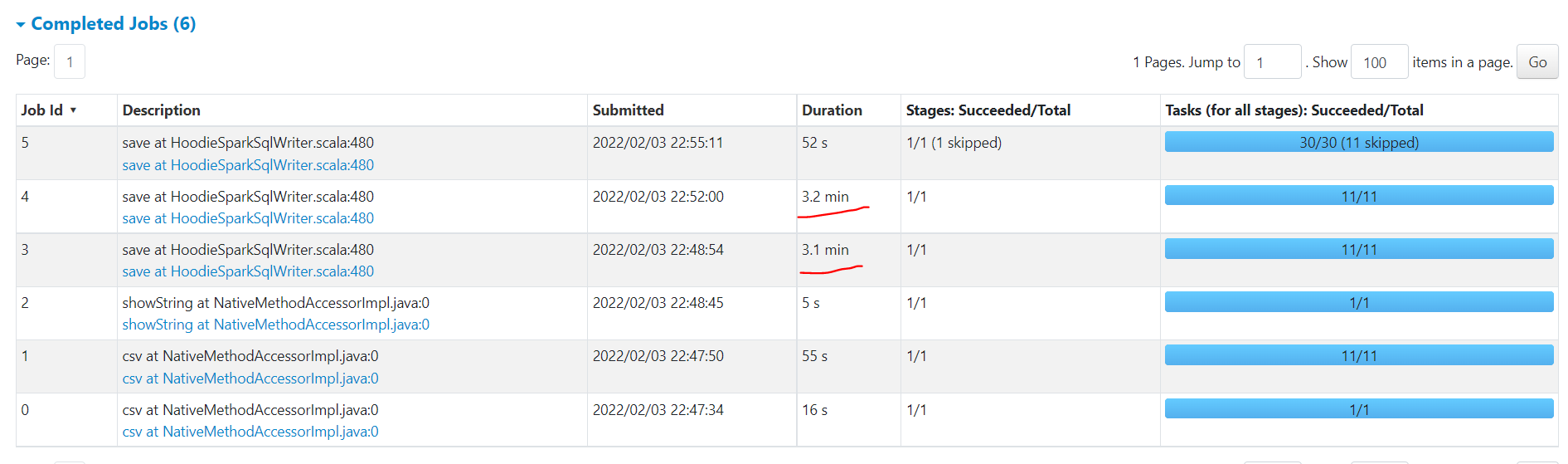  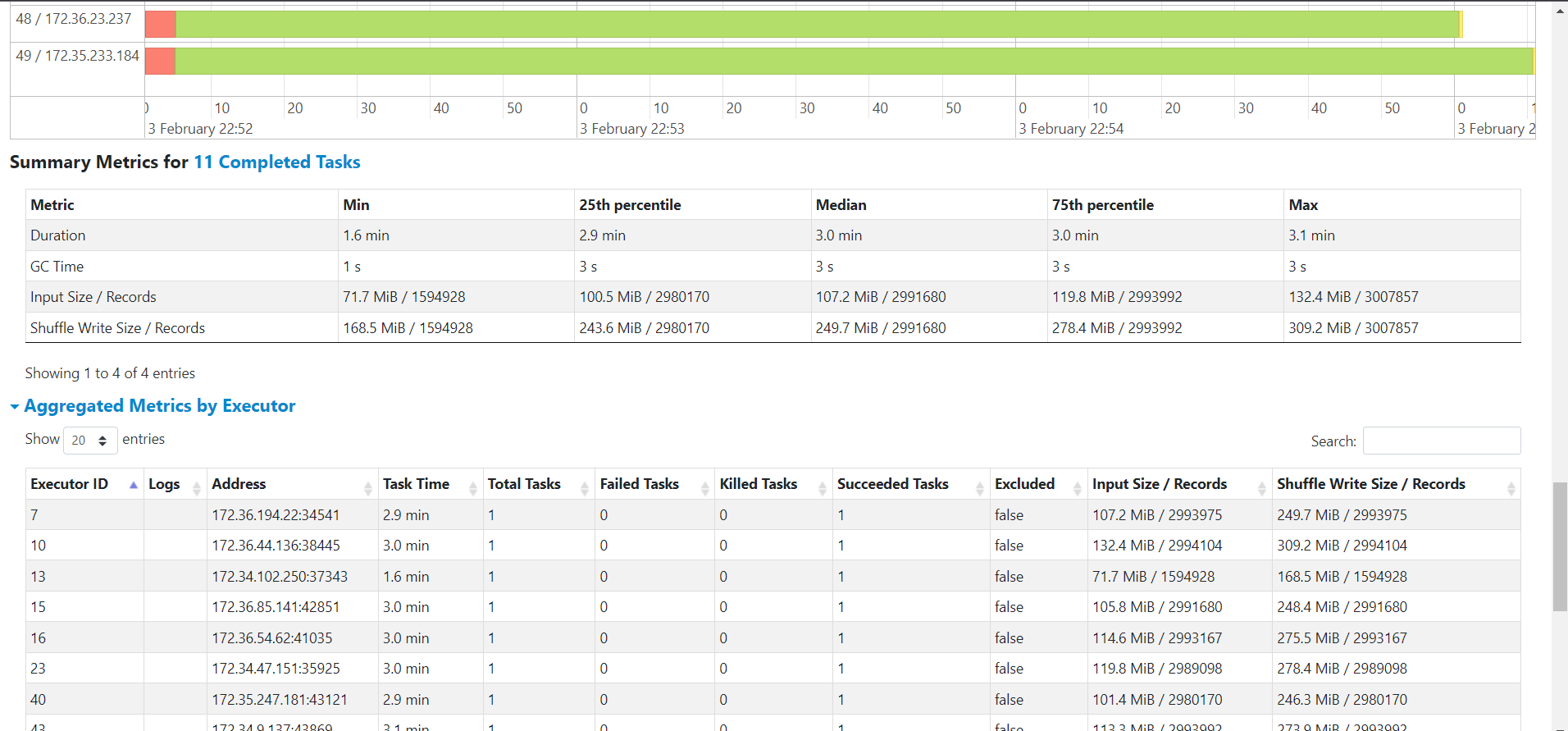 A clear and concise description of the problem. **To Reproduce** Steps to reproduce the behavior: 1. 2. 3. 4. **Expected behavior** A clear and concise description of what you expected to happen. **Environment Description** We are using GLue 3.0 Pyspark to run this code via Hudi Spark Datrasource. commonConfig = { 'className' : 'org.apache.hudi', 'hoodie.datasource.hive_sync.use_jdbc':'false', 'hoodie.datasource.write.precombine.field': 'key', 'hoodie.datasource.write.recordkey.field': 'key', 'hoodie.table.name': 'bw_mdtb', 'hoodie.consistency.check.enabled': 'true', 'hoodie.datasource.hive_sync.database': 'hudidb', 'hoodie.datasource.hive_sync.table': 'bw_mdtb', 'hoodie.datasource.hive_sync.mode': 'hms', 'hoodie.datasource.hive_sync.enable': 'true', 'path': args['target_folder'] + '/bw_mdtb', 'hoodie.parquet.small.file.limit':'134217728', 'hoodie.parquet.max.file.size':'268435456', 'hoodie.bulkinsert.shuffle.parallelism':'20000' } **Additional context** Add any other context about the problem here. **Stacktrace** ```Add the stacktrace of the error.``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}