harishraju-govindaraju edited a comment on issue #4745: URL: https://github.com/apache/hudi/issues/4745#issuecomment-1032156623
@harsh1231 @nsivabalan Here are some updates. I have upload initial load to an unpartitioned table with 1.5 billion records in 45 mins. Which seem ok to me given the number of records. However, when i try to do an Upsert of one 50 MB parquet file as delta, it takes some where between 17 mins to 22 mins to load the deltas. This is what is concerning us as to why the delta updates are so slow. We are not sure if this is due to unpartitioned datasets or are we missing or using wrong type of index. In production, we would offcourse use partition, but for this use case we wanted to load to unpartitioned data sets. Please guide me where this performance could be improved. I also see a lot of spill on memory and disk. here are the stages. In that a particular stage took 9.5 mins 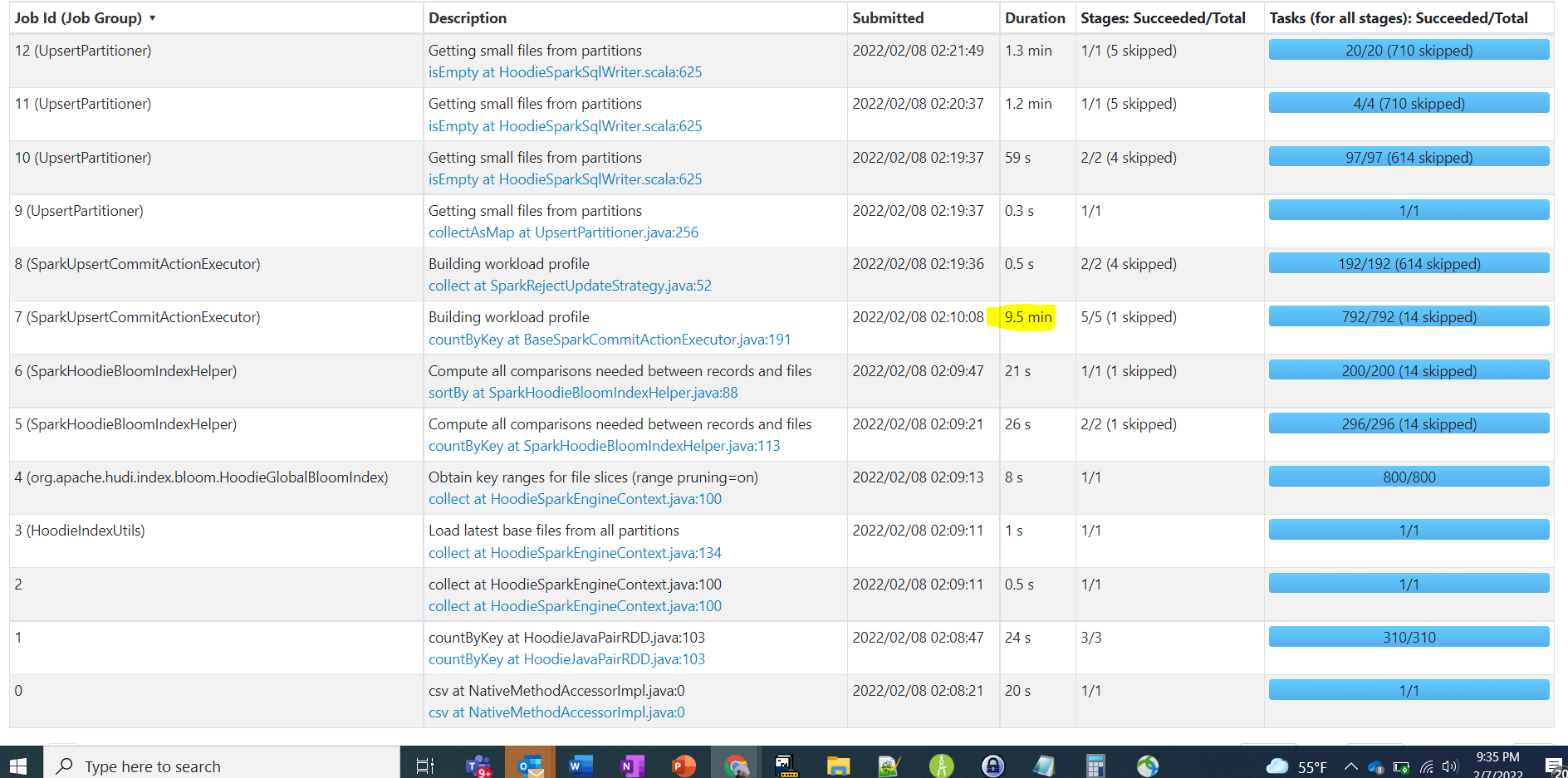 Below picture shows the spill 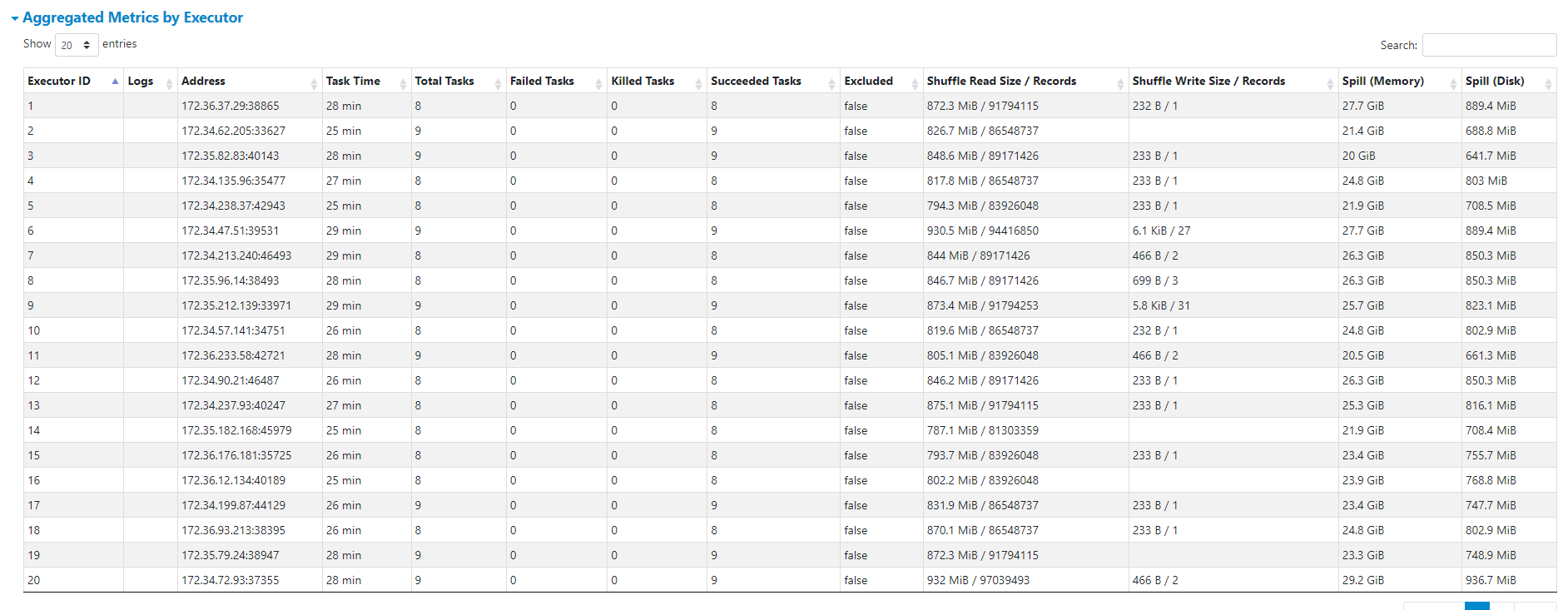 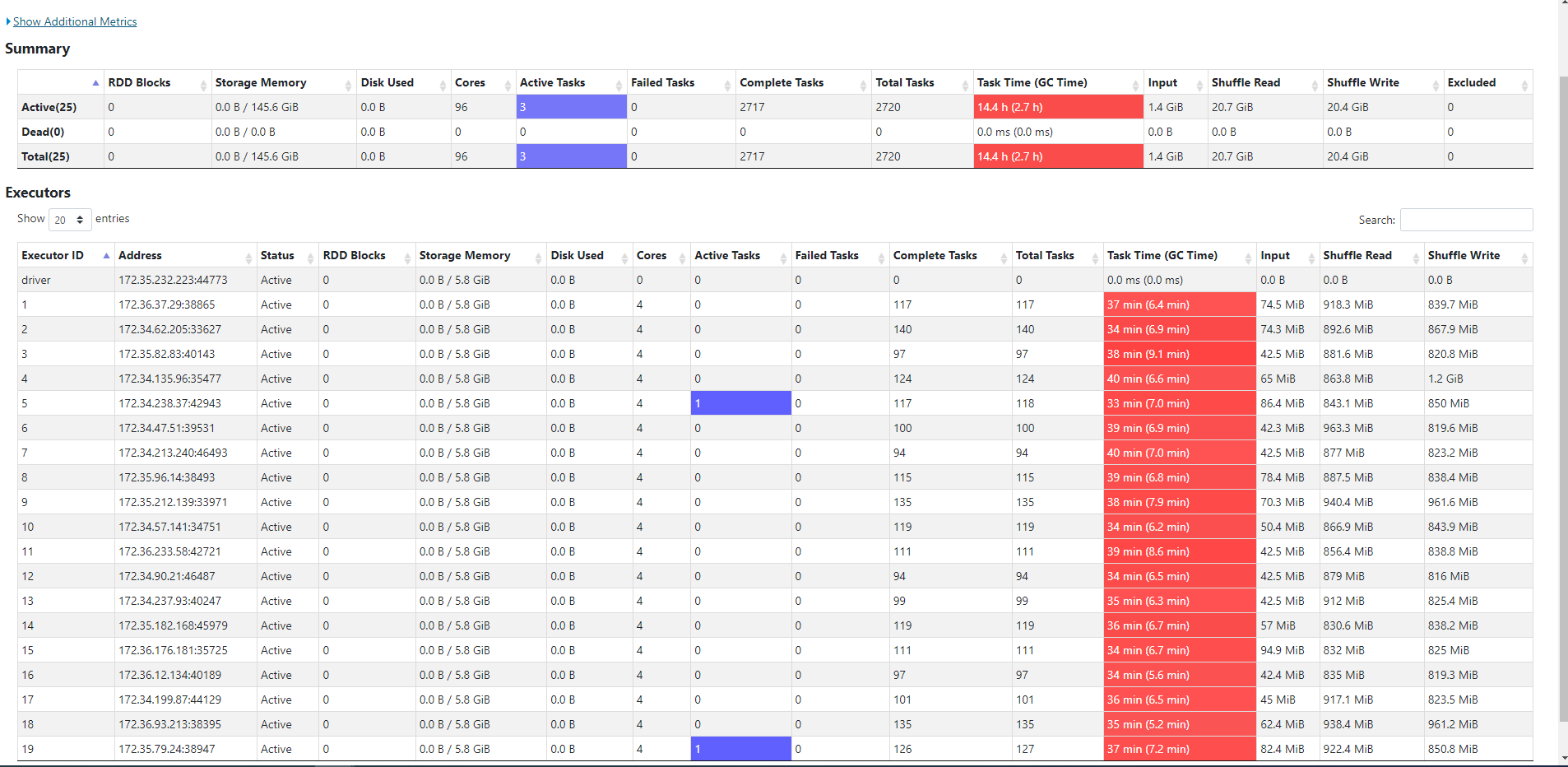 Here are the config i used. commonConfig = { 'className' : 'org.apache.hudi', 'hoodie.index.type': 'GLOBAL_BLOOM', 'hoodie.datasource.hive_sync.use_jdbc':'false', 'hoodie.datasource.write.precombine.field': 'EXTRACTED_ON', 'hoodie.datasource.write.recordkey.field': 'key', 'hoodie.table.name': 'unparition', 'hoodie.consistency.check.enabled': 'true', 'hoodie.datasource.hive_sync.database': 'hudidb', 'hoodie.datasource.hive_sync.table': 'unparition', 'hoodie.datasource.hive_sync.mode': 'hms', 'hoodie.datasource.hive_sync.enable': 'true', 'path': args['target_folder'] + '/unparition', 'hoodie.bulkinsert.sort.mode':'NONE', 'hoodie.bloom.index.bucketized.checking':'false' } unpartitionDataConfig = { 'hoodie.datasource.hive_sync.partition_extractor_class': 'org.apache.hudi.hive.NonPartitionedExtractor', 'hoodie.datasource.write.keygenerator.class': 'org.apache.hudi.keygen.NonpartitionedKeyGenerator'} incrementalConfig = {'hoodie.datasource.write.operation': 'upsert'} -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}