koochiswathiTR opened a new issue, #7708: URL: https://github.com/apache/hudi/issues/7708
Hi, We ingest data using spark streaming to hudi buckets. - Have you gone through our [FAQs](https://hudi.apache.org/learn/faq/)? - Join the mailing list to engage in conversations and get faster support at [email protected]. - If you have triaged this as a bug, then file an [issue](https://issues.apache.org/jira/projects/HUDI/issues) directly. We see parquet files size which are created by hudi is sometimes 1.8MB. How to increase parquet size creation? What is the default parquet file size that hudi creates? A clear and concise description of the problem. **To Reproduce** 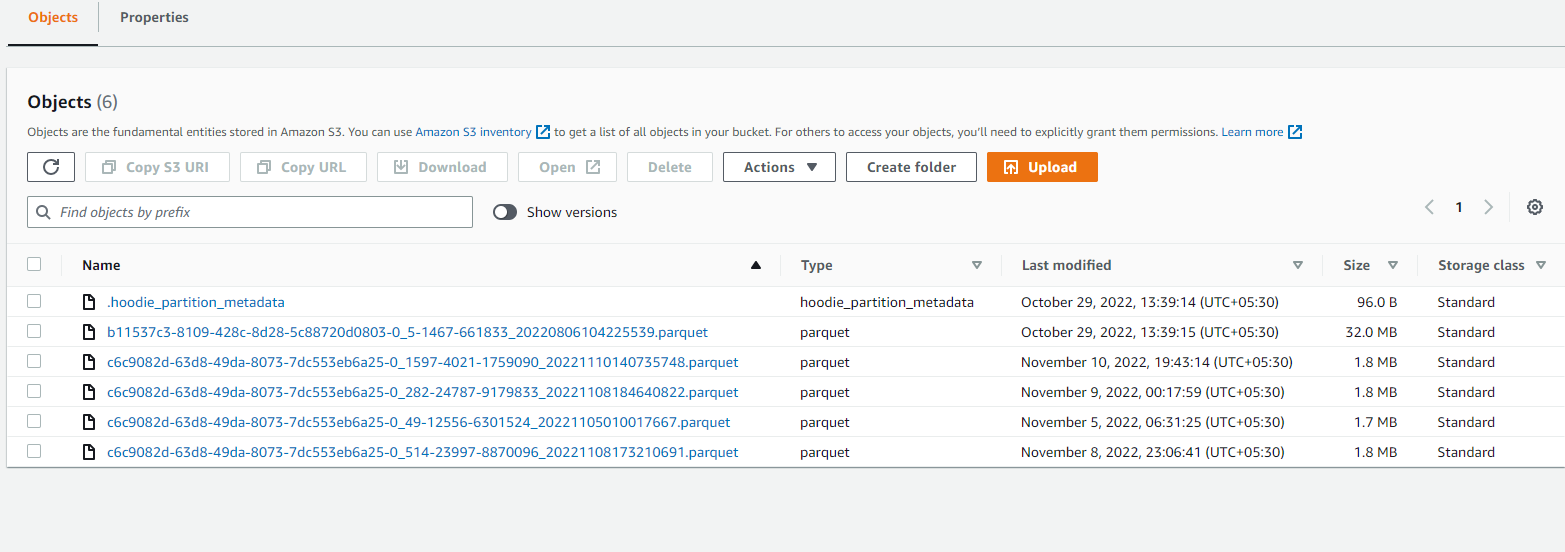 * A clear and concise description of what you expected to happen. PROD AND QA * Hudi version : 0.11 * Spark version : 3.2.1 * Hive version : NA * Storage (HDFS/S3/GCS..) : S3 * Running on Docker? (yes/no) :NO -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}