tomyanth opened a new issue, #8670:
URL: https://github.com/apache/hudi/issues/8670
**Describe the problem you faced**
Actually I raise my issues under case #7653 because I have almost the same
issue with that original question which is
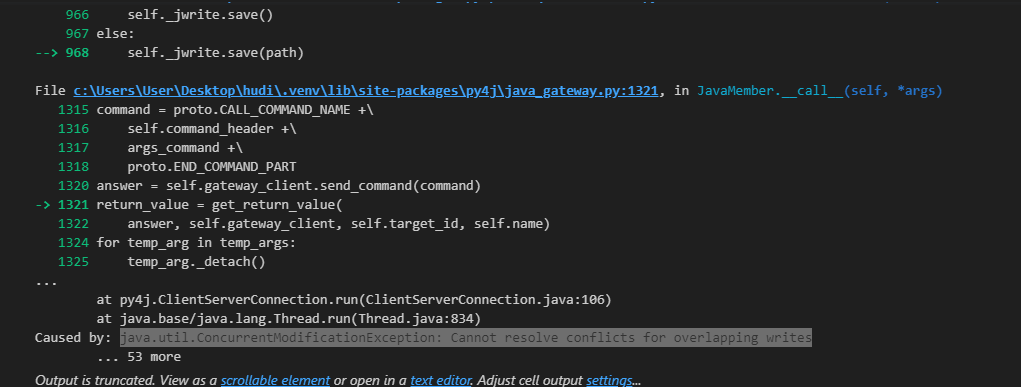
java.util.ConcurrentModificationException: Cannot resolve conflicts for
overlapping writes
**To Reproduce**
Steps to reproduce the behavior:
1. Run 2 hudi job to write the same location to simulate the process of
multi write
2. If set to overwrite, both job fails
3. If set to append, at most one job succeed.
4. With or without the multi-write setting suggest below, at most only one
job succeed but the error message is different
hudi_options = {
'hoodie.table.name': table_name,
'hoodie.datasource.write.recordkey.field': 'emp_id',
'hoodie.datasource.write.table.name': table_name,
'hoodie.datasource.write.operation': 'upsert',
'hoodie.datasource.write.precombine.field': 'ts',
'hoodie.upsert.shuffle.parallelism': 2,
'hoodie.insert.shuffle.parallelism': 2,
'hoodie.schema.on.read.enable' : 'true', # for changing column names
'hoodie.write.concurrency.mode':'optimistic_concurrency_control',
#added for zookeeper to deal with multiple source writes
'hoodie.cleaner.policy.failed.writes':'LAZY',
#
'hoodie.write.lock.provider':'org.apache.hudi.client.transaction.lock.FileSystemBasedLockProvider',
'hoodie.write.lock.provider':'org.apache.hudi.client.transaction.lock.ZookeeperBasedLockProvider',
'hoodie.write.lock.zookeeper.url':'localhost',
'hoodie.write.lock.zookeeper.port':'2181',
'hoodie.write.lock.zookeeper.lock_key':'my_lock',
'hoodie.write.lock.zookeeper.base_path':'/hudi_locks',
}
**Expected behavior**
I expect at least FileSystemBasedLockProvider wll be able to perform
multi-write but unfortunately the same error message
java.util.ConcurrentModificationException: Cannot resolve conflicts for
overlapping writes always pops up.
Code run
"""
Install
https://dlcdn.apache.org/spark/spark-3.3.1/spark-3.3.1-bin-hadoop2.tgz
hadoop2.7
https://github.com/soumilshah1995/winutils/blob/master/hadoop-2.7.7/bin/winutils.exe
pyspark --packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.1 --conf
'spark.serializer=org.apache.spark.serializer.KryoSerializer'
VAR
SPARK_HOME
HADOOP_HOME
PATH
`%HAPOOP_HOME%\bin`
`%SPARK_HOME%\bin`
Complete Tutorials on HUDI
https://github.com/soumilshah1995/Insert-Update-Read-Write-SnapShot-Time-Travel-incremental-Query-on-APache-Hudi-transacti/blob/main/hudi%20(1).ipynb
"""
import os
import sys
import uuid
import pyspark
from pyspark.sql import SparkSession
from pyspark import SparkConf, SparkContext
from pyspark.sql.functions import col, asc, desc
from pyspark.sql.functions import col, to_timestamp,
monotonically_increasing_id, to_date, when
from pyspark.sql.functions import *
from pyspark.sql.types import *
from datetime import datetime
from functools import reduce
from faker import Faker
from faker import Faker
import findspark
import datetime
time = datetime.datetime.now()
time = time.strftime("YMD%Y%m%dHHMMSSms%H%M%S%f")
SUBMIT_ARGS = "--packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.1
pyspark-shell"
os.environ["PYSPARK_SUBMIT_ARGS"] = SUBMIT_ARGS
os.environ['PYSPARK_PYTHON'] = sys.executable
os.environ['PYSPARK_DRIVER_PYTHON'] = sys.executable
findspark.init()
spark = SparkSession.builder\
.config('spark.serializer',
'org.apache.spark.serializer.KryoSerializer') \
.config('className', 'org.apache.hudi') \
.config('spark.sql.hive.convertMetastoreParquet', 'false') \
.config('spark.sql.extensions',
'org.apache.spark.sql.hudi.HoodieSparkSessionExtension') \
.config('spark.sql.warehouse.dir', 'file:///C:/tmp/spark_warehouse') \
.getOrCreate()
global faker
faker = Faker()
class DataGenerator(object):
@staticmethod
def get_data():
return [
(
x,
faker.name(),
faker.random_element(elements=('IT', 'HR', 'Sales',
'Marketing')),
faker.random_element(elements=('CA', 'NY', 'TX', 'FL', 'IL',
'RJ')),
faker.random_int(min=10000, max=150000),
faker.random_int(min=18, max=60),
faker.random_int(min=0, max=100000),
faker.unix_time()
) for x in range(5)
]
data = DataGenerator.get_data()
columns = ["emp_id", "employee_name", "department", "state", "salary",
"age", "bonus", "ts"]
spark_df = spark.createDataFrame(data=data, schema=columns)
print(spark_df.show())
db_name = "hudidb"
table_name = "hudi_table"
recordkey = 'emp_id'
precombine = 'ts'
path = "file:///C:/tmp/spark_warehouse"
method = 'upsert'
table_type = "COPY_ON_WRITE"
hudi_options = {
'hoodie.table.name': table_name,
'hoodie.datasource.write.recordkey.field': 'emp_id',
'hoodie.datasource.write.table.name': table_name,
'hoodie.datasource.write.operation': 'upsert',
'hoodie.datasource.write.precombine.field': 'ts',
'hoodie.upsert.shuffle.parallelism': 2,
'hoodie.insert.shuffle.parallelism': 2,
'hoodie.schema.on.read.enable' : 'true', # for changing column names
'hoodie.write.concurrency.mode':'optimistic_concurrency_control',
#added for zookeeper to deal with multiple source writes
'hoodie.cleaner.policy.failed.writes':'LAZY',
#
'hoodie.write.lock.provider':'org.apache.hudi.client.transaction.lock.FileSystemBasedLockProvider',
'hoodie.write.lock.provider':'org.apache.hudi.client.transaction.lock.ZookeeperBasedLockProvider',
'hoodie.write.lock.zookeeper.url':'localhost',
'hoodie.write.lock.zookeeper.port':'2181',
'hoodie.write.lock.zookeeper.lock_key':'my_lock',
'hoodie.write.lock.zookeeper.base_path':'/hudi_locks',
}
print("*"*55)
print("over-write")
print("*"*55)
spark_df.write.format("hudi"). \
options(**hudi_options). \
mode("overwrite"). \
save(path)
print("*"*55)
print("READ")
print("*"*55)
read_df = spark.read. \
format("hudi"). \
load(path)
print(read_df.show())
---------- Cell split
-----------------------------------------------------------
impleDataUpd = [
(6, "This is APPEND4", "Sales", "RJ", 81000, 30, 23000, 827307999),
(7, "This is APPEND4", "Engineering", "RJ", 79000, 53, 15000,
1627694678),
]
columns = ["emp_id", "employee_name", "department", "state", "salary",
"age", "bonus", "ts"]
usr_up_df = spark.createDataFrame(data=impleDataUpd, schema=columns)
usr_up_df.write.format("hudi").options(**hudi_options).mode("append").save(path)
print("*"*55)
print("READ")
print("*"*55)
read_df = spark.read. \
format("hudi"). \
load(path)
print(read_df.show())
**Environment Description**
local console. Using .ipynb
* Hudi version : 0.12.1
JAVA version : 11
* Spark version : 3.3.1
* Hive version : Not Applicable
* Hadoop version : 2.7.7
* Storage (HDFS/S3/GCS..) : Local console
* Running on Docker? (yes/no) : No
**Additional context**
Add any other context about the problem here.
I hope I don't need to install zookeeper because there is no guide about
which version should be installed and how to set up and connect the zookeeper
to the hudi.
I guess it is not zookeeper's problem because FileSystemBasedLockProvider
should be available in all windows machine as all system should have file
system and no additional parameter is needed for this option according to
hudi's documentation.
As I mentioned both options produce the same error, so I guess this is not
related to zookeeper.
```Add the stacktrace of the error.```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}