kpurella opened a new issue #2240: URL: https://github.com/apache/hudi/issues/2240
**_Tips before filing an issue_** - Have you gone through our [FAQs](https://cwiki.apache.org/confluence/display/HUDI/FAQ)? yes - Join the mailing list to engage in conversations and get faster support at [email protected]. - If you have triaged this as a bug, then file an [issue](https://issues.apache.org/jira/projects/HUDI/issues) directly. **Describe the problem you faced** A clear and concise description of the problem. - We are seeing a strange issue with Hudi's job, as we are trying to write more than a billion updates to the master hudi table which holds 10 billion records. the job got stuck st stage 11 from the below screenshot, and waited forever to complete the write, Eventually, we have to kill the job. 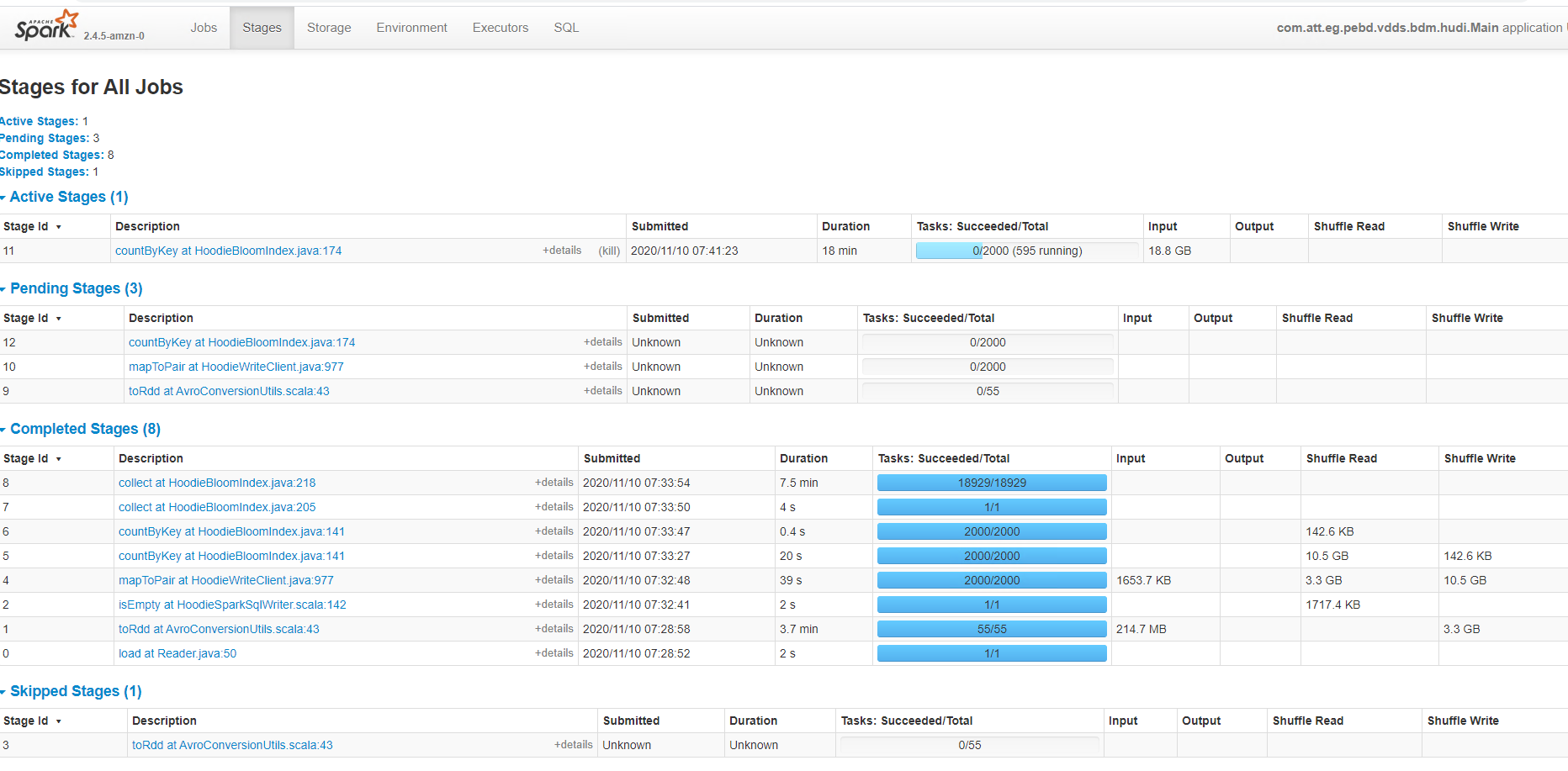 **To Reproduce** Steps to reproduce the behavior: 1.Ingest 10 Billion records ( each record size 1KB ) to hudi table using Bulk insert and MOR 2. try to write 1 Billion updates to the master. 3. 4. **Expected behavior** A clear and concise description of what you expected to happen. - Hudi should complete the update process. as this is a simple hudi job without any transformation. **Environment Description** * Hudi version : 0.5.2incubating/0.6.0 ( tried on both the versions) on EMR * Spark version : 2.4.5/2/4/6 * Hive version : 2.3.6 * Hadoop version :2.8.5/2.10 * Storage (HDFS/S3/GCS..) : S3 * Running on Docker? (yes/no) No **Additional context** Add any other context about the problem here. - I also noticed that hudi is writing small ( 4 MB) files Submit - spark-submit --master yarn --deploy-mode cluster --num-executors 59 --executor-cores 5 --executor-memory 37G --driver-cores 5 --driver-memory 37G --conf spark.yarn.executor.memoryOverhead=4G --conf "spark.executor.extraJavaOptions = -XX:+UseG1GC -XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark -XX:InitiatingHeapOccupancyPercent=35 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:OnOutOfMemoryError='kill -9 %p'" --conf "spark.driver.extraJavaOptions= -XX:+UseG1GC -XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark -XX:InitiatingHeapOccupancyPercent=35 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:OnOutOfMemoryError='kill -9 %p'" --jars /usr/lib/spark/external/lib/spark-avro.jar,/usr/lib/hudi/hudi-spark-bundle.jar --class Main build.jar hudi.properties DataFrameWriter<Row> writer = dsWithPartitionPath.write() .format("org.apache.hudi") .mode(SaveMode.Append) .option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY(), recordKey) .option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY(), partitionKey) .option(DataSourceWriteOptions.OPERATION_OPT_KEY(), operation) .option(HoodieWriteConfig.TABLE_NAME, tableName) .option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY(), tableType) .option(DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY(), hiveSyncEnabled) .option(DataSourceWriteOptions.KEYGENERATOR_CLASS_OPT_KEY(), keyGeneratorClass) .option("hoodie.parquet.compression.codec", "snappy") .option("hoodie.consistency.check.enabled", true) .option("hoodie.compact.inline.max.delta.commits", 10) .option("hoodie.compact.inline", true) .option("hoodie.cleaner.commits.retained", 25) .option("hoodie.keep.min.commits", 30) .option("hoodie.index.type", "GLOBAL_BLOOM") .option("hoodie.insert.shuffle.parallelism", 500) .option("hoodie.upsert.shuffle.parallelism", 500); .option("hoodie.bloom.index.update.partition.path", true) .option(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY(), hiveDBName) .option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY(), hiveTableName) .option(DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY(), hivePartitions) .option(DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY(), extractorClass) .option(DataSourceWriteOptions.HIVE_URL_OPT_KEY(), hiveUrl); writer.save(appConf.getString(Constants.HUDI_BASE_PATH_PROP)); Please suggest how I can tune this job to process updates efficiently. Thank you **Stacktrace** ```Add the stack trace of the error.``` ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}