kpurella commented on issue #2240: URL: https://github.com/apache/hudi/issues/2240#issuecomment-726271983
@bvaradar Thank you for your help- I tried my job with 750 Mill records insert/upsert with SIMPLE index type, I see the initial load was completed in 13 min. but the subsequent jobs were taking long. the time increasing for every run. Please see the below screenshots- First Run -Took 13 min 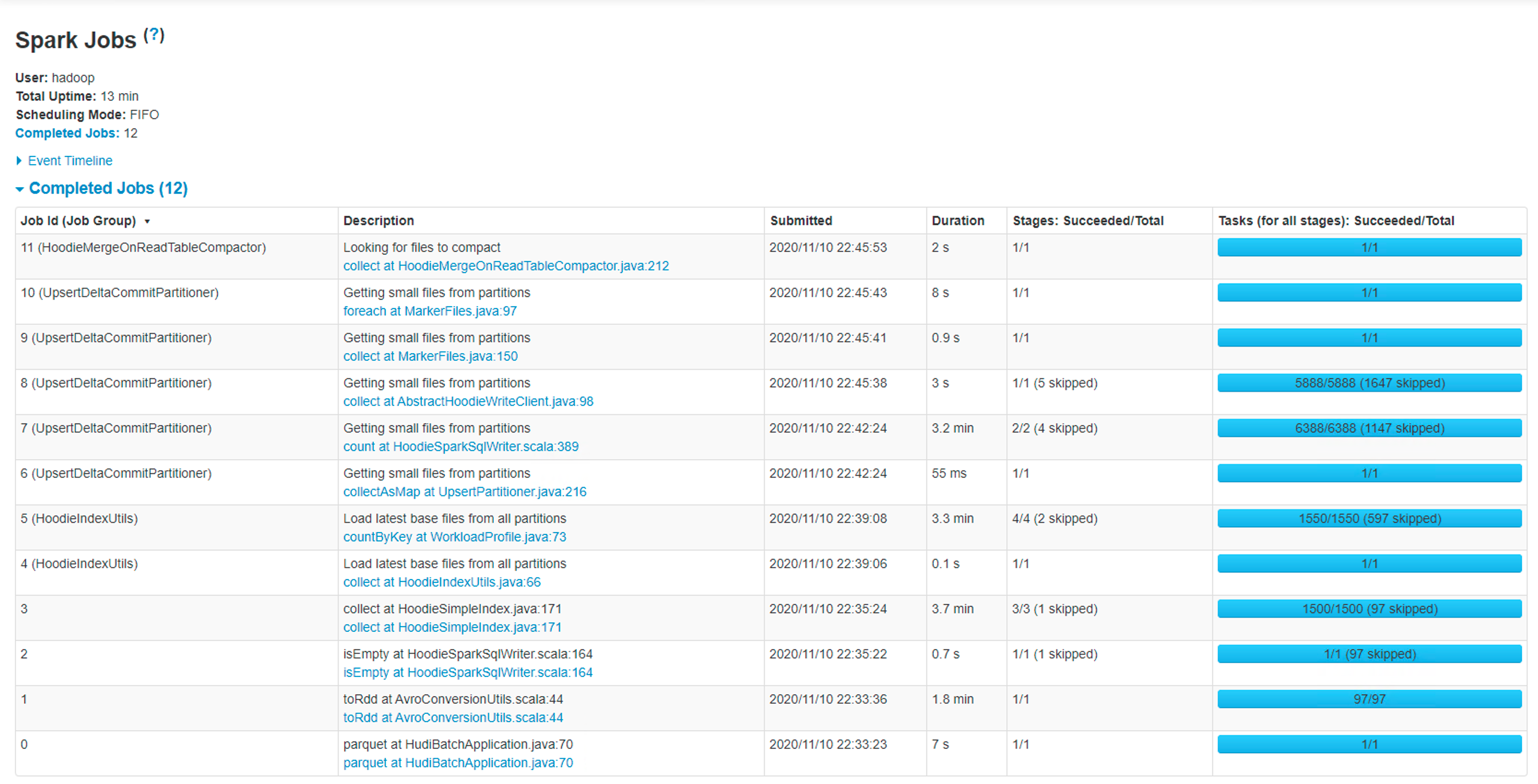 2ndRun Took 20 min 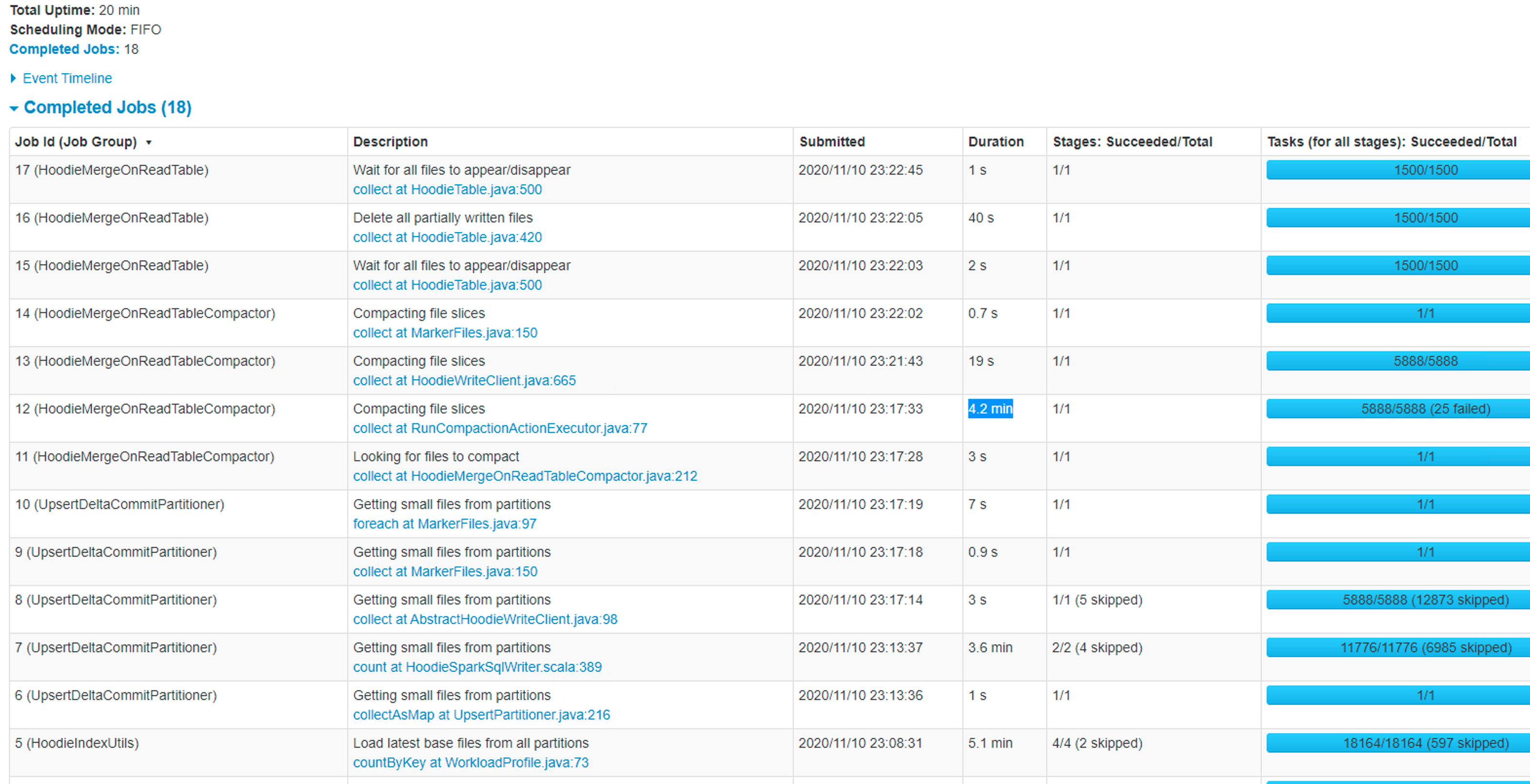 - In this case, it ran compaction due to that total time went up 3rd Run -39 min 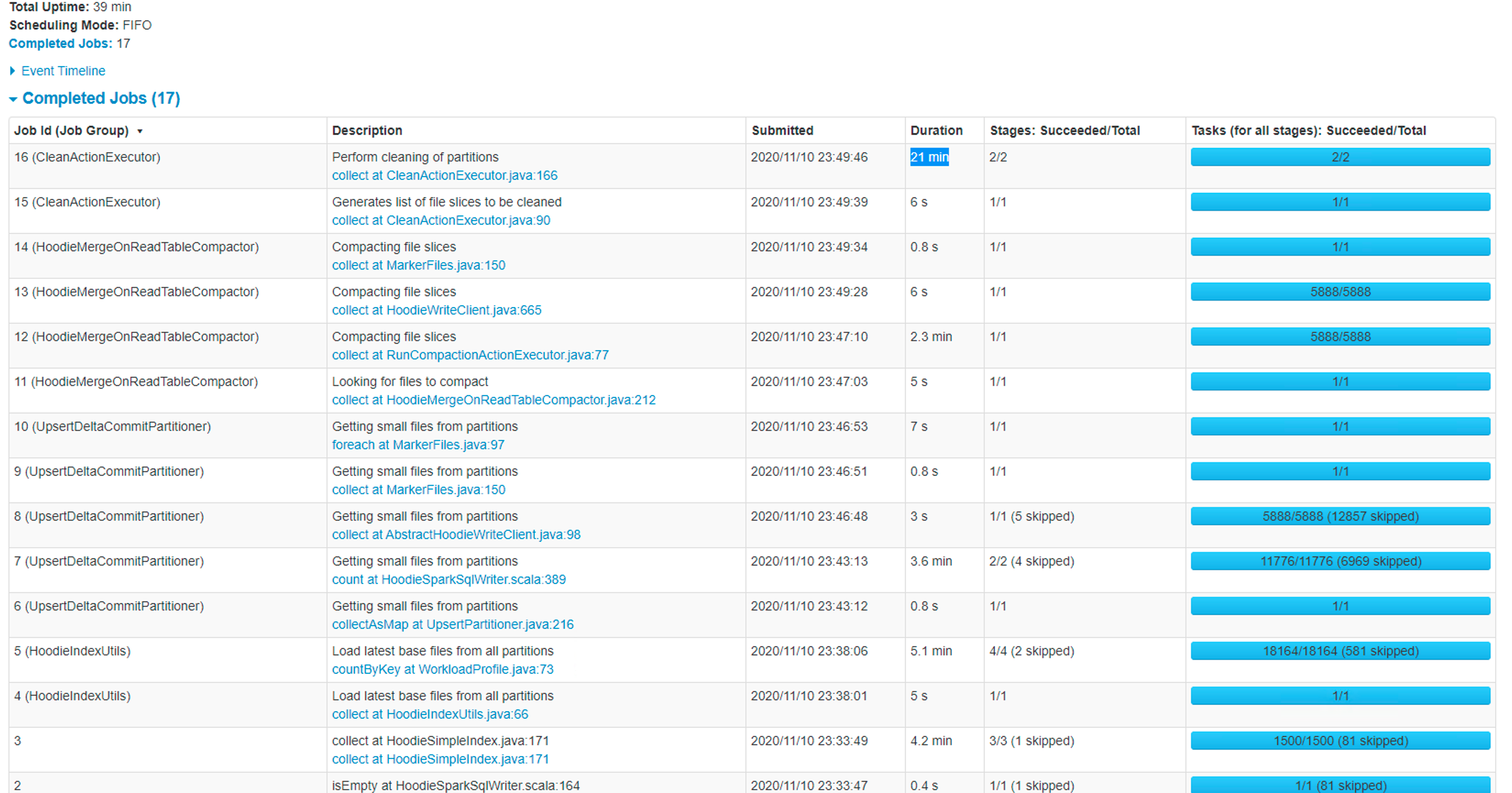 - In this case, Job triggered compaction and cleaning due to that, total time wentup.. but in any case, the job time was increasing over time. the good thing is the job is completing now. how can I tune my job to get an optimal performance and predictable time? - Coming to file size - I still see small files after setting the below attributes- .option("hoodie.parquet.block.size",125829120) .option("hoodie.parquet.small.file.limit",104857600) .option("hoodie.parquet.max.file.size",125829120) - I also see a lot of GC happening in my job- ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}