so-lazy opened a new issue #2338: URL: https://github.com/apache/hudi/issues/2338
I want to have a pipeline consume incremental data from Kafka. first i have a full data import to a hudi mor table size around 23G, When this is done, everything is all right. But when i start consuming incremental data from kafka, it's soooo slow and then when i check the data, i found much duplicate records, but i used GLOBAL_BOOM, from the doc i saw this. So i think if i got the same record key, then no need to worry about the duplicate. > /** > * Only applies if index type is GLOBAL_BLOOM. > * <p> > * When set to true, an update to a record with a different partition from its existing one > * will insert the record to the new partition and delete it from the old partition. > * <p> > * When set to false, a record will be updated to the old partition. > */ And u see just a little bit data, it process so slowly, need your help @bvaradar , thanks sooo much. 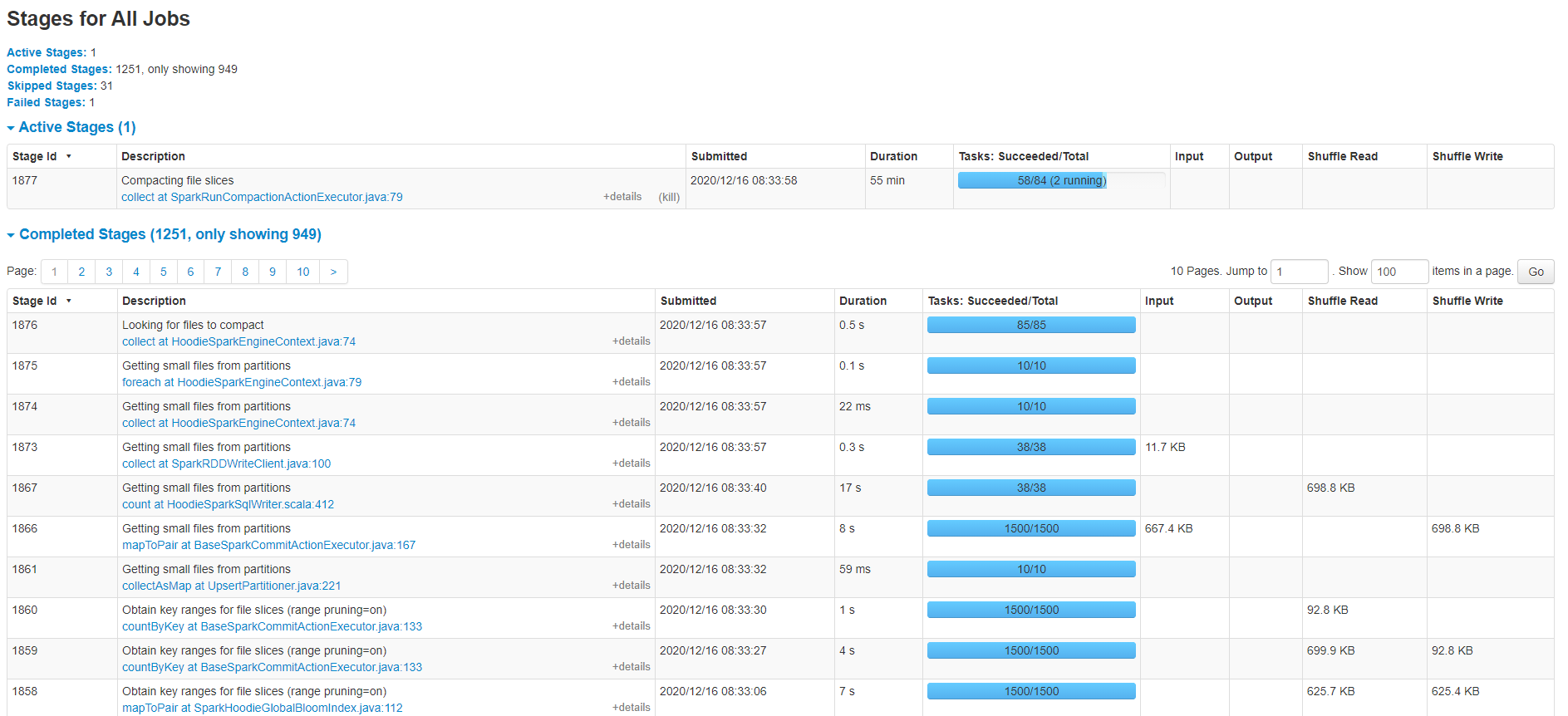 Here is my option: ``` hoodie.datasource.write.recordkey.field -> "id" hoodie.datasource.write.precombine.field -> "_ts" hoodie.datasource.write.partitionpath.field -> "dt" hoodie.datasource.write.table.type -> "MERGE_ON_READ" hoodie.datasource.hive_sync.database -> "schema" hoodie.datasource.hive_sync.table -> "table" hoodie.datasource.hive_sync.enable -> "true" hoodie.datasource.hive_sync.jdbcurl -> "jdbc:hive2://xxxxxxx" hoodie.table.name -> "table" hoodie.datasource.hive_sync.partition_extractor_class -> "org.apache.hudi.hive.MultiPartKeysValueExtractor" hoodie.index.type -> "GLOBAL_BLOOM" hoodie.datasource.hive_sync.partition_fields -> "dt" hoodie.compact.inline -> "true" hoodie.parquet.small.file.limit -> "104857600" ``` * Hudi version : 0.6 * Spark version : 2.4.6 * Hive version : 3.1.2 * Hadoop version : 3.1.2 * Storage (HDFS/S3/GCS..) : HDFS * Running on Docker? (yes/no) : no ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}