peng-xin commented on issue #2338: URL: https://github.com/apache/hudi/issues/2338#issuecomment-751994816
> I run `select id,count(1) from table_ro group by id having count(1) > 1` got this > 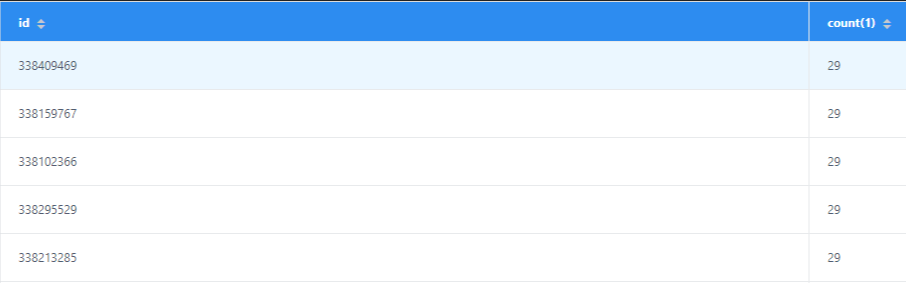 > > then i query data by id got this > 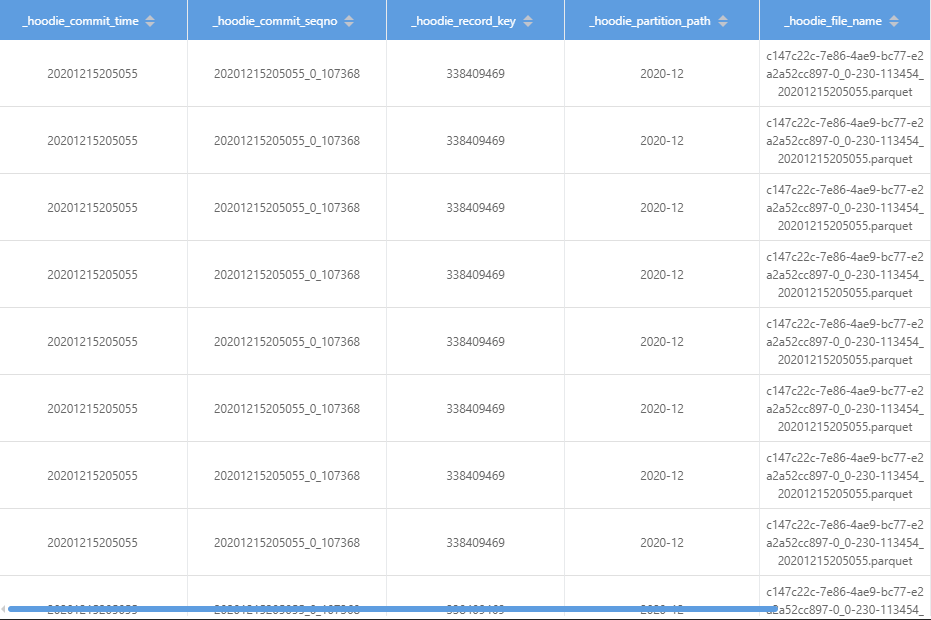 > > then i go to check the parquet file > `val df = spark.read.parquet("/hudi/2020-12/c147c22c-7e86-4ae9-bc77-e2a2a52cc897-0_0-230-113454_20201215205055.parquet") df.createOrReplaceTempView("table") spark.sql("select _hoodie_commit_time,_hoodie_commit_seqno,_hoodie_record_key,_hoodie_partition_path,_hoodie_file_name,id from table WHERE id = 338409469").show` > 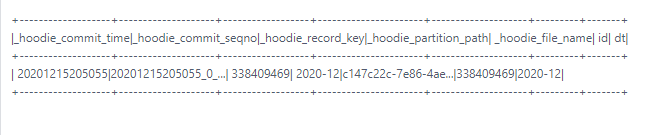 when you use spark-sql,you can try `set spark.sql.hive.convertMetastoreParquet = false`; I ran into the same problem before yesterday ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}