vinothchandar commented on a change in pull request #4404:
URL: https://github.com/apache/hudi/pull/4404#discussion_r773607065
##########
File path:
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/execution/bulkinsert/RDDCustomColumnsSortPartitioner.java
##########
@@ -54,9 +55,9 @@ public RDDCustomColumnsSortPartitioner(String[] columnNames,
Schema schema) {
int
outputSparkPartitions) {
final String[] sortColumns = this.sortColumnNames;
final SerializableSchema schema = this.serializableSchema;
- return records.sortBy(
+ return CustomJavaRDD.fromRDD(records,records.classTag()).sortBy(
Review comment:
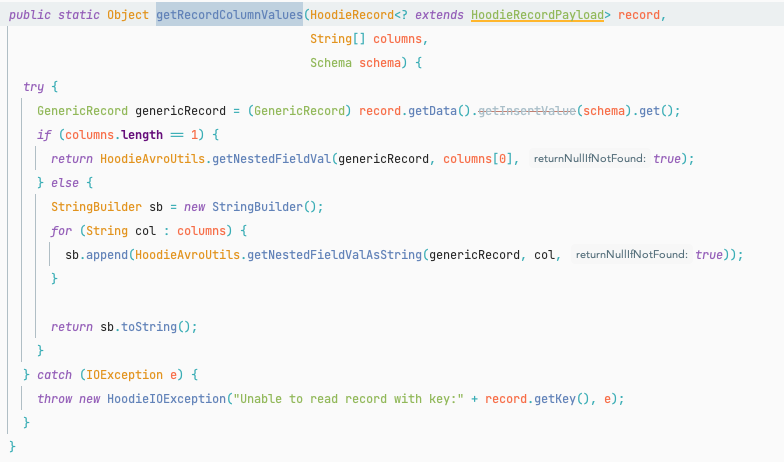
Definitely seems to be returning a string. I think we should sort
lexicographically the byte representation if you ask me. So if we can could map
`null` deterministically to some string/byte and avoid this customization, I'd
prefer that.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}