kevinthesun commented on pull request #6066: URL: https://github.com/apache/incubator-tvm/pull/6066#issuecomment-667826737
> > One thing I think it is good to have in this PR is to get some benchmark data, since we now enable this pass by default. IMO this pass is especially valuable when tackling dynamic kernels in GPU which introduces a lot of branchings. It's great to see how much performance improvement we can have. For CPU, we need to make sure this pass doesn't introduce regression for some common workloads, such as resnet. > > @kevinthesun : I have verified the inference time for Resnet50 on CPU. There is no performance impact. In fact i did not find anything as Hoisting candidate. > > ### Hoisting Disabled : > 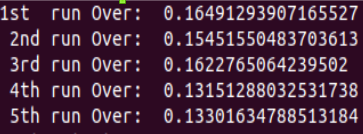 > > ### Hoisting Enabled: > 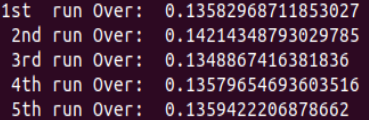 > > Hope it helps. Please let me know, if i have mistaken anything. TIA! Usually there are two cases which might involve this pass: 1) Loop tiling with non-factor split. 2) Dynamic shape op. If I remember correctly, a conv2d with symbolic batch size will generate an IR with a lot of hoist candidates. Due to the limitation of nvcc, performance for such as kernel is quite terrible and this pass is able to handle this. It would be nice if we can verify this case for GPU and add a unit test. ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}