yzh119 commented on code in PR #100: URL: https://github.com/apache/tvm-rfcs/pull/100#discussion_r1160923732
########## rfcs/0100-sparestir-dialect.md: ########## @@ -0,0 +1,658 @@ +- Feature Name: SparseTIR Dialect +- Start Date: 2023-03-31 +- RFC PR: [apache/tvm-rfcs#0100](https://github.com/apache/tvm-rfcs/pull/0100) +- Discussion forum: [#14645](https://discuss.tvm.apache.org/t/rfc-sparsetir-as-a-new-dialect-in-tvm/14645) + +# Summary +[summary]: #summary + +This RFC proposes a plan for integrating SparseTIR as a new dialect into TVM. + +# Motivation +[motivation]: #motivation + +## N0: No Sparse Support in TVM +Many Deep Learning workloads involve sparse/variable components, e.g. Mixture of Experts, Network Pruning, GNNs, and Sparse Conv. Currently, if users want to write these operators in TVM, they need to compose them with IRBuilder, which is not scalable and cannot be specified schedules. + +[SparseTIR](https://dl.acm.org/doi/10.1145/3582016.3582047) is our attempt at bringing sparsity to TVM, the basic idea is to build a dialect on top of TVM's TensorIR, and adding sparse annotations (inspired by TACO and other pioneering works in sparse compilers) as first-class members to describe formats for sparse tensors and sparse iterations. SparseTIR designs a multi-stage compilation process whose frontend IR is TACO-like sparse computation description and target IR is TensorIR: + +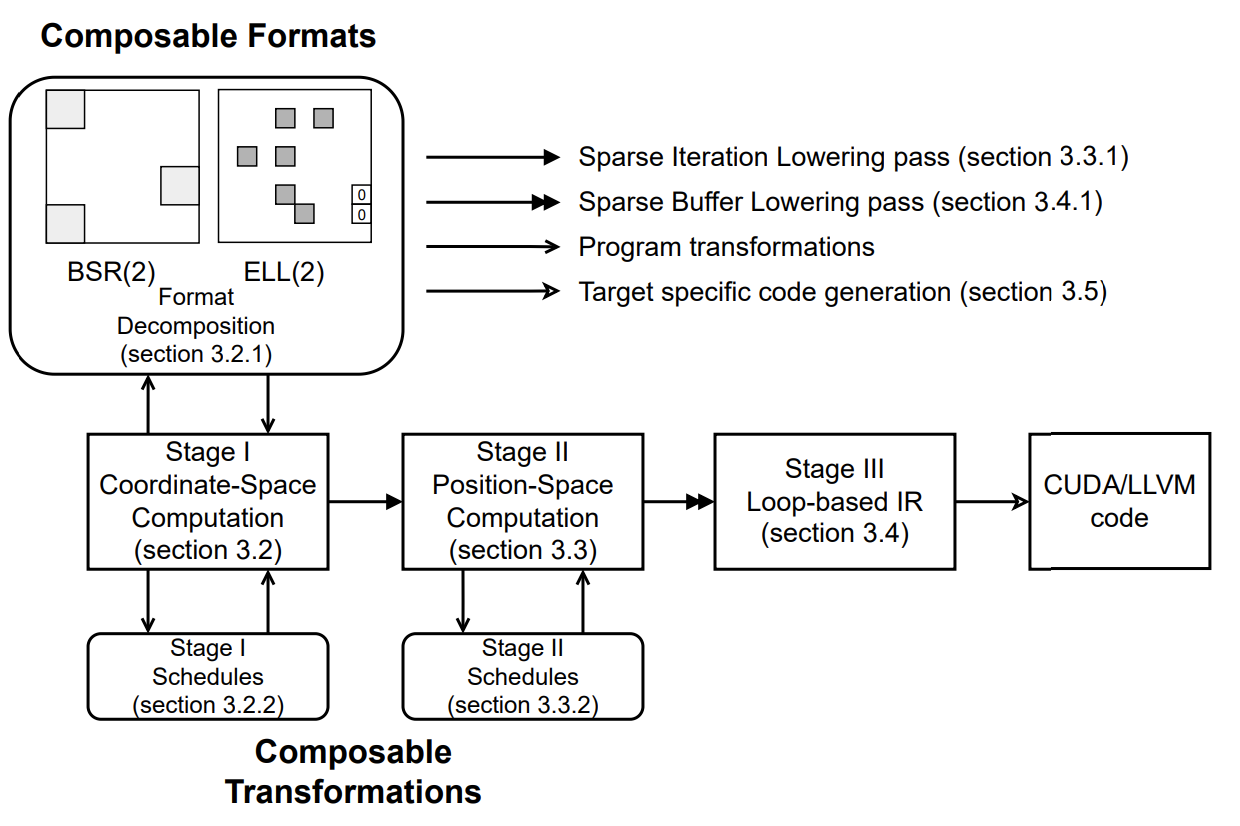 + +## N1: Sparsity-Aware Optimizations and Hardware-Aware Optimizations for Sparse Operators +A lot of optimizations and generalizations can be done under this framework. Notably composable formats and composable transformations: we can decompose the computation into several different formats where each one of them in different formats (usually more hardware friendly), and optimize computation on each one of these formats. The multi-stage design enables us to apply schedule primitives in different stages, at both high-level (stage-I) for sparsity-aware transformations and lower-level (stage-II) to reuse TVM's schedule primitives. + +# Guide-level Explanation +[guide-level-explaination]: #guide-level-explaination + +We have the following design goals of SparseTIR: + +- G0: SparseTIR is consistent with TVM's ecosystem, which means other components of TVM stack (Relax/Relay/TOPI) +can interact with SparseTIR smoothly, and enjoy of the benefits of SparseTIR. +- G1: SparseTIR is expressive, which means we can express most sparse operators in Deep Learning with SparseTIR. +- G2: SparseTIR is performant, which means we can cover optimizations used in Sparse CPU/GPU libraries. + +We will outline the detailed design in the next section. + +# Reference-level explanation +[reference-level-explanation]: #reference-level-explanation + +This section outlines the design of SparseTIR, and its interaction with existing components in TVM. + +## D0: Programming Interface + +A generic SparseTIR program looks like the following, the workload is Sampled-Dense-Dense-Matrix-Multiplication (SDDMM): + +```python [email protected]_func +def sddmm( + a: T.handle, + b: T.handle, + x: T.handle, + y: T.handle, + indptr: T.handle, + indices: T.handle, + m: T.int32, + n: T.int32, + feat_size: T.int32, + nnz: T.int32, +) -> None: + T.func_attr({"global_symbol": "main", "tir.noalias": True, "sparse_tir_level": 2}) + # sparse axes + I = T.dense_fixed(m) + J = T.sparse_variable(I, (n, nnz), (indptr, indices), "int32") + J_detach = T.dense_fixed(n) + K = T.dense_fixed(feat_size) + # sparse buffers + A = T.match_sparse_buffer(a, (I, K), "float32") + B = T.match_sparse_buffer(b, (J_detach, K), "float32") + X = T.match_sparse_buffer(x, (I, J), "float32") + Y = T.match_sparse_buffer(y, (I, J), "float32") + # sparse iterations + with T.sp_iter([I, J, K], "SSR", "sddmm") as [i, j, k]: + with T.init(): + Y[i, j] = 0.0 + Y[i, j] = Y[i, j] + A[i, k] * B[j, k] * X[i, j] +``` + +where we have constructs like **sparse axes**, **sparse buffers** and **sparse iterations**. + +### Sparse Axis +Sparse axis is a generation of per-dimensional level formats in TACO where we annotate each dimension of a format as **dense**/**sparse** (this dimension is stored in dense or compressed storage) and **fixed**/**variable** (this dimension's extent is fixed or variable). For **sparse**/**variable** axes, we need to specify its dependent axis. + +- For axes that are **sparse**, we need to specify a `indices` array to store the column indices. +- For axes that are **variable**, we need to specify an `indptr` (short for indices pointer) array to store the start offset of each row because the row length is variable and we cannot simply compute element offset with an affine map of indices. +- An axes that is both **sparse** and **variable** need to be specified with both **indices** and **indptr** array. + +```python +I = T.dense_fixed(m) +# J1 is a sparse fixed axis, whose dependent axis is I +# it has maximum length n and number of non-zero elements per row: c, +# the column indices data are stored in the region started from indices_1 handle, +# and the index data type (in indices array) is int32. +J1 = T.sparse_fixed(I, (n, c), indices_1, idtype="int32") +# J2 is a dense variable axis, whose dependent axis is I, +# it has a maximum length of n, +# the indptr data are stored in the region started from indptr_2 handle, +# and the index data type (in indptr array) is int32. +J2 = T.dense_variable(I, n, indptr_2, idtype="int32") +# J3 is a sparse variable axis, whose dependent axis is J1, +# it has maximum length of n1, number of elements nnz in the space composed of (I, J1, J3), +# the indptr data are stored in the region started from indptr_3 handle, +# and the indices data are stored in the region started from indices_3 handle, +# the index data type (of indptr and indices array) is "int64") +J3 = T.sparse_variable(J1, (n1, nnz), (indptr_3, indices_3), idtype="int34") +``` + +### Sparse Buffer + +User can create sparse buffers with following APIs in SparseTIR: +``` +A = T.match_sparse_buffer(a, (I, J1), dtype="float32", scope="global") +B = T.alloc_sparse_buffer((I, j2), dtype="float32", scope="shared") +``` +Their semantics are very similar to the existing `match_buffer` and `alloc_buffer` constructs in TensorIR, with the exception that we accept an array of sparse axes as shape. +- The `match_sparse_buffer` binds a sparse format with a handle(pointer) `a` to the start of a user-specified input/output array that stores the value inside the sparse buffer. +- The `alloc_sparse_buffer` create a sparse buffer without binding to input or output and always acts as an intermediate buffer. + +The storage of sparse tensors in SparseTIR follows the design of [Compressed Sparse Fiber](http://shaden.io/pub-files/smith2017knl.pdf) which is a natural extension of CSR format to high dimensional. Note that SparseTIR decouples the storage of `value` with auxiliary structure information such as `indptr` and `indices`: the `value` array is bonded with sparse buffers and the `indptr` and `indices` array is bonded to axes. Such design enables us to share structure information for different buffers (e.g. in the SDDMM example shown above, the `X` and `Y` sparse buffers share structure and we don't need duplicate storage for their `indptr` and `indices`). + +We can express sparse tensors stored in various formats using the *sparse axis* and *sparse buffer* construct: +```python +# ELLPack format, with number of columns per row 4 +I = T.dense_fixed(m) +J = T.sparse_fixed(I, (n, 4), indices, idtype="int32") +A = T.match_sparse_buffer(a, (I, J), dtype="float32") +``` +```python Review Comment: We do not change anything to existing Buffer design, the `SparseBuffer` is a new data structure that would be lowered in `lower_sparse_buffer` pass. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}