Added dependencies in the ReadDiagram. First complete rough draft of the README for the ioframework.
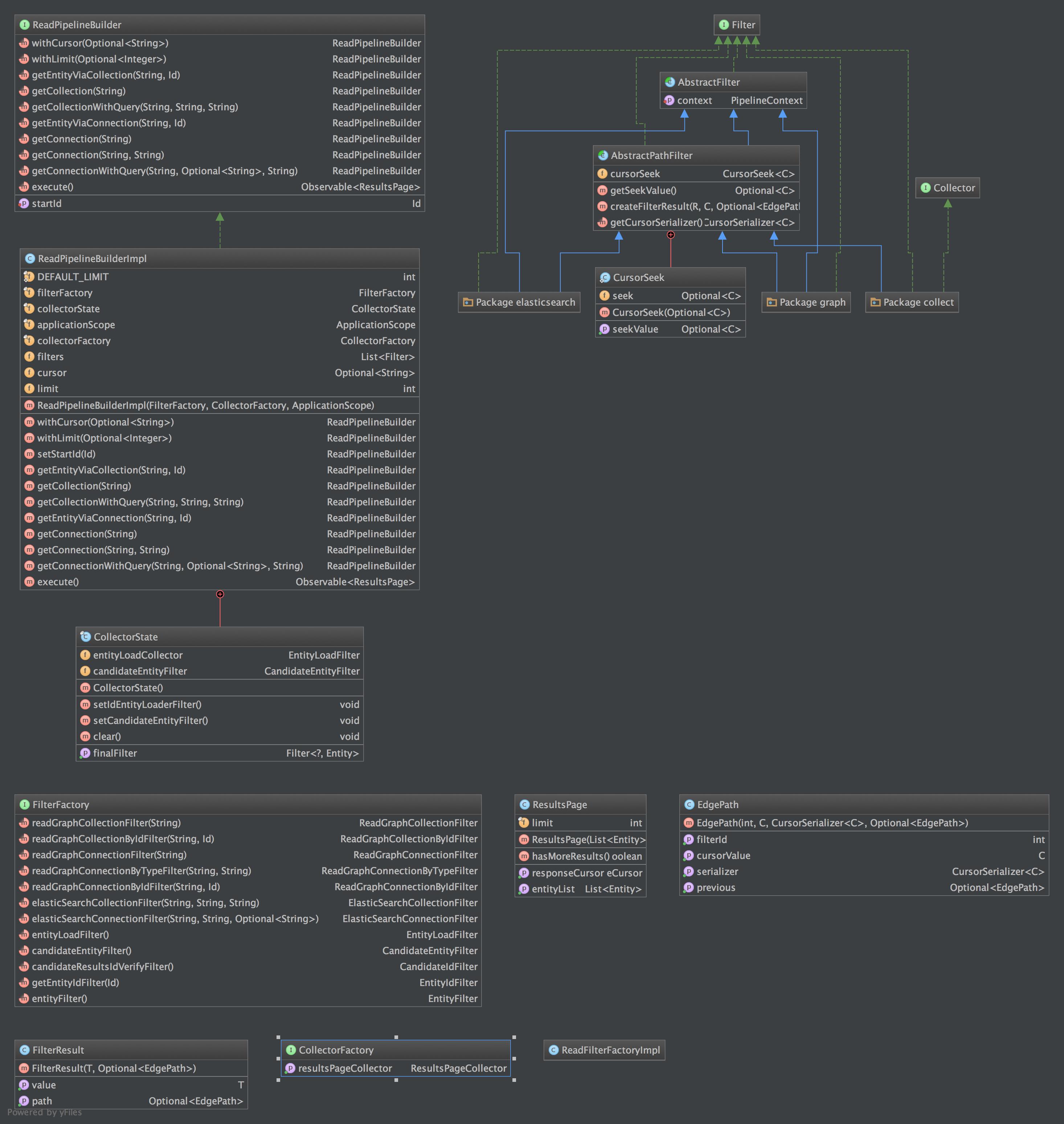
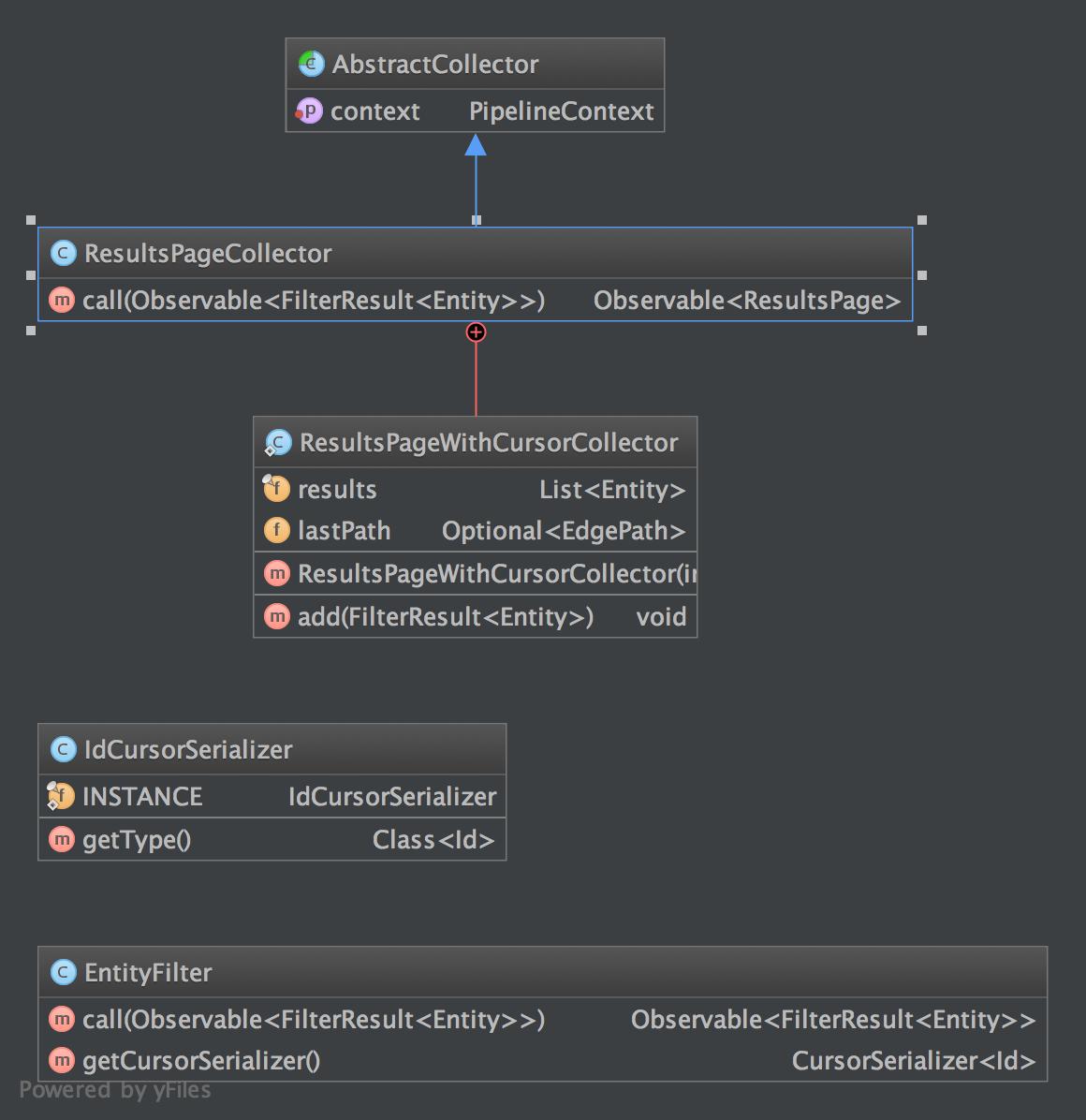
Project: http://git-wip-us.apache.org/repos/asf/incubator-usergrid/repo Commit: http://git-wip-us.apache.org/repos/asf/incubator-usergrid/commit/8d1618f8 Tree: http://git-wip-us.apache.org/repos/asf/incubator-usergrid/tree/8d1618f8 Diff: http://git-wip-us.apache.org/repos/asf/incubator-usergrid/diff/8d1618f8 Branch: refs/heads/USERGRID-614 Commit: 8d1618f845ccd4680b27b08dbff7053a04e02b34 Parents: 5312bbc Author: GERey <[email protected]> Authored: Mon May 4 14:54:22 2015 -0700 Committer: GERey <[email protected]> Committed: Mon May 4 14:54:22 2015 -0700 ---------------------------------------------------------------------- .../usergrid/corepersistence/pipeline/README.md | 110 +++++++++++++------ .../pipeline/read/ReadDiagram.jpg | Bin 568372 -> 818565 bytes 2 files changed, 78 insertions(+), 32 deletions(-) ---------------------------------------------------------------------- http://git-wip-us.apache.org/repos/asf/incubator-usergrid/blob/8d1618f8/stack/core/src/main/java/org/apache/usergrid/corepersistence/pipeline/README.md ---------------------------------------------------------------------- diff --git a/stack/core/src/main/java/org/apache/usergrid/corepersistence/pipeline/README.md b/stack/core/src/main/java/org/apache/usergrid/corepersistence/pipeline/README.md index f469e30..09b3877 100644 --- a/stack/core/src/main/java/org/apache/usergrid/corepersistence/pipeline/README.md +++ b/stack/core/src/main/java/org/apache/usergrid/corepersistence/pipeline/README.md @@ -33,7 +33,7 @@ Consider the following example flow: * Each filter contains a Pipeline Context due to the above reason. 1. PipelineOperation * Top class in the Pipeline because it defines what every pipeline operation needs to have and extend. Mandates that every class in the Pipeline extend this class. - * Primary interface for Filtering and Collection commands. + * Primary interface for Filtering and Collection commands in the Read module. 1. Cursor Module * Contains the Request and ResponseCursor classes that are instantiated in Pipeline Module. * Contains logic that represents the cursor logic. @@ -48,49 +48,43 @@ Consider the following example flow: The Cursor Module is made up of 7 classes. 1. ResponseCursor - a. This is the cursor that gets returned in the response after the filter has run. - b. The flow defined by the Response cursor is as follows + * This is the cursor that gets returned in the response after the filter has run. + * The flow defined by the Response cursor is as follows 1. Set cursor(s) that are made up of a Integer and a CursorEntry 1. Response Cursor gets initalized 1. We go into the CursorEntry class that consists of the Cursor ( of a raw type ) and the serializer that we would use to parse the Cursor. 1. RequestCursor - a. Contains some information on the parsedCursor - b. This gets populated by either the User ( using a cursor that we've given them), or by the pipeline feeding the cursor into the next stage. - c. Could be + * Contains some information on the parsedCursor + * This gets populated by either the User ( using a cursor that we've given them), or by the pipeline feeding the cursor into the next stage. +1. AbstractCursorSerializer + * Used exclusivly in the read module and should probably be refactored there + * Is a CursorSerializer that implements the the base cursor methods. +1. CursorSerializerUtil + * Defines the type of serialization we encode the cursors with. In this case Smile Jackson Serialization. *** ###Indepth Read Module Explanation  - -1. CandidateResultsFilter - * Is an interface - * Extends PipelineOperation - * Defines the types that will be requried in the filter. While not visible in the diagram the CandidateResultsFilters will consist of a <Id, CandidateResults>. - * Primary filter that will be used for interfacing with ES (Elasticsearch) 1. Filter * Extends generic PipelineOperation - * Primary used to interact with Graph and Entity modules - * Why do we use the filter in the ReadPipeline when we could also interchange the Canadiate Results filter? Is it just the type that differentiates it. -1. AbstractSeekingFilter + * Interacts with anything that classifies itself as a filter. + * Defines output as a element T and a FilterResult. +1. AbstractPathFilter * This abstract filter is meant to be extended by any filter that requires a cursor and operations on that cursor. * Extends from the AbstractPipelineOperation because a filter is a pipeline operation. - * Is used in the Graph and Elasticsearch submodules because those both use cursors. + * Is used in all the submodules as a way to deal with cursors. 1. CursorSeek - * Protected internal class that lives in AbstractSeekingFilter + * Protected internal class that lives in AbstractPathFilter * Whats the deal with only seeking values on the first call? Is this not similar to pagination? 1. Collector * Extends generic PipelineOperation - * Primary used to interact with Entity and Elasticsearch Packages + * Primary used to interact with the collect module * Used to reduce our stream of results into our final output. -1. CollectorState - * The state that holds a singleton collector instance and what type of collector the Collector filter should be using. - * The collector state gets initialized with a CollectorFactory and then gets set with which collector it should use for the Collector object that it holds. - * This is a private inner class within ReadPipelineBuilderImpl 1. Elasticsearch Module * Contains the functions we use to actual perform filtered commands that contain elasticsearch components. * These will typically return Canadiate Result sets that will be processed by the collector. -1. Entity Module +1. Collect Module * Contains a single filter that maps id's, and the collector that processes entity id's. 1. Graph Module * Contains the filters that are used to interact with the lower level Graph Module. @@ -103,15 +97,37 @@ The Cursor Module is made up of 7 classes. * Contains the builder implementation of the ReadPipelineBuilder. * Adds on filters from FilterFactory depending on the type of action we take. * Contains execute method when the pipeline is finished building. This pushes results as an observable back up. +1. CollectorState + * The state that holds a singleton collector instance and what type of collector the Collector filter should be using. + * The collector state gets initialized with a CollectorFactory and then gets set with which collector it should use for the Collector object that it holds. + * This is a private inner class within ReadPipelineBuilderImpl +1. Results Page + * Contains the encapsulation of entities as a group of responses. + * Holds the list of entities along with the limit of the entities we want for a response and the cursor that gets returned. + * Maybe refactor to collect module? +1. EdgePath + * Represents the path from the intial entity to the emitted element. + * A list of these represnt a path through the graph to a specific element. *** -###Indepth Entity Module Explanation -The entity module only contains two classes. So I won't attach the uml diagram as they aren't related to each other in any way. -1. EntityIdFilter - * A stopgap filter that helps migrating from the service tier and its entities. Just makes a list of entities. -2. EntityLoadCollector - * The EntityLoadCollector loops through entity id's and then converts them to our old entity model so that they can go through the service and rest tier. +###Indepth Collect Module Explanation + + + + +1. EntityFilter + * A filter that is used when we can potentially serialize pages via cursor. ? (not entirely sure I know what that means.) +1. IdCursorSerializer + * The serializer for Id's. +1. AbstractCollector + * Abstract class that derives from Collector class + * Adds a pipelineContext for the collector to work with when looking at cursors. +1. ResultsPageCollector + * Takes the entities and collects them into results so we can return them through the service and rest tier. Exists for 1.0 compatibility. +1. ResultsPageWithCursorCollector + * This collector aggregates our results together using an arrayList. + *** ###Indepth Graph Module Explanation @@ -119,6 +135,9 @@ The entity module only contains two classes. So I won't attach the uml diagram a 1. EdgeCursorSerializer * The serializer we use to decode and make sense of the graph cursor that gets returned. + + The Main difference between ReadGraph and ReadGraph by id is that the Id won't ever bother itself with cursors because it doesn't need to worry about cursor generation. Hence the distinction but very similar patterns. + 1. AbstractReadGraph(EdgeById)Filter * An abstract class that defines how we should read graph edges from name(id). 1. ReadGraphConnection(ById)Filter @@ -127,6 +146,15 @@ The entity module only contains two classes. So I won't attach the uml diagram a * Defines how to read Collections out of the graph using names(id). 1. ReadGraphconnectionByTypeFilter * A filter that reads graph connections by type. + 1. EntityIdFilter + * A stopgap filter that helps migrating from the service tier and its entities. Just makes a list of entities. + 1. EdgeLoadFilter + * Loads entities from a set of Ids. + 1. EntityVerifier + * Verifies that the id's in the filter results exist and can be added to the results. + * Functions as a collector. + 1. EdgeState + * A wrapper class that addresses the problem with skipping a value if a concurrent change has been made on the data set. In some cases we would be skipping a value. Now the cursor will always try to seek to the same position that we ended instead of the new position created by the change in data. *** ###Indepth Elasticsearch Module Explanation @@ -135,15 +163,33 @@ The entity module only contains two classes. So I won't attach the uml diagram a 1. Impl Module * contains all the implementations and verfiers and loaders for elasticsearch - 2. AbstractElasticSearchFilter - * This extends into the same pattern as the Graph Module where we make a abstract filter so we can extend it to easily accomodate Collection or Connection searching. + 3. CandidateResultsEntityResultsCollector * Collects the results from Elasticsearch then retrieves them from cassandra and converts them from 2.0 to 1.0 entities that are suitable for return. 4. CandidateResultsIdVerifyFilter * Filter that verifies that the canaidate results id's are correct???? What else does this do ? isn't that what the collector does? + 5. ElasticsearchCursorSerializer * The serializer we use to decode and make sense of the elasticsearch cursor. - + 1. Candidate + * Contains the candidate result and the search edge that was searched for that result. + * Is Canadidate really a good name for this class if it actually contains the CandidateResults? What does this class represent? + 1. CandidateIdFilter + * Takes in candidate results and outputs a stream of validated Ids. + * Uses the EntityCollector to map a fresh new cp entity to an old 1.0 version of the entity. Then we return those results to the upper tiers. + 1. EntityCollector + * I'm not entirely clear how the collector actually does the mapping. Seems like it just does the elasticsearch repair and checks entity versions. Then collects the entities into a result set + 1. AbstractElasticSearchFilter + * This extends into the same pattern as the Graph Module where we make a abstract filter so we can extend it to easily accomodate Collection or Connection searching. + 2. ElasticSearchConnectionFilter + * Creates the filter that will go and search for connections in elasticsearch. + 3. ElasticSearchCollectionFilter + * Creates the filter that will go and search for collections in elasticsearch. + 4. CandidateEntityFilter + * Searches on incoming Candidate entity and returns an entity instead of an Id like the CandidateIdFilter. + * Does a similar repair using the EntityVerifier. + 5. EntityVerifier + * Collects the entities emitted and returns them as a result set. Also verifies that the entities exist or if they need to be repaired in elasticsearch. http://git-wip-us.apache.org/repos/asf/incubator-usergrid/blob/8d1618f8/stack/core/src/main/java/org/apache/usergrid/corepersistence/pipeline/read/ReadDiagram.jpg ---------------------------------------------------------------------- diff --git a/stack/core/src/main/java/org/apache/usergrid/corepersistence/pipeline/read/ReadDiagram.jpg b/stack/core/src/main/java/org/apache/usergrid/corepersistence/pipeline/read/ReadDiagram.jpg index 60e4b66..4fd18a0 100644 Binary files a/stack/core/src/main/java/org/apache/usergrid/corepersistence/pipeline/read/ReadDiagram.jpg and b/stack/core/src/main/java/org/apache/usergrid/corepersistence/pipeline/read/ReadDiagram.jpg differ
{kind=link}
{kind=link}
{kind=link}