Dear Wiki user, You have subscribed to a wiki page or wiki category on "Hadoop Wiki" for change notification.
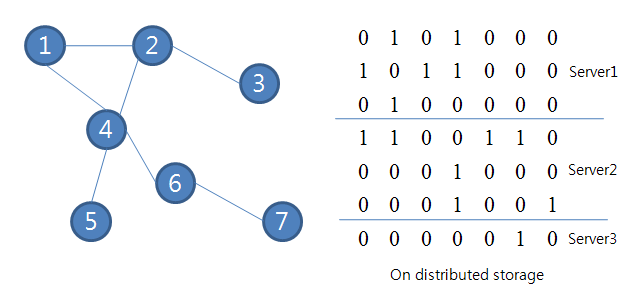
The following page has been changed by edwardyoon: http://wiki.apache.org/hadoop/Hamburg ------------------------------------------------------------------------------ == Motivation == The MapReduce (M/R) programming model is inappropriate to problems based on data where each portion depends on many other potions and their relations are very complicated. It is because these problems cause as follows: + + ''Do you know other situations that might fall into what you are describing above?'' + * limit to assigning one reducer * In case that the relations of data are very complex, assigning intermediate data to appropriate reducers by considering their dependency of partitioned graphs may be very hard. Assigning only one reducer is a straightway to solve complexity dependency, but it is apparent to cause deterioration of scalability. * many M/R iterations * or make an M/R program more complicated * To avoid above two inefficient methods, the M/R program will be complicated with code to communicate data among data nodes. - These problems are very common in many areas; especially, many graph problems are exemplary. + These problems are very common in many areas; especially, many graph problems are exemplary. Therefore, we try to propose a new programming model, named Hamburg. The main objective of Hamburg is to support well the problems based on data having complexity dependency one another. This page is an initial work of our proposal. + ''We should survey other areas -- Edward J.'' - * TODO - write description of an example. - * http://en.wikipedia.org/wiki/Girvan-Newman_algorithm - * PageRank - - Therefore, we try to propose a new programming model, named Hamburg. The main objective of Hamburg is to support well the problems based on data having complexity dependency one another. This page is an initial work of our proposal. == Goal == * Follow scalability concept of shared-nothing architecture @@ -41, +40 @@ [http://lh5.ggpht.com/_DBxyBGtfa3g/SmQTwhOSGwI/AAAAAAAABmY/ERiJ2BUFxI0/s800/figure2.PNG] + ''TODO: write more detail of above. -- Edward J.'' + === Initial contributors === * Edward J. (edwardyoon AT apache.org) * Hyunsik Choi (hyunsik.choi AT gmail.com) Any volunteers are welcome. + == Implementation == + + ''TODO: please write what we should consider and prepare to implement this -- Edward J.'' + + === master tracker (provisional) === + + * job assign + * fault tolerant mechanism + * local task management + + === local tracker (provisional) === + + * local processing + * local/outgoing queue management + + === zookeeper === + + * Job status notification + * Sync barrier processing + == Related Projects == * [http://incubator.apache.org/hama Hama], A distributed matrix computational package for Hadoop.
{kind=link}