Dear Wiki user, You have subscribed to a wiki page or wiki category on "Hadoop Wiki" for change notification.
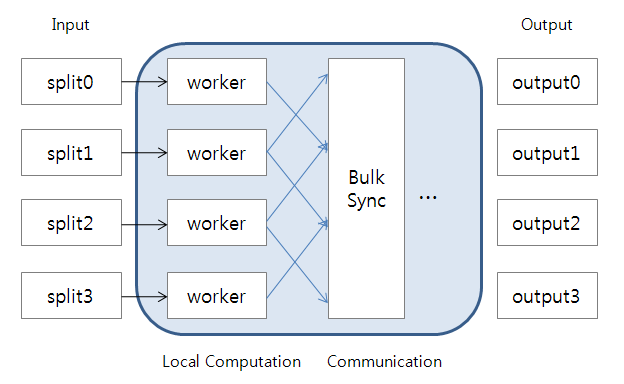
The "Hamburg" page has been changed by edwardyoon: http://wiki.apache.org/hadoop/Hamburg?action=diff&rev1=22&rev2=23 ## page was renamed from Hambrug - <<TableOfContents(5)>> + * This graph computing framework project will be integrated to [[http://wiki.apache.org/hama|Hama]] - == Motivation == - Large-scale graph processing has been being required in many areas, such as bioinformatics, social networks, semantic web, and web information retrieval. However, existing systems cannot deal with rapidly increasing volume of graph data. After advent of MapReduce (MR), many people have expected that MR will be a nice solution for large-scale graph processing, and some of them may be trying to find algorithms and solutions for large-scale graph processing with M/R. However, even though MR is a great programming model having linear scalability, we argue that for large-scale graph processing we need an alternative programming model to MR because of the following reasons: - - * '''!MapReduce cannot support traversing graph''' – A mapper/reduce only provides sequential access to input data, and we use M/R iterations in order to change the access pattern because MR cannot control its next input data. In contrast, many of the graph problems are based on walking vertices in step by step (i.e., graph traversing). Walking vertices implies expanding adjacent vertices from a given vertex. This approach can be only available if the operation by current input data can determine next input data. In MR, however, the current operation cannot control the input data of the next operation. Consequently, graph processing with MapReduce is very limited. In order to come over this limit, we have to avoid traverse of graph in order to solve graph problems ([[http://ieeexplore.ieee.org/search/wrapper.jsp?arnumber=5076317|Graph Twiddling in a MapReduce World]]) or have to perform many MR iterations ([[http://blog.udanax.org/2009/02/breadth-first-search-mapreduce.html|Breadth-First Search (BFS) & MapReduce]]). As you know, the initialize cost of each MR is very expensive. - * '''!MapReduce limits to assigning one reducer''' - When a MR program deal with some graph program, assigning intermediate data to appropriate reducers by the partitioner according to relations of partitioned graph data is very difficult because it is difficult to satisfy the local sufficiency of data. Local sufficiency means that no data in difference sites is needed to process a task. To the best of my knowledge, one of the most straightforward way of this problem is to use only one reducer, but it is apparent to cause scalability problem. - * '''More complicated M/R program''' - To avoid graph traverse or the limit of one reduce, the M/R programs have to be inevitablely complicated and have to communicate data among data nodes during each MR computation. - - Therefore, we need a new programming model for graph processing on Hadoop. - - == Goal == - * Support graph traverse - * Support a simple programming interface familiar with graph features. - * Follow the scalability concept of shared-nothing architecture - * Fault-Tolerant Implementation - - == Hamburg == - Hambrug is an alternative to MR programming model. It consists of two parts, each of which is related to locality-preserving storing method for graph in terms of connectivity and computations with traverse interface on graphs respectively. - - The main purpose of the locality-preserving storing method for graph is to store vertices close to one another into the same HDFS block. The computation part with this storing method may reduce considerable communication cost and the number of bulk sync step. It will be a kind of pre-process step and be implemented in MR. - - The computation part is based on bulk synchronization parallel (BSP) model. Like MR, Hamburg will take advantages from shared-nothing architecture (SN), so I expect that it will also show scalability without almost degradation of performance as the number of participant nodes increases. In addition, we will provide a set of easy APIs familiar with graph features and similar to MR. - - The computation part based on BSP computation step consists of three sub steps: - * Computation on data that reside in local storage; it is similar to map operation in M/R. - * Each node communicates its necessary data into one another. - * All processors synchronize which waits for all of the communications actions to complete. - - Let's see more detail in the diagram of computing method of Hamburg based on BSP model. - - [[http://lh4.ggpht.com/_DBxyBGtfa3g/SmQUYTHWooI/AAAAAAAABmk/cFVlLCdLVHE/s800/figure1.PNG]] - - When a job is submitted, each worker starts with processing the data partitions that reside in local storage. During local computation, each worker stores temporal data, which are needed to transmitted to appropriate other workers, into a local queue. After all local computations finish, each worker will perform bulk synchronization by using collected communication among workers. The 'Computation' and 'Bulk synchronization' can be performed iteratively. Data for synchronization can be compressed to reduce network usage. The main difference between Hamburg and MR is that Hamburg does not make intermediate data aggregate into reducer. Instead, each computation node communicates only necessary data into one another at each bulk synchronization step. It will be efficient if total communicated data is smaller then intermediate data to be aggregated into reducers. Plainly, It aims to improve the performance of traverse operations in Graph computing. - - === Initial contributors === - * Edward J. (edwardyoon AT apache.org) - * Hyunsik Choi (hyunsik.choi AT gmail.com) - - Any volunteers are welcome. - - == Implementation == - - === Informations === - * [[http://throb.googlecode.com/|Prototype project]] -- work in progress - * Use this command to anonymously check out the latest project source code: - {{{ - # Non-members may check out a read-only working copy anonymously over HTTP. - svn checkout http://throb.googlecode.com/svn/trunk/ throb-read-only - }}} - - === User Interface Design === - - The user interface is likely to be a simple form that allows processing a single item at a time. - - {{{ - User Interface: - - /** - * @param input - * @param nextQueue - */ - public void traverse(Map<V, Message> input, Map<K, Message> nextQueue, - Map<Object, Object> localCollector); - - public void synchronize(Map<Object, Object> localCollector, - Iterator<Entry<Integer, Map<K, Message>>> outgoingQueue); - - public void finalyze(Map<Object, Object> localCollector); - - /** - * At initial time or when a local queue is empty, the picker chooses - * unvisited vertex from local graphs. - */ - public V pick(); - }}} - - == Related Projects == - - * [[http://incubator.apache.org/hama|Hama]], A distributed matrix computational package for Hadoop. - * [[http://rdf-proj.blogspot.com/|Heart]], A large-scale RDF data store and a distributed processing engine. - - == Related Ideas == - - * [[http://blog.udanax.org/2009/08/inference-anatomy-of-google-pregel.html|Inference anatomy of the Google Pregel]] - * [[http://blog.udanax.org/2009/08/graph-database-on-hadoop.html|Graph database on Hadoop]] -
{kind=link}