Hi Shawn,
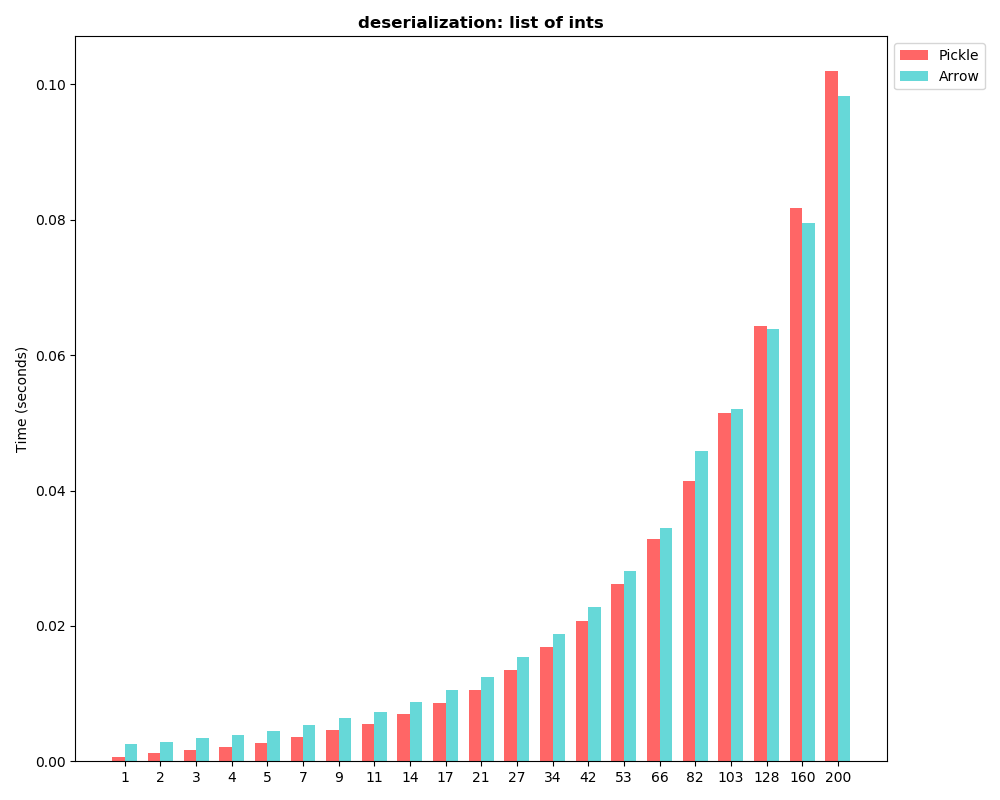
So it seems that RecordBatch serialization is able to avoid copies, otherwise there's no benefit to using Arrow over pickle. Perhaps would you like to try and use pickle5 with out-of-band buffers in your benchmark. See https://pypi.org/project/pickle5/ Regards Antoine. Le 25/04/2019 à 11:23, Shawn Yang a écrit : > Hi Antoine, > Here are the images: > 1. use |UnionArray| benchmark: > https://user-images.githubusercontent.com/12445254/56651475-aaaea300-66bb-11e9-8b4f-4632e96bd079.png > https://user-images.githubusercontent.com/12445254/56651484-b5693800-66bb-11e9-9b1f-d004212e6aac.png > https://user-images.githubusercontent.com/12445254/56651490-b8fcbf00-66bb-11e9-8f01-ef4919b6af8b.png > 2. use |RecordBatch| > https://user-images.githubusercontent.com/12445254/56629689-c9437880-6680-11e9-8756-02acb47fdb30.png > > Regards > Shawn. > > On Thu, Apr 25, 2019 at 4:03 PM Antoine Pitrou <[email protected] > <mailto:[email protected]>> wrote: > > > Hi Shawn, > > Your images don't appear here. It seems they weren't attached to your > e-mail? > > About serialization: I am still working on PEP 574 (*), which I hope > will be integrated in Python 3.8. The standalone "pickle5" module is > also available as a backport. Both Arrow and Numpy support it. You may > get different pickle performance using it, especially on large data. > > (*) https://www.python.org/dev/peps/pep-0574/ > > Regards > > Antoine. > > > Le 25/04/2019 à 05:19, Shawn Yang a écrit : > > > > Motivate > > > > We want to use arrow as a general data serialization framework in > > distributed stream data processing. We are working on ray > > <https://github.com/ray-project/ray>, written in c++ in low-level and > > java/python in high-level. We want to transfer streaming data between > > java/python/c++ efficiently. Arrow is a great framework for > > cross-language data transfer. But it seems more appropriate for batch > > columnar data. Is is appropriate for distributed stream data > processing? > > If not, will there be more support in stream data processing? Or is > > there something I miss? > > > > > > Benchmark > > > > 1. if use |UnionArray| > > image.png > > image.png > > image.png > > 2. If use |RecordBatch|, the batch size need to be greater than 50~200 > > to have e better deserialization performance than pickle. But the > > latency won't be acceptable in streaming. > > image.png > > > > Seems neither is an appropriate way or is there a better way? > > > > > > Benchmark code > > > > ''' > > test arrow/pickle performance > > ''' > > import pickle > > import pyarrow as pa > > import matplotlib.pyplot as plt > > import numpy as np > > import timeit > > import datetime > > import copy > > import os > > from collections import OrderedDict > > dir_path = os.path.dirname(os.path.realpath(__file__)) > > > > def benchmark_ser(batches, number=10): > > pickle_results = [] > > arrow_results = [] > > pickle_sizes = [] > > arrow_sizes = [] > > for obj_batch in batches: > > pickle_serialize = timeit.timeit( > > lambda: pickle.dumps(obj_batch, > protocol=pickle.HIGHEST_PROTOCOL), > > number=number) > > pickle_results.append(pickle_serialize) > > pickle_sizes.append(len(pickle.dumps(obj_batch, > protocol=pickle.HIGHEST_PROTOCOL))) > > arrow_serialize = timeit.timeit( > > lambda: serialize_by_arrow_array(obj_batch), > number=number) > > arrow_results.append(arrow_serialize) > > arrow_sizes.append(serialize_by_arrow_array(obj_batch).size) > > return [pickle_results, arrow_results, pickle_sizes, arrow_sizes] > > > > def benchmark_deser(batches, number=10): > > pickle_results = [] > > arrow_results = [] > > for obj_batch in batches: > > serialized_obj = pickle.dumps(obj_batch, > pickle.HIGHEST_PROTOCOL) > > pickle_deserialize = timeit.timeit(lambda: > pickle.loads(serialized_obj), > > number=number) > > pickle_results.append(pickle_deserialize) > > serialized_obj = serialize_by_arrow_array(obj_batch) > > arrow_deserialize = timeit.timeit( > > lambda: pa.deserialize(serialized_obj), number=number) > > arrow_results.append(arrow_deserialize) > > return [pickle_results, arrow_results] > > > > def serialize_by_arrow_array(obj_batch): > > arrow_arrays = [pa.array(record) if not isinstance(record, > pa.Array) else record for record in obj_batch] > > return pa.serialize(arrow_arrays).to_buffer() > > > > > > plot_dir = '{}/{}'.format(dir_path, > datetime.datetime.now().strftime('%m%d_%H%M_%S')) > > if not os.path.exists(plot_dir): > > os.makedirs(plot_dir) > > > > def plot_time(pickle_times, arrow_times, batch_sizes, title, > filename): > > fig, ax = plt.subplots() > > fig.set_size_inches(10, 8) > > > > bar_width = 0.35 > > n_groups = len(batch_sizes) > > index = np.arange(n_groups) > > opacity = 0.6 > > > > plt.bar(index, pickle_times, bar_width, > > alpha=opacity, color='r', label='Pickle') > > > > plt.bar(index + bar_width, arrow_times, bar_width, > > alpha=opacity, color='c', label='Arrow') > > > > plt.title(title, fontweight='bold') > > plt.ylabel('Time (seconds)', fontsize=10) > > plt.xticks(index + bar_width / 2, batch_sizes, fontsize=10) > > plt.legend(fontsize=10, bbox_to_anchor=(1, 1)) > > plt.tight_layout() > > plt.yticks(fontsize=10) > > plt.savefig(plot_dir + '/plot-' + filename + '.png', format='png') > > > > > > def plot_size(pickle_sizes, arrow_sizes, batch_sizes, title, > filename): > > fig, ax = plt.subplots() > > fig.set_size_inches(10, 8) > > > > bar_width = 0.35 > > n_groups = len(batch_sizes) > > index = np.arange(n_groups) > > opacity = 0.6 > > > > plt.bar(index, pickle_sizes, bar_width, > > alpha=opacity, color='r', label='Pickle') > > > > plt.bar(index + bar_width, arrow_sizes, bar_width, > > alpha=opacity, color='c', label='Arrow') > > > > plt.title(title, fontweight='bold') > > plt.ylabel('Space (Byte)', fontsize=10) > > plt.xticks(index + bar_width / 2, batch_sizes, fontsize=10) > > plt.legend(fontsize=10, bbox_to_anchor=(1, 1)) > > plt.tight_layout() > > plt.yticks(fontsize=10) > > plt.savefig(plot_dir + '/plot-' + filename + '.png', format='png') > > > > def get_union_obj(): > > size = 200 > > str_array = pa.array(['str-' + str(i) for i in range(size)]) > > int_array = pa.array(np.random.randn(size).tolist()) > > types = pa.array([0 for _ in range(size)]+[1 for _ in > range(size)], type=pa.int8()) > > offsets = pa.array(list(range(size))+list(range(size)), > type=pa.int32()) > > union_arr = pa.UnionArray.from_dense(types, offsets, > [str_array, int_array]) > > return union_arr > > > > test_objects_generater = [ > > lambda: np.random.randn(500), > > lambda: np.random.randn(500).tolist(), > > lambda: get_union_obj() > > ] > > > > titles = [ > > 'numpy arrays', > > 'list of ints', > > 'union array of strings and ints' > > ] > > > > def plot_benchmark(): > > batch_sizes = list(OrderedDict.fromkeys(int(i) for i in > np.geomspace(1, 1000, num=25))) > > for i in range(len(test_objects_generater)): > > batches = [[test_objects_generater[i]() for _ in > range(batch_size)] for batch_size in batch_sizes] > > ser_result = benchmark_ser(batches=batches) > > plot_time(*ser_result[0:2], batch_sizes, 'serialization: ' > + titles[i], 'ser_time'+str(i)) > > plot_size(*ser_result[2:], batch_sizes, 'serialization > byte size: ' + titles[i], 'ser_size'+str(i)) > > deser = benchmark_deser(batches=batches) > > plot_time(*deser, batch_sizes, 'deserialization: ' + > titles[i], 'deser_time-'+str(i)) > > > > > > if __name__ == "__main__": > > plot_benchmark() > > > > > > Question > > > > So if i want to use arrow as data serialization framework in > > distributed stream data processing, what's the right way? > > Since streaming processing is a widespread scenario in > data processing, > > framework such as flink, spark structural streaming is becoming > more and > > more popular. Is there a possibility to add special support > > for streaming processing in arrow, such that we can also benefit from > > cross-language and efficient memory layout. > > > > > > > > >
{kind=link}
{kind=link}
{kind=link}
{kind=link}