[
https://issues.apache.org/jira/browse/PARQUET-1633?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17347411#comment-17347411
]
ASF GitHub Bot commented on PARQUET-1633:
-----------------------------------------
eadwright edited a comment on pull request #902:
URL: https://github.com/apache/parquet-mr/pull/902#issuecomment-843868178
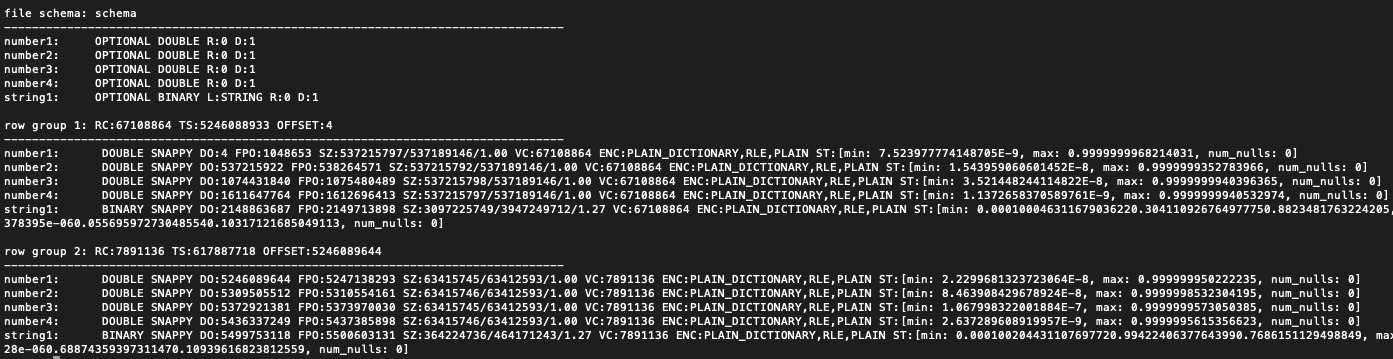
Screenshot from `parquet-tools meta` looking at the generated file. Note the
TS (total size) of row group 1 is way over 2GB. For the bug to happen, it is
also necessary for the rows to spill over into a second row group.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
> Integer overflow in ParquetFileReader.ConsecutiveChunkList
> ----------------------------------------------------------
>
> Key: PARQUET-1633
> URL: https://issues.apache.org/jira/browse/PARQUET-1633
> Project: Parquet
> Issue Type: Bug
> Components: parquet-mr
> Affects Versions: 1.10.1
> Reporter: Ivan Sadikov
> Priority: Major
>
> When reading a large Parquet file (2.8GB), I encounter the following
> exception:
> {code:java}
> Caused by: org.apache.parquet.io.ParquetDecodingException: Can not read value
> at 0 in block -1 in file
> dbfs:/user/hive/warehouse/demo.db/test_table/part-00014-tid-1888470069989036737-593c82a4-528b-4975-8de0-5bcbc5e9827d-10856-1-c000.snappy.parquet
> at
> org.apache.parquet.hadoop.InternalParquetRecordReader.nextKeyValue(InternalParquetRecordReader.java:251)
> at
> org.apache.parquet.hadoop.ParquetRecordReader.nextKeyValue(ParquetRecordReader.java:207)
> at
> org.apache.spark.sql.execution.datasources.RecordReaderIterator.hasNext(RecordReaderIterator.scala:40)
> at
> org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1$$anon$2.getNext(FileScanRDD.scala:228)
> ... 14 more
> Caused by: java.lang.IllegalArgumentException: Illegal Capacity: -212
> at java.util.ArrayList.<init>(ArrayList.java:157)
> at
> org.apache.parquet.hadoop.ParquetFileReader$ConsecutiveChunkList.readAll(ParquetFileReader.java:1169){code}
>
> The file metadata is:
> * block 1 (3 columns)
> ** rowCount: 110,100
> ** totalByteSize: 348,492,072
> ** compressedSize: 165,689,649
> * block 2 (3 columns)
> ** rowCount: 90,054
> ** totalByteSize: 3,243,165,541
> ** compressedSize: 2,509,579,966
> * block 3 (3 columns)
> ** rowCount: 105,119
> ** totalByteSize: 350,901,693
> ** compressedSize: 144,952,177
> * block 4 (3 columns)
> ** rowCount: 48,741
> ** totalByteSize: 1,275,995
> ** compressedSize: 914,205
> I don't have the code to reproduce the issue, unfortunately; however, I
> looked at the code and it seems that integer {{length}} field in
> ConsecutiveChunkList overflows, which results in negative capacity for array
> list in {{readAll}} method:
> {code:java}
> int fullAllocations = length / options.getMaxAllocationSize();
> int lastAllocationSize = length % options.getMaxAllocationSize();
>
> int numAllocations = fullAllocations + (lastAllocationSize > 0 ? 1 : 0);
> List<ByteBuffer> buffers = new ArrayList<>(numAllocations);{code}
>
> This is caused by cast to integer in {{readNextRowGroup}} method in
> ParquetFileReader:
> {code:java}
> currentChunks.addChunk(new ChunkDescriptor(columnDescriptor, mc, startingPos,
> (int)mc.getTotalSize()));
> {code}
> which overflows when total size of the column is larger than
> Integer.MAX_VALUE.
> I would appreciate if you could help addressing the issue. Thanks!
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
{kind=link}