Github user revans2 commented on the issue:
https://github.com/apache/storm/pull/2618
@danny0405
I just created #2622 to fix the race condition in AsyncLocalizer. It does
conflict a lot with this patch, so I wanted to make sure you saw it and had a
chance to give feedback on it.
I understand where the exception is coming from, but what I am saying is
that putting a synchronize on both cleanup and updateBlobs does not fix the
issue. Adding in the synchronize only serves to slow down other parts of the
processing. Even controlling the order in which they execute is not enough,
because cleanup will only happen after the scheduling change has been fully
processed.
Perhaps some kind of a message sequence chart would better explain the race
here.
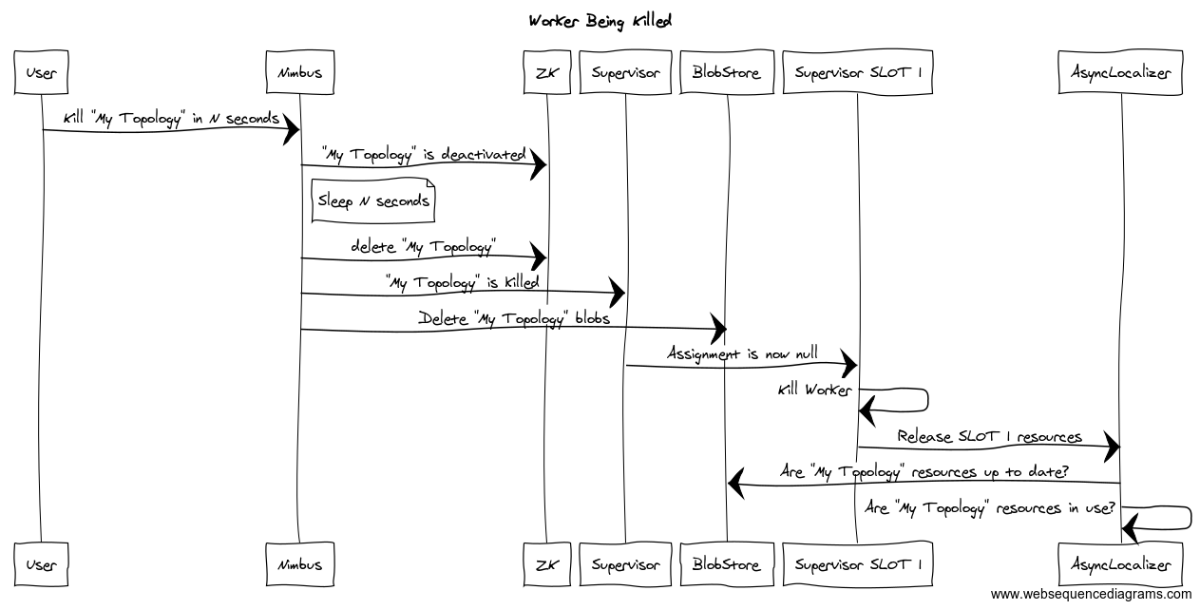
The issue is not in the order of cleanup and checking for updates. The
race is between nimbus deleting the blobs and the supervisor fully processing
the topology being killed.
Any time after nimbus deletes the blobs in the blob store until the
supervisor has killed the workers and released all references to those blobs we
can still get this issue.

The above sequence is an example of this happening even if we got the
ordering right.
The only way to "fix" the race is to make it safe to lose the race. The
current code will output an exception stack trace when it loses the race. This
is not ideal, but it is safe at least as far as I am able to determine.
That is why I was asking if the issue is just that we are outputting the
stack trace or if there is something else that is happening that is worse than
having all of the stack traces? If it is just the stack traces there are
things we can do to address them. If it goes beyond that then I still don't
understand the issue yet.
---
{kind=link}
{kind=link}