This is similar to v2 but I dropped some patches (for now) and added some new
ones. Most notably deadline scaling based on queue depth appears to be able to
add a little bit of fairness with spammy clients (deep submission queue).
As such, on the high level main advantages of the series:
1. Code simplification - no more multiple run queues.
2. Scheduling quality - schedules better than FIFO.
3. No more RR is even more code simplification but this one needs to be tested
and approved by someone who actually uses RR.
In the future futher simplifactions and improvements should be possible on top
of this work. But for now I keep it simple.
First patch adds some unit tests which allow for easy evaluation of scheduling
behaviour against different client submission patterns. From there onwards it is
a hopefully natural progression of patches (or close) to the end result which is
a slightly more fair scheduler than FIFO.
Regarding the submission patterns tested, it is always two parallel clients
and they broadly cover these categories:
* Deep queue clients
* Hogs versus interactive
* Priority handling
Lets look at the results:
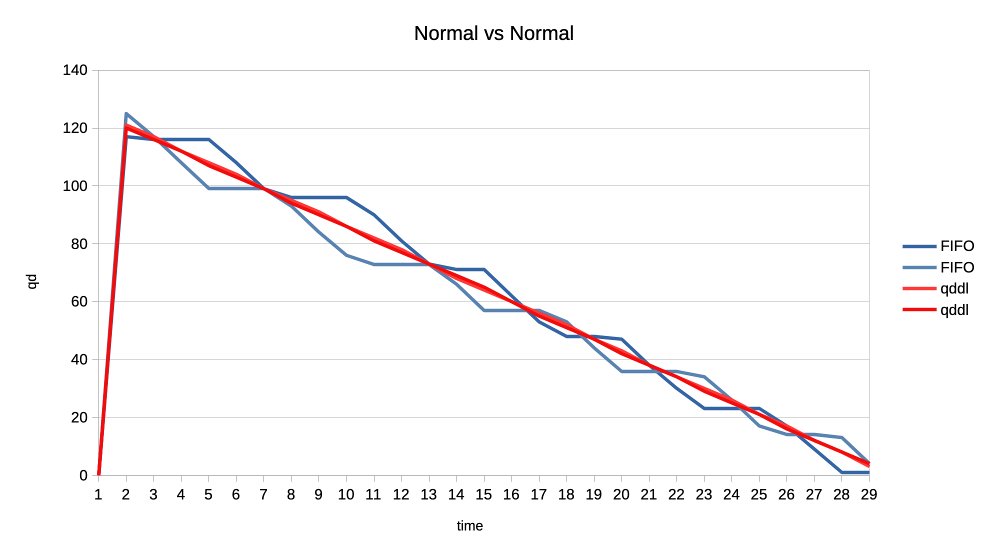
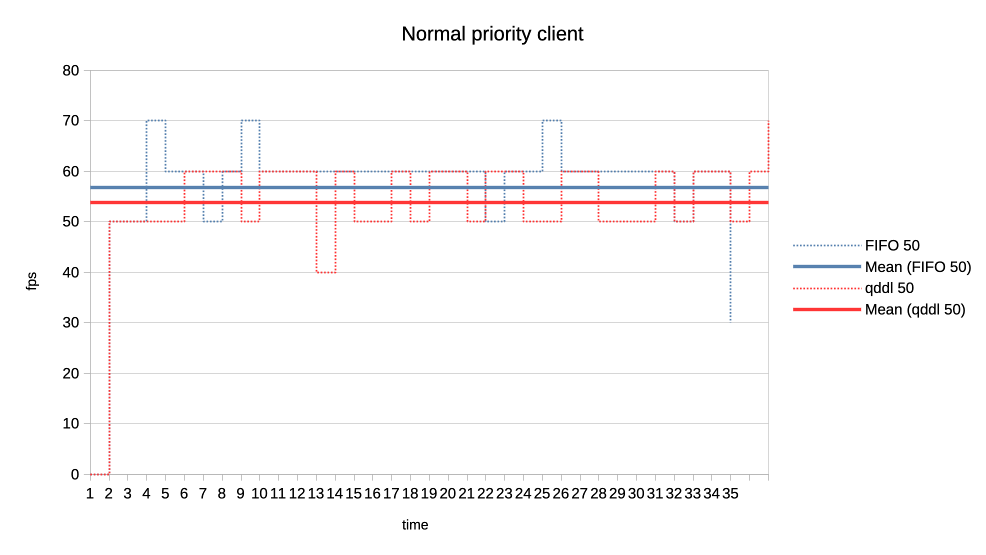
1. Two normal priority deep queue clients.
These ones submit one second worth of 8ms jobs. As fast as they can, no
dependencies etc. There is no difference in runtime between FIFO and qddl but
the latter allows both clients to progress with work more evenly:
https://people.igalia.com/tursulin/drm-sched-qddl/normal-normal.png
(X axis is time, Y is submitted queue-depth, hence lowering of qd corresponds
with work progress for both clients, tested with both schedulers separately.)
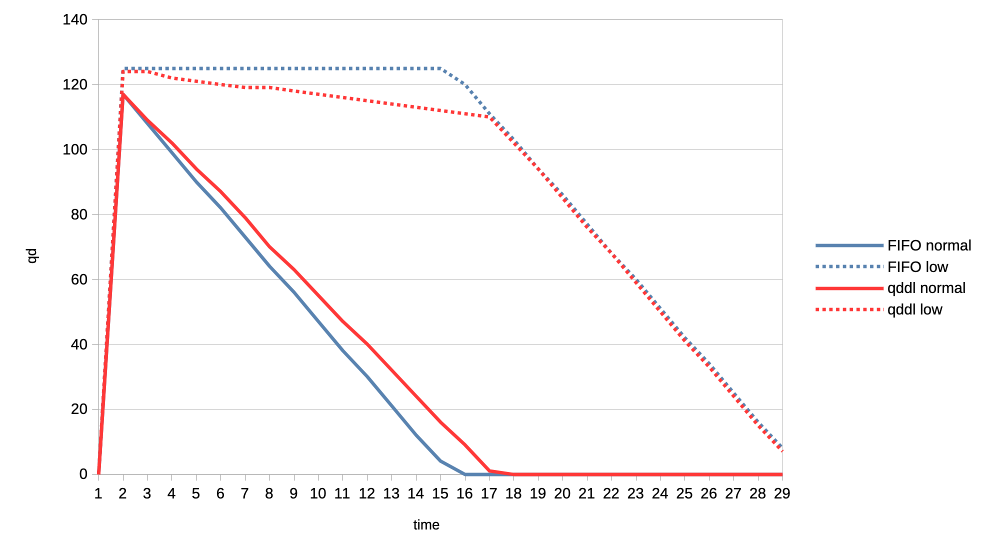
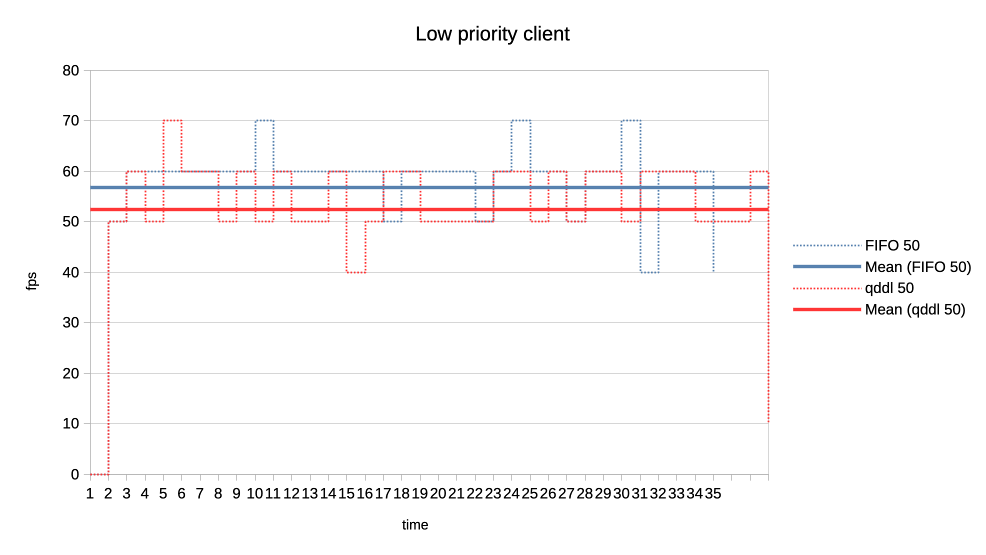
2. Same two clients but one is now low priority.
https://people.igalia.com/tursulin/drm-sched-qddl/normal-low.png
Normal priority client is a solid line, low priority dotted. We can see how FIFO
completely starves the low priority client until the normal priority is fully
done. Only then the low priority client gets any GPU time.
In constrast, qddl allows some GPU time to the low priority client.
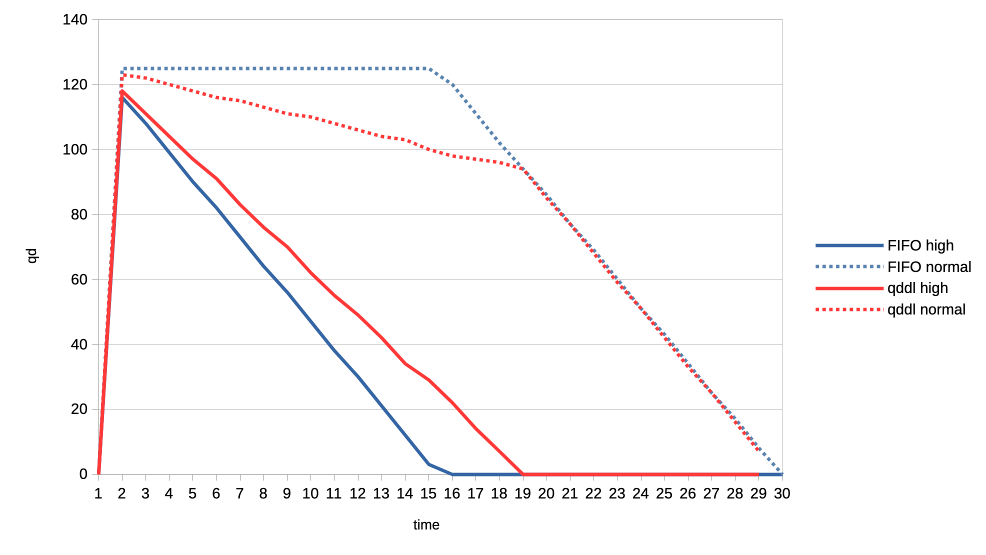
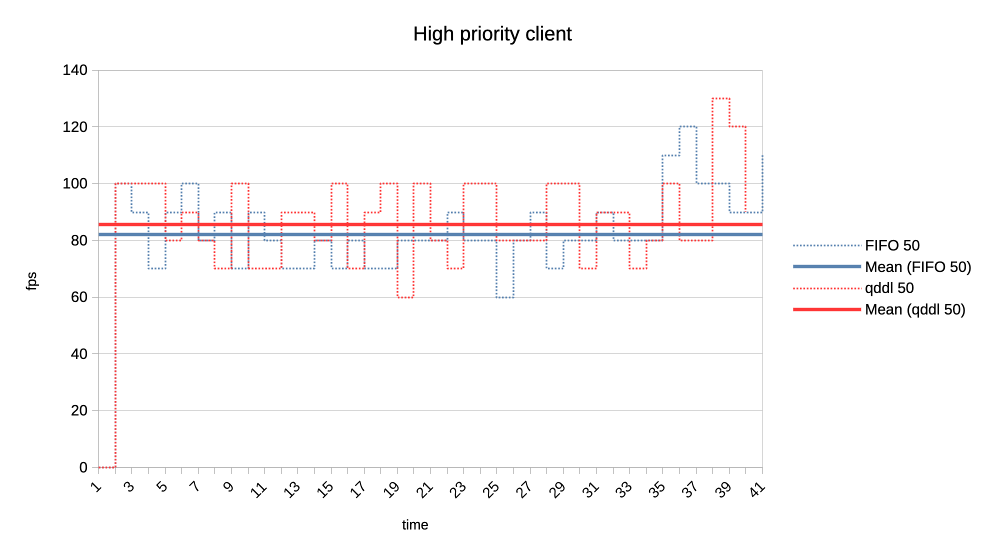
3. Same clients but now high versus normal priority.
Similar behaviour as in the previous one with normal a bit less de-prioritised
relative to high, than low was against normal.
https://people.igalia.com/tursulin/drm-sched-qddl/high-normal.png
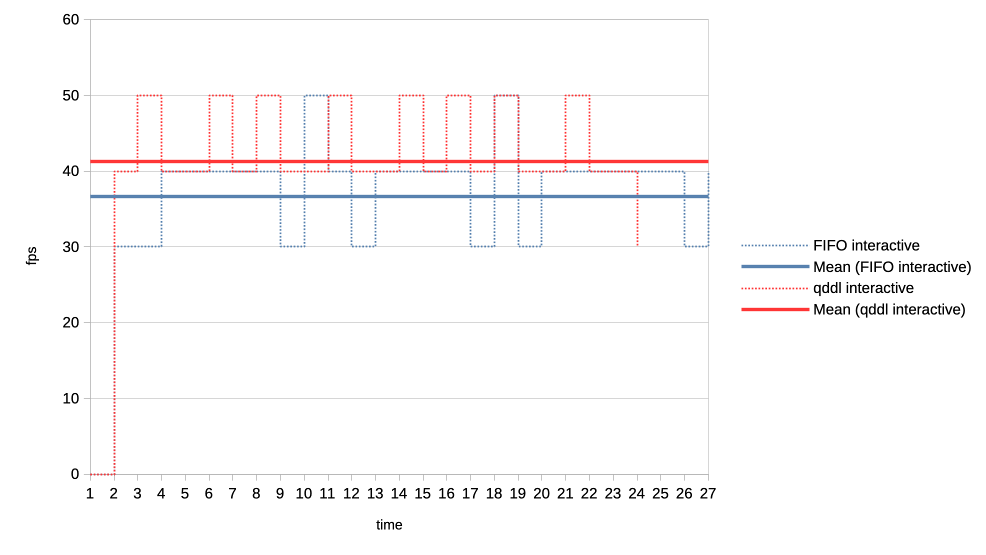
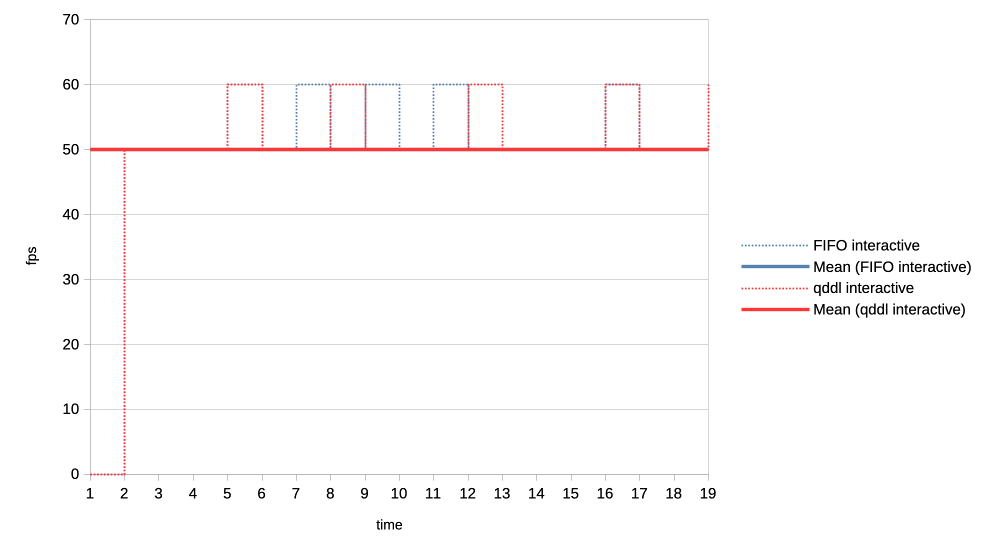
4. Heavy load vs interactive client.
Heavy client emits a 75% GPU load in the format of 3x 2.5ms jobs followed by a
2.5ms wait.
Interactive client emites a 10% GPU load in the format of 1x 1ms job followed
by a 9ms wait.
This simulates an interactive graphical client used on top of a relatively heavy
background load but no GPU oversubscription.
Graphs show the interactive client only and from now on, instead of looking at
the client's queue depth, we look at its "fps".
https://people.igalia.com/tursulin/drm-sched-qddl/heavy-interactive.png
We can see that qddl allows a slighty higher fps for the interactive client
which is good.
5. Low priority GPU hog versus heavy-interactive.
Low priority client: 3x 2.5ms jobs client followed by a 0.5ms wait.
Interactive client: 1x 0.5ms job followed by a 10ms wait.
https://people.igalia.com/tursulin/drm-sched-qddl/lowhog-interactive.png
No difference between the schedulers.
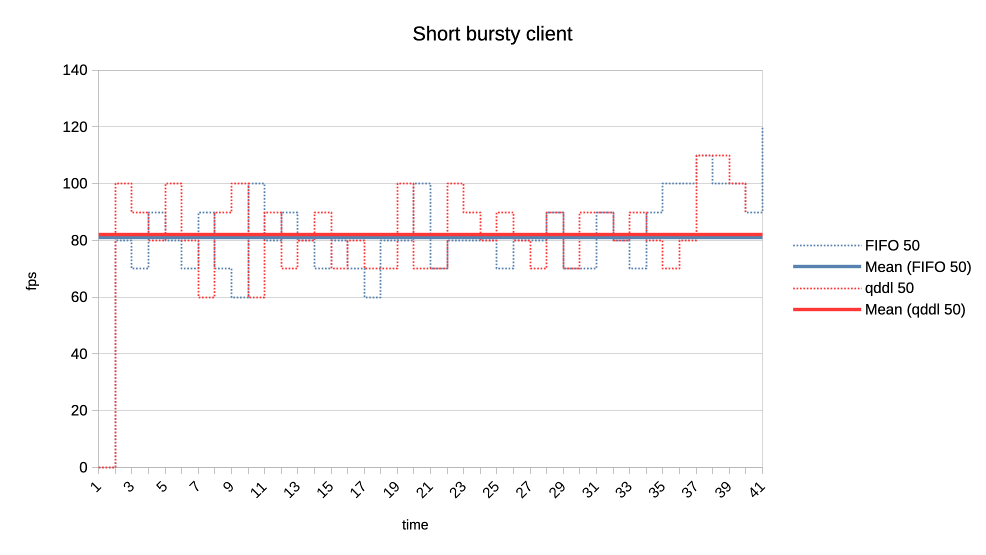
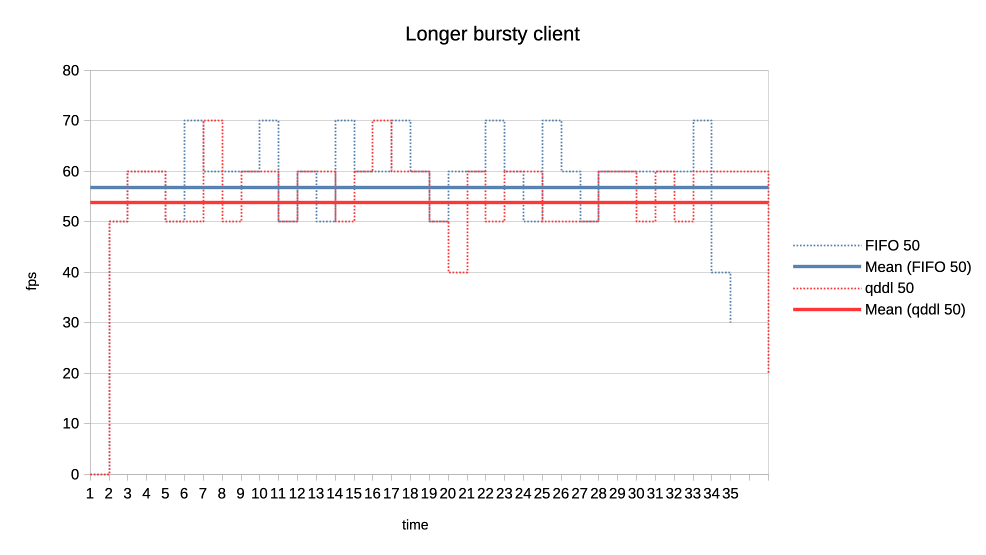
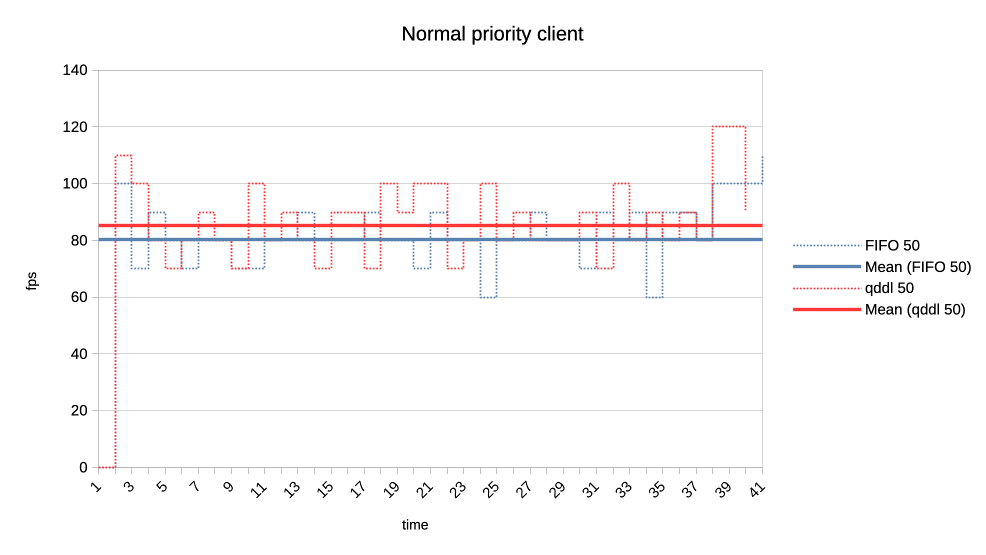
6. Last set of test scenarios will have three subgroups.
In all cases we have two interactive (synchronous, single job at a time) clients
with a 50% "duty cycle" GPU time usage.
Client 1: 1.5ms job + 1.5ms wait (aka short bursty)
Client 2: 2.5ms job + 2.5ms wait (aka long bursty)
a) Both normal priority.
https://people.igalia.com/tursulin/drm-sched-qddl/5050-short.png
https://people.igalia.com/tursulin/drm-sched-qddl/5050-long.png
Both schedulers favour the higher frequency duty cycle with qddl giving it a
little bit more which should be good for interactivity.
b) Normal vs low priority.
https://people.igalia.com/tursulin/drm-sched-qddl/5050-normal-low-normal.png
https://people.igalia.com/tursulin/drm-sched-qddl/5050-normal-low-low.png
Qddl gives a bit more to the normal than low.
c) High vs normal priority.
https://people.igalia.com/tursulin/drm-sched-qddl/5050-high-normal-high.png
https://people.igalia.com/tursulin/drm-sched-qddl/5050-high-normal-normal.png
Again, qddl gives a bit more share to the higher priority client.
On the overall qddl looks like a potential improvement in terms of fairness,
especially avoiding priority starvation. There do not appear to be any
regressions with the tested workloads.
As before, I am looking for feedback, ideas for what kind of submission
scenarios to test. Testers on different GPUs would be very welcome too.
And I should probably test round-robin at some point, to see if we are maybe
okay to drop unconditionally, it or further work improving qddl would be needed.
v2:
* Fixed many rebase errors.
* Added some new patches.
* Dropped single shot dependecy handling.
v3:
* Added scheduling quality unit tests.
* Refined a tiny bit by adding some fairness.
* Dropped a few patches for now.
Cc: Christian König <christian.koe...@amd.com>
Cc: Danilo Krummrich <d...@redhat.com>
Cc: Matthew Brost <matthew.br...@intel.com>
Cc: Philipp Stanner <pstan...@redhat.com>
Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-pra...@amd.com>
Cc: Michel Dänzer <michel.daen...@mailbox.org>
Tvrtko Ursulin (14):
drm/sched: Add some scheduling quality unit tests
drm/sched: Avoid double re-lock on the job free path
drm/sched: Consolidate drm_sched_job_timedout
drm/sched: Clarify locked section in drm_sched_rq_select_entity_fifo
drm/sched: Consolidate drm_sched_rq_select_entity_rr
drm/sched: Implement RR via FIFO
drm/sched: Consolidate entity run queue management
drm/sched: Move run queue related code into a separate file
drm/sched: Add deadline policy
drm/sched: Remove FIFO and RR and simplify to a single run queue
drm/sched: Queue all free credits in one worker invocation
drm/sched: Embed run queue singleton into the scheduler
drm/sched: De-clutter drm_sched_init
drm/sched: Scale deadlines depending on queue depth
drivers/gpu/drm/amd/amdgpu/amdgpu_cs.c | 6 +-
drivers/gpu/drm/amd/amdgpu/amdgpu_job.c | 27 +-
drivers/gpu/drm/amd/amdgpu/amdgpu_job.h | 5 +-
drivers/gpu/drm/amd/amdgpu/amdgpu_trace.h | 8 +-
drivers/gpu/drm/amd/amdgpu/amdgpu_vm_sdma.c | 8 +-
drivers/gpu/drm/amd/amdgpu/amdgpu_xcp.c | 8 +-
drivers/gpu/drm/scheduler/Makefile | 2 +-
drivers/gpu/drm/scheduler/sched_entity.c | 121 ++--
drivers/gpu/drm/scheduler/sched_fence.c | 2 +-
drivers/gpu/drm/scheduler/sched_internal.h | 17 +-
drivers/gpu/drm/scheduler/sched_main.c | 581 ++++--------------
drivers/gpu/drm/scheduler/sched_rq.c | 188 ++++++
drivers/gpu/drm/scheduler/tests/Makefile | 3 +-
.../gpu/drm/scheduler/tests/tests_scheduler.c | 548 +++++++++++++++++
include/drm/gpu_scheduler.h | 17 +-
15 files changed, 962 insertions(+), 579 deletions(-)
create mode 100644 drivers/gpu/drm/scheduler/sched_rq.c
create mode 100644 drivers/gpu/drm/scheduler/tests/tests_scheduler.c
--
2.48.0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}