Marco Antoniotti wrote: > Unicode et similia and XML are orthogonal concerns. You can have XML > (*) manipulation (look around for the CL-XML or CXML libraries on > common-lisp.net plus a godzillion other ones I forgot) without Unicode > etc. These libraries are quite portable.
but these libraries have to deal with the XML data then as binary data and they have to evaluate the initial 2 bytes at least, because if they think it is plain ASCII, an XML file which is valid in utf-16 format becomes invalid. Lets take this XML file as an example (you can download the file at http://www.frank-buss.de/tmp/utf16.xml and it looks like this in UltraEdit and Internet Explorer: http://www.frank-buss.de/tmp/utf16.png ) ab<?xml version="1.0" encoding="utf-16"?> <test>cd</test> where "xy" is #xFEFF (the "zero width no-break space" character as a byte order mark to indicate that it is an utf-16 encoded XML file) and "cd" is 0x7c3c, a character from the CJK Unified Ideographs (the w3c XML standard allows any character in the range of [#x20-#xD7FF]) and all other characters are encoded as utf-16. Then a parser, which assumes ASCII, will read it as an illegal XML file, because 0x7c3c is interpreted as "<", followed by "|", if the parser didn't stopped earlier already when reading the first binary 0. -- Frank Buß, [EMAIL PROTECTED] http://www.frank-buss.de, http://www.it4-systems.de _______________________________________________ Gardeners mailing list [email protected] http://www.lispniks.com/mailman/listinfo/gardeners
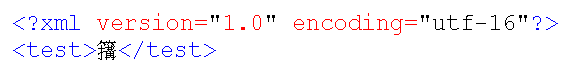{kind=link}