Ted-Jiang commented on code in PR #2156:
URL: https://github.com/apache/arrow-datafusion/pull/2156#discussion_r845198369
##########
datafusion/physical-expr/src/expressions/in_list.rs:
##########
@@ -32,13 +33,19 @@ use arrow::{
record_batch::RecordBatch,
};
-use crate::PhysicalExpr;
+use crate::{expressions, PhysicalExpr};
use arrow::array::*;
use arrow::buffer::{Buffer, MutableBuffer};
use datafusion_common::ScalarValue;
use datafusion_common::{DataFusionError, Result};
use datafusion_expr::ColumnarValue;
+/// Size at which to use a Set rather than Vec for `IN` / `NOT IN`
+/// Value chosen to be consistent with Spark
+///
https://github.com/apache/spark/blob/4e95738fdfc334c25f44689ff8c2db5aa7c726f2/sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala#L259-L265
+/// TODO: add switch codeGen in In_List
+static OPTIMIZER_INSET_THRESHOLD: usize = 10;
Review Comment:
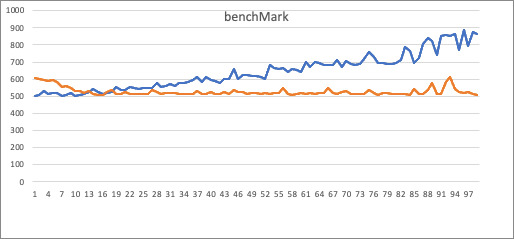
`X`: cost time. `Y`: filter value numbers
`Blue`: is use List, `orange`: is use Set.
I did a benchMark in my local, use `select count(*) from orders where
o_orderkey in (x1, x2, ..., xn)`
Obviously, Set has a fixed gradient, List cost time increases with the
parameter number.
The intersection of the two lines is located is between 10~20 (same as Spark
set 10).
So, i decided set `OPTIMIZER_INSET_THRESHOLD ` = 10 align with spark.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}