Dandandan edited a comment on pull request #9588: URL: https://github.com/apache/arrow/pull/9588#issuecomment-790962611
@yordan-pavlov Would be very interested in a faster parquet reader. Was doing some benchmarking with some queries in DataFusion with Parquet, looks like there is a lot to win in Parquet when looking at profiling results. For example, query 5 showing about 50% of instruction fetches are for reading parquet: 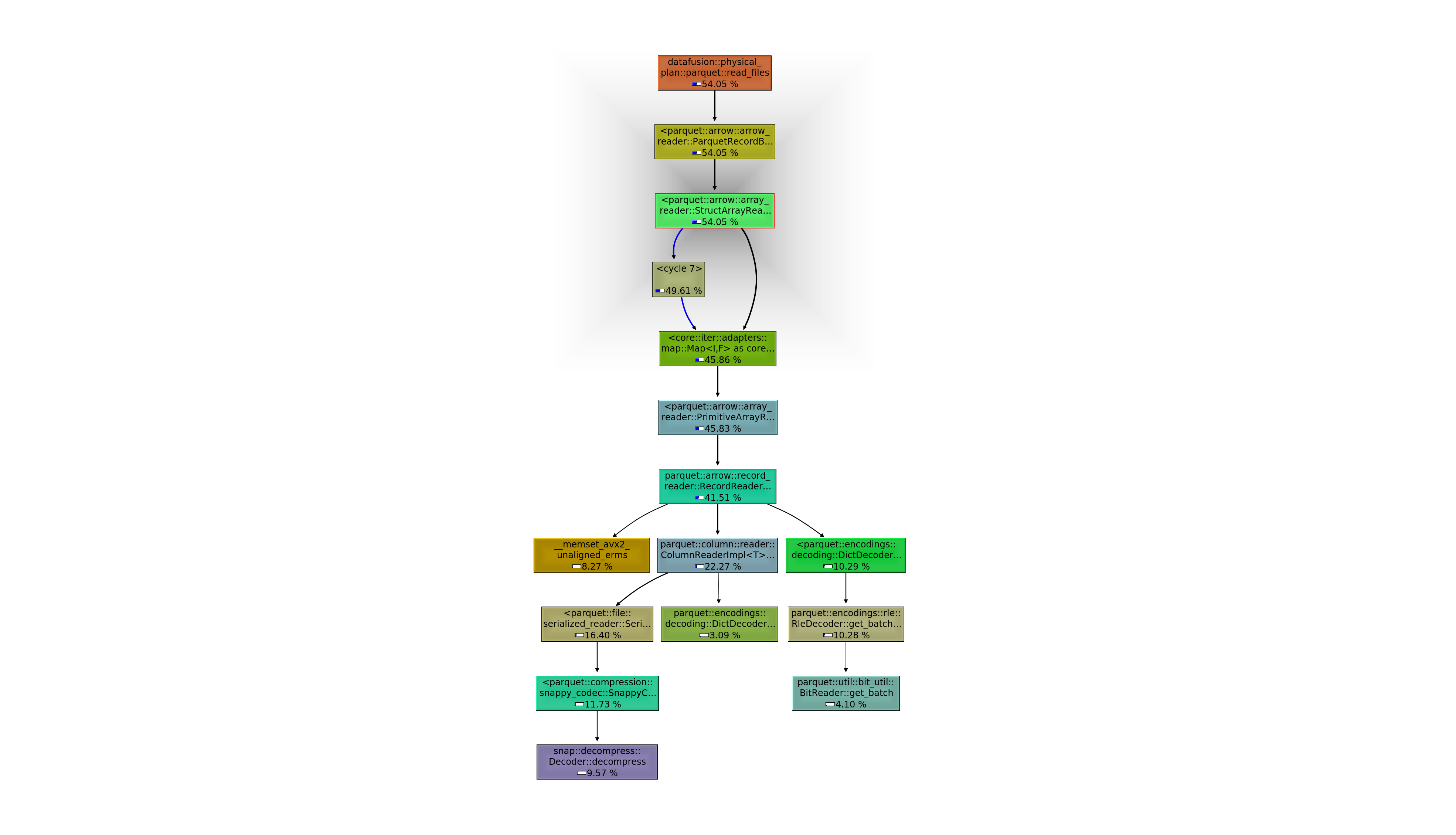 And reading all the parquet files of the benchmark to memory (and running some queries) (left inclusive % instruction fetch, right self %).:  ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}