lidavidm commented on pull request #9620: URL: https://github.com/apache/arrow/pull/9620#issuecomment-812679493
The benchmark discrepancy is simply because the generator was putting each row group on its own thread. The difference goes away if we don't force transfer onto a background thread. With that fixed, here are benchmarks of reentrant Parquet + ARROW-7001 on EC2: 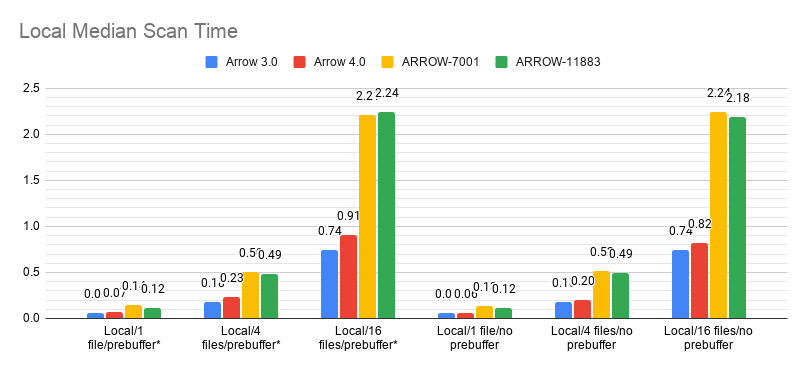 (note that Arrow 3.0 didn't have pre-buffering, so the results are duplicated here) 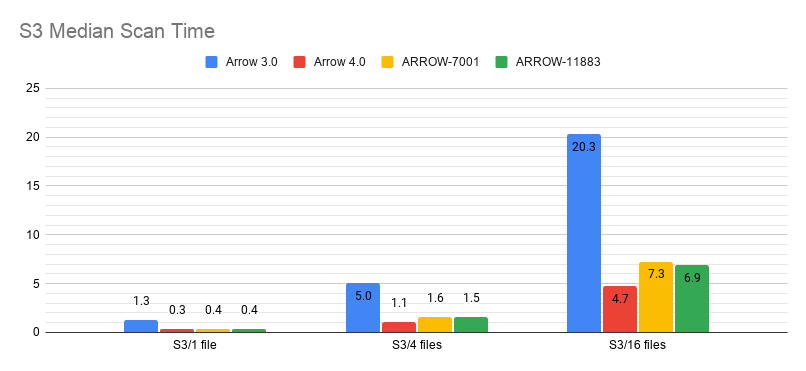 - Prebuffering appears to have no impact locally, so maybe we should always enable it. - Non-prebuffered cases (except Arrow 3.0) are omitted from the S3 graphs because it's so much slower and skews the graphs. That is, ARROW-7001 without prebuffering took about ~75 seconds to read 16 files from S3, which is a significant regression from even the non-prebuffered Arrow 3.0 case. - Local files have heavily regressed and need more investigation. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}