lidavidm commented on pull request #9620: URL: https://github.com/apache/arrow/pull/9620#issuecomment-812701516
Okay, now that I've actually checked out the right branch… So long as pre-buffering is enabled, this PR in conjunction with ARROW-7001 is either a big win (for S3) or no effect (locally). Hence I'd argue we should just always enable pre-buffer. (The reason is that without refactoring the Parquet reader heavily, without enabling pre-buffer, the generator is effectively synchronous. I could go through and do the refactor, but pre-buffering gives us an 'easy' way to convert the I/O to be async. If we want, we could change the read range cache to optionally be lazy, which would effectively be the same as refactoring the Parquet reader.) Also, this changes the ParquetScanTask so that it manages intra-file concurrency internally. Hence, ParquetFileFragment only needs to generate one scan task now and doesn't have to do anything complicated around pre-buffering. 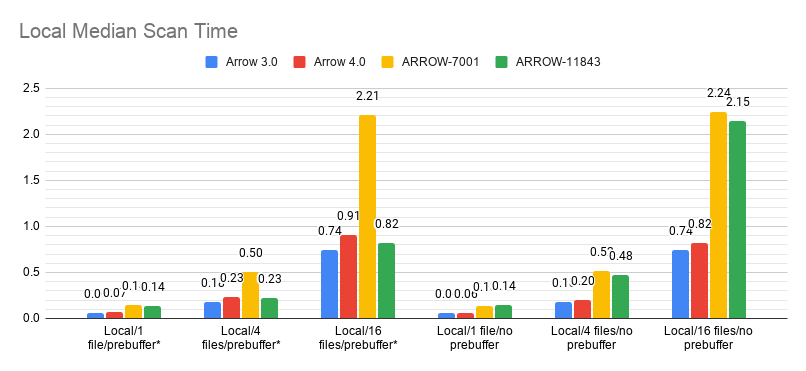 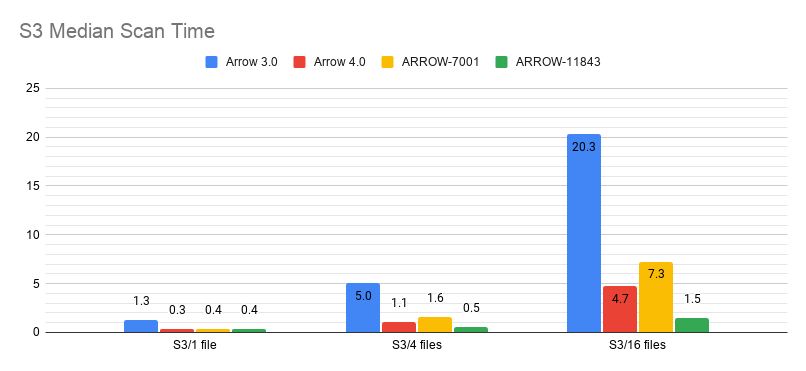 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}