andygrove commented on pull request #1556: URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1013718590
Here are some quick benchmark results comparing the master branch and this PR, running on a threadripper desktop with 24 cores and an NVMe drive. I ran each query once only. These are the commands that I ran: ``` cargo build --release cd benchmarks cargo run --release --bin tpch -- benchmark datafusion --iterations 1 --path /mnt/bigdata/tpch/sf100-24part-parquet --format parquet --query 13 --batch-size 4096 --partitions 24 ``` 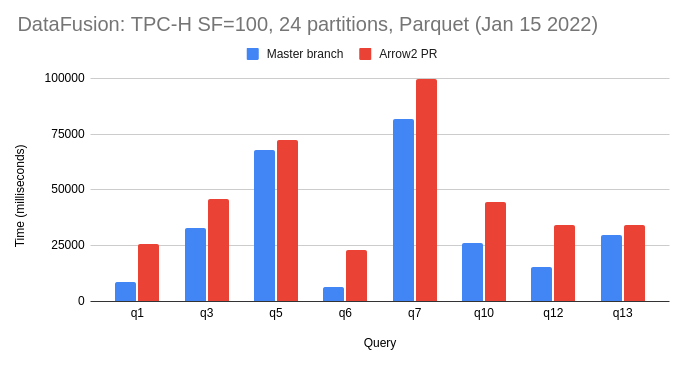 Queries 1 and 6 were both at least 3x slower and query 12 was more than 2x slower. I used the following commits: Master: 1c39f5ce865e3e1225b4895196073be560a93e82 Arrow2: e53d165f018a54d47f80ff2a132f83cee363c79c I will poke around a bit myself this weekend and see if I can debug this based on metrics to try and determine where the performance issues are. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}