danthev commented on a change in pull request #14723:
URL: https://github.com/apache/beam/pull/14723#discussion_r637178001
##########
File path: sdks/python/apache_beam/io/gcp/datastore/v1new/datastoreio.py
##########
@@ -276,15 +277,33 @@ class _Mutate(PTransform):
Only idempotent Datastore mutation operations (upsert and delete) are
supported, as the commits are retried when failures occur.
"""
- def __init__(self, mutate_fn):
+
+ # Default hint for the expected number of workers in the ramp-up throttling
+ # step for write or delete operations.
+ _DEFAULT_HINT_NUM_WORKERS = 500
Review comment:
I've thought about this before. Generally what I would expect is a slow
start, but autoscaling quickly scaling up when the throttling limit increases,
yielding a similar result to starting with the desired number of workers.
However, I was weighing whether to report `throttling-msecs` or if that
stifles autoscaling (the Firestore implementation reports it). I thought I
remembered previous test showing not much of a difference, but I've run a few
more tests and I do see a significant difference now. This is an example I ran
with the Java implementation and `maxNumWorkers` at 50, where I commented out
incrementing the `throttling-msecs` counter:
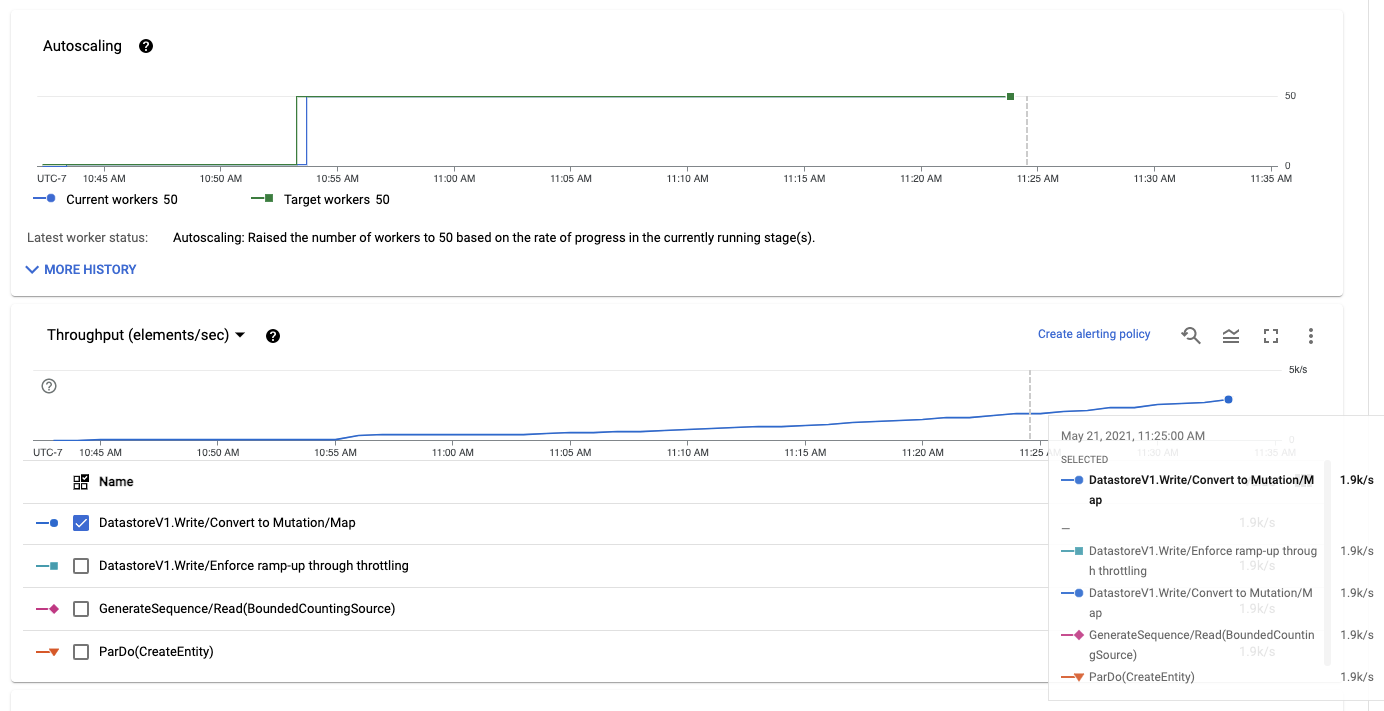
That's about what I would expect, autoscaling scales up after 10-15 minutes,
then the ramp-up proceeds normally. I just ran that same example with the
original implementation, reporting `throttlingMs`, and Dataflow seems prone to
getting stuck at 1 worker with very little throughput.
So if I drop `throttling-msecs`, autoscaling should be fairly normal in
terms of behavior. Are there other side effects with autoscaling I should
consider?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}