Thesharing edited a comment on pull request #19275: URL: https://github.com/apache/flink/pull/19275#issuecomment-1084449612
> Thanks @Thesharing for your contribution. I looked into it and was wondering whether you also considered utilizing the chaining of the `CompletableFutures` within `handleJobManagerRunnerResult` as a possible solution. Right now (on `master`), `jobReachedTerminalState` archives the `ExecutionGraph` on the main thread, triggers the archiving of the `ExecutionGraph` in the history server if terminated globally, and adding the job to the `JobResultEntry` afterwards (in case of a globally terminated state). In your solution you're passing the result future of the history server archiving through this new class `JobTerminalState` and chain the history server archiving result later on. > > What about making the `handleJobManagerRunnerResult` and `jobManagerRunnerFailed` return a `CompletableFuture<CleanupJobState>` that completes in the case of a globally terminal job state after the history server archiving took place and the JobResultStore entry was written. WDYT? Thank you so much for your review and suggestions, @XComp! 😄 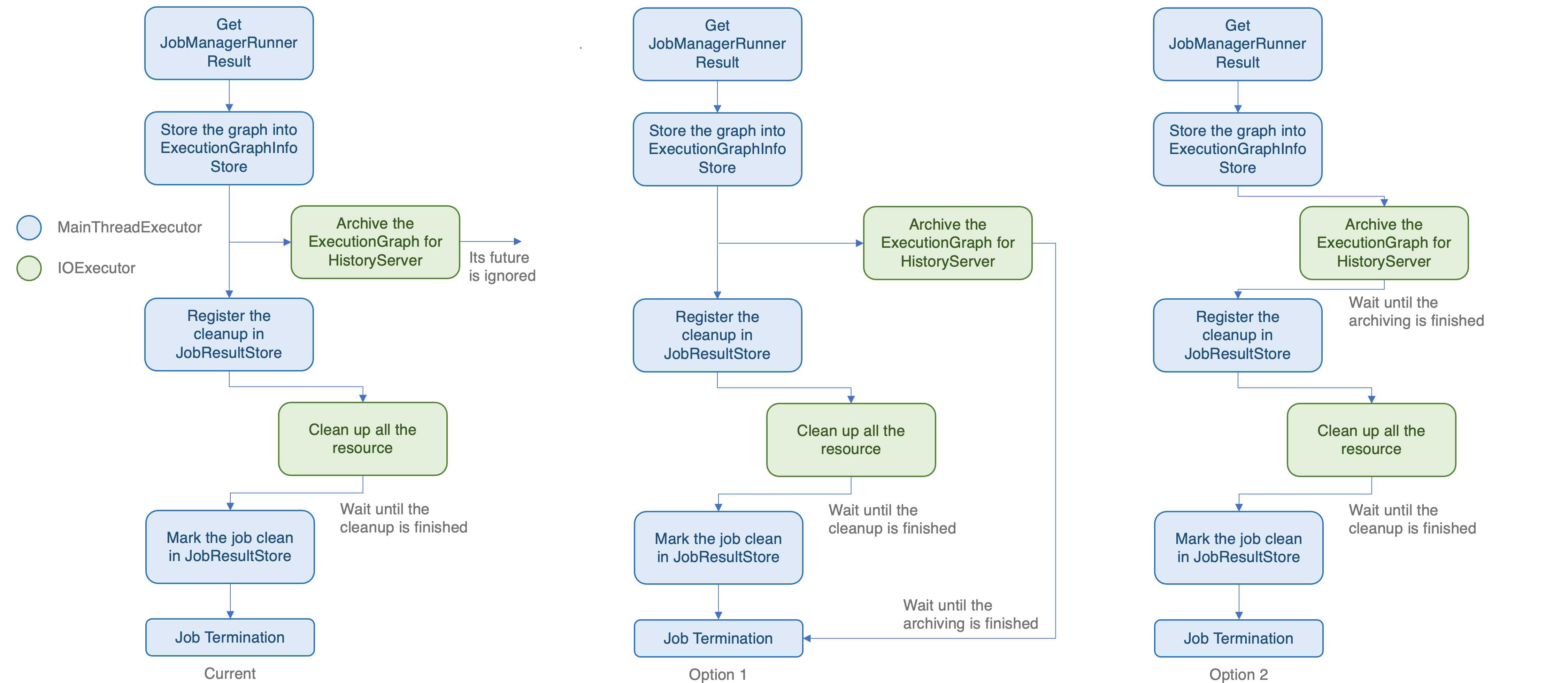 I draw an illustration for two options. Option 1 chains the result future of archiving and the result future of resource cleanup. Option 2 makes the `handleJobManagerRunnerResult` and `jobManagerRunnerFailed` return a `CompletableFuture<CleanupJobState>`. Option 1 could parallelize two IO operations. Furthermore, if the archiving takes a long time in the worst case, the job may be terminated by users or external resource providers. In this situation, the job still get cleaned up. Therefore, I think maybe option 1 is better. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}