txdong-sz commented on issue #1914: URL: https://github.com/apache/iceberg/issues/1914#issuecomment-744311338
@HeartSaVioR the reson why i need to use spark and flink is that 1. flink is not support by partition by hour 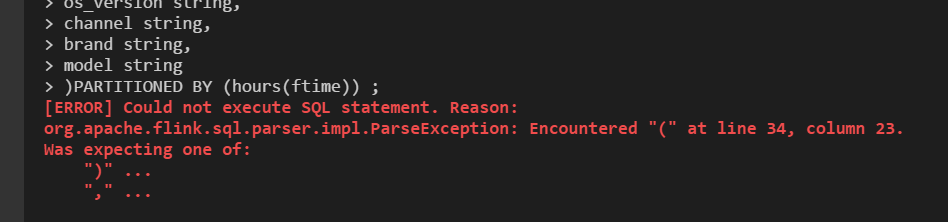 and my table is very huge . that is not a good parctice 2. flink sql is standalone . my table is huge ,so i need more resource to run sql and choose spark we use flink to write stream data to cos . it is of efficiency ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}