zhangjun0x01 commented on issue #1914: URL: https://github.com/apache/iceberg/issues/1914#issuecomment-747146918
> @HeartSaVioR the reson why i need to use spark and flink is that > > 1. flink is not support by partition by hour > 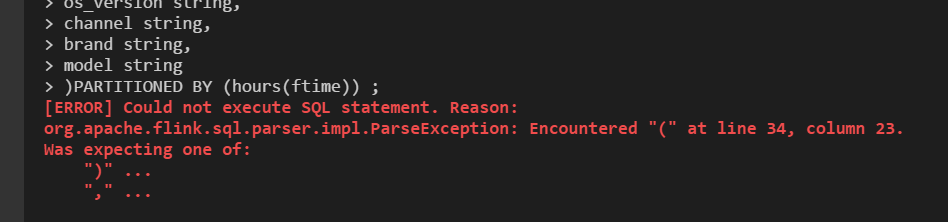 > and my table is very huge . that is not a good parctice > 2. flink sql is standalone . my table is huge ,so i need more resource to run sql and choose spark > > we use flink to write stream data to cos . it is of efficiency 1. you can create an iceberg table with flink sql ``` CREATE TABLE iceberg.iceberg_db.iceberg_table ( id BIGINT COMMENT 'unique id', data STRING, `day` int `hour` int) PARTITIONED BY (`day`,`hour`) WITH ('connector'='iceberg','write.format.default'='orc') ``` and write into the iceberg table with flink streaming sql : ``` INSERT INTO iceberg.iceberg_db.iceberg_table select id ,data,DAYOFMONTH(your_timestamp),hour(your_timestamp) from kafka_table ``` 2. flink sql client can use standalone cluster and yarn session cluster , you can start a yarn session cluster first ,and then submit the flink sql job to the session cluster . 3. and set the parallelism for every flink sql job by the command: ``` set table.exec.resource.default-parallelism = 100 ``` ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}