I have modeled the problem in alternative way, like suggested by Michael. This are trips for the Truck 'Meyer'.
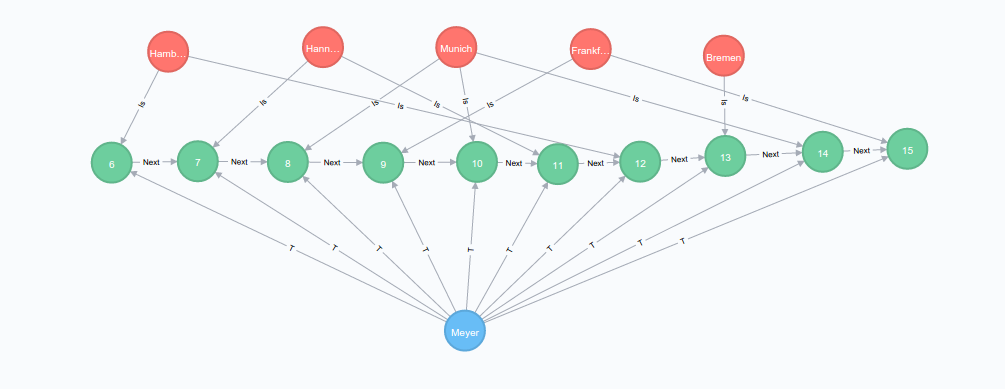
<https://lh4.googleusercontent.com/-3BfcmM4zfnY/VO2wAI6aMwI/AAAAAAAAAAM/jmEwZ68TbfU/s1600/alternative_graph.png> How ever while playing with it, I am facing some problems: I want to know all trips from Hamburg to Munich. And I want to get the sequence of city names for these trips. And I want only direct trips (ever stop should occur only once). I did not mange to 'join in' the city names so I stored the city names as properties on the sequence nodes. With that I ended up with this query: match (:City {name:'Hamburg'})-[:Is]->(s1:Stop) match (:City {name:'Munich'})-[:Is]->(s2:Stop) match path = (s1)-[:Next*1..2]->(s2) WHERE ALL (n IN extract(x IN nodes(path)| x.name) WHERE 1=length(filter(m IN extract(x IN nodes(path)| x.name) WHERE m=n))) return extract( n in nodes(path)| n.name); However performance wise, I do not get big advantages above my optimized other approach. Any tips? Here is the a link to the console populated with the test graph: http://console.neo4j.org/r/yv6ex1 On Wednesday, February 18, 2015 at 5:07:20 PM UTC+1, Michael Hunger wrote: > > 50k trucks are not an issue > Rel-indexes are legacy and only used when you really need them > > The tricks is not to use more indexes but a graph model that supports your > queries > > M > > Von meinem iPhone gesendet > > Am 18.02.2015 um 11:02 schrieb [email protected] <javascript:> > : > > Thanks, Michael. > > I will end up with 50.000 trucks. > > Here is my Expander: > > public Iterable expand(Path path, BranchState state) { > // for the start node return all outgoing connections > if (path.length() < 1){ > return path.endNode().getRelationships(Direction.OUTGOING); > } else { > // for all consecutive nodes only return relations with same ID > and with the next sequence number > > // get previuos sequence > Integer seq = > (Integer)path.lastRelationship().getProperty(SEQUENCE); > // increase the sequence by one to find the next sequence > Integer nextSeq = seq+1; > > // get ID > Object lastID = path.lastRelationship().getProperty(ID); > > ArrayList<Relationship> result = new ArrayList<>(); > > // get all outgoing rleationsships for end node > Iterable<Relationship> trips = > path.endNode().getRelationships(Direction.OUTGOING, TRIP); > for (Relationship trip : trips) { > // only return is ID is equal and sequence is the next sequence > if (lastID.equals(rel.getProperty(ID, null))){ > if (nextSeq.equals((Integer)rel.getProperty(SEQUENCE, > null))){ > result.add(rel); > } > } > > return result; > > } > } > > The while loop over all relations is definitely sub-optimal. Just > yesterday I discovered the legacy indexes for relations. I am going to give > them a try. They seem to be a perfect fit. Can I query the index with > multiple fields? > I have also already been using the ID as relationship type with great > improvements. > > I have also thought ow would this be > > Thanks for the option 2. Might be worth a try! > > Is Cypher in general behaving better than Java code? Or is the trick in > using as much indexes as possible? > > Patrick > > > > On Wednesday, February 18, 2015 at 10:07:59 AM UTC+1, Michael Hunger wrote: >> >> Perhaps you can share some of your Expander code? >> >> Not really sure between what your edges are? >> >> >> Two ideas: >> >> 1) How many trucks do you have? Perhaps it makes sense to encode the >> truck-id as relationship-type? So you have fewer rels to check and can >> benefit from the separated storage by rel-type and direction. >> 2) Model the trip as a node connected to a truck, and all locations it >> visited (perhaps/optionally even encode the location-id as rel-id but that >> might be overkill) so you can quickly find all that started at "A" and then >> check if the trip has a rel to "B" >> >> 3) Another more verbose approach be to model each trip as a sequence of >> nodes (which are shadow nodes of the locations), connect the start-node of >> the trip to the truck (optionally all trip-nodes of the trip to the truck). >> And then have a relationship to each stop of the trip. >> >> I'd probably go with model #2 >> >> HTH Michael >> >> >> Am 16.02.2015 um 12:54 schrieb [email protected]: >> >> I need some modelling advice. >> >> We want to store and analyse movement patterns. Think of trucks moving >> through a logistic's networks. >> We want to ask which truck has ever moved from location A to location B >> and what was the sequence of intermediate stops they made to get there. >> >> In a later stage we also want to be able to ask this question if there is >> no truck that has stopped at location A and B. Which trucks and which >> sequence of stops would we have needed to get from A to B. >> >> Right now we modeled all locations as nodes and every trip a truck has >> ever made as a separate edge. The edges are attributed with a truck ID and >> a sequence number. >> We wrote our custom expander class to be used with the traversal >> framework and to take care of the sequence numbers and truck IDs to only >> get complete sequences for individual trucks. >> >> However, this performs very badly. >> Right now we have 300 locations/nodes and 300.000 trips/edges. Some stops >> have 20.000 outgoing trips that we are checking for truck ID and sequence >> number (for every outgoing relationship, get attributes and check) . >> This performs too badly. 13 seconds for 900 sequences. >> >> Finally, we want to try to scale it to 3000 locations and 20.000.000 >> trips. >> >> >> Do you have any alternative modelling ideas? >> >> Thanks a lot already. >> >> >> ps: I was thinking of storing every trucks list as a long linear >> sequence of stops/nodes. The nodes are additionally linked to some >> identifier Node through a type of is relation: "stop x is location A". >> >> -- >> You received this message because you are subscribed to the Google Groups >> "Neo4j" group. >> To unsubscribe from this group and stop receiving emails from it, send an >> email to [email protected]. >> For more options, visit https://groups.google.com/d/optout. >> >> >> -- > You received this message because you are subscribed to the Google Groups > "Neo4j" group. > To unsubscribe from this group and stop receiving emails from it, send an > email to [email protected] <javascript:>. > For more options, visit https://groups.google.com/d/optout. > > -- You received this message because you are subscribed to the Google Groups "Neo4j" group. To unsubscribe from this group and stop receiving emails from it, send an email to [email protected]. For more options, visit https://groups.google.com/d/optout.
{kind=link}