runzhiwang opened a new pull request #734: HDDS-3240. Improve write efficiency by creating container in parallel URL: https://github.com/apache/hadoop-ozone/pull/734 ## What changes were proposed in this pull request? What's the problem ? Now follower cannot create container until leader finish creating container. But follower and leader can create container in parallel rather than in sequential. Why leader and follower create container in sequential now ? 1. From the code, the [future thread](https://github.com/apache/hadoop-ozone/blob/master/hadoop-hdds/container-service/src/main/java/org/apache/hadoop/ozone/container/common/transport/server/ratis/ContainerStateMachine.java#L672) do `getCachedStateMachineData ` in `readStateMachineData `and the [future thread](https://github.com/apache/hadoop-ozone/blob/master/hadoop-hdds/container-service/src/main/java/org/apache/hadoop/ozone/container/common/transport/server/ratis/ContainerStateMachine.java#L459) do `createContainer` in `writeStateMachineData `are the same [thread](https://github.com/apache/hadoop-ozone/blob/master/hadoop-hdds/container-service/src/main/java/org/apache/hadoop/ozone/container/common/transport/server/ratis/ContainerStateMachine.java#L505). Because `writeStateMachineData `called before `readStateMachineData`. So leader must wait `createContainer `finish then `getCachedStateMachineData `and append logs to the follower, sofollower must wait leader finish `createContainer`. 2. From the jaeger UI, you can also see follower create container after leader finishing it currently. 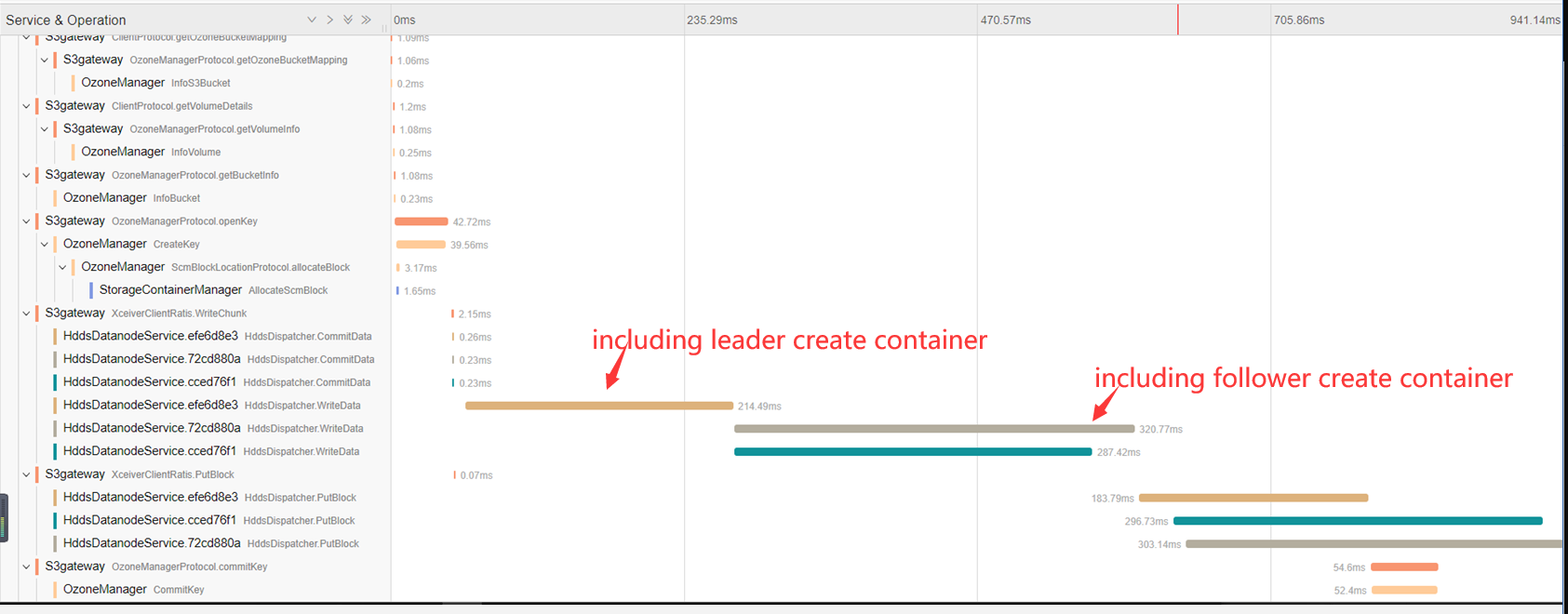 How to improve it ? This order can be improved by distinguishing the thread used by `getCachedStateMachineData ` and `createContainer `, and [data = readStateMachineData(requestProto, term, logIndex)](https://github.com/apache/hadoop-ozone/blob/master/hadoop-hdds/container-service/src/main/java/org/apache/hadoop/ozone/container/common/transport/server/ratis/ContainerStateMachine.java#L619) use same thread with `createContainer `. If [stateMachineDataCache.get(logIndex)](https://github.com/apache/hadoop-ozone/blob/master/hadoop-hdds/container-service/src/main/java/org/apache/hadoop/ozone/container/common/transport/server/ratis/ContainerStateMachine.java#L617) does not return null, leader can get stateMachineData from cache and need not wait `createContainer` finish, thus leader and follower can be independent. But if it return null, leader must finish `createContainer `and then apennd logs to the follower, so I think [data = readStateMachineData(requestProto, term, logIndex)](https://github.com/apache/hadoop-ozone/blob/master/hadoop-hdds/container-service/src/main/java/org/apache/hadoop/ozone/container/common/transport/server/ratis/ContainerStateMachine.java#L619) should use the same thread with `createContainer` rather than the whole [getCachedStateMachineData](https://github.com/apache/hadoop-ozone/blob/master/hadoop-hdds/container-service/src/main/java/org/apache/hadoop/ozone/container/common/transport/server/ratis/ContainerStateMachine.java#L614) ## What is the link to the Apache JIRA https://issues.apache.org/jira/browse/HDDS-3240 ## How was this patch tested? Existed UT and IT
{kind=link}
---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] With regards, Apache Git Services --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]