zhengruifeng edited a comment on issue #27103: [SPARK-30381][ML] Refactor GBT to reuse treePoints for all trees URL: https://github.com/apache/spark/pull/27103#issuecomment-571064302 testcode: ```scala import org.apache.spark.ml.regression._ import org.apache.spark.storage.StorageLevel var df = spark.read.format("libsvm").load("/data1/Datasets/a9a/a9a") (0 until 8).foreach{ _ => df = df.union(df) } df.persist(StorageLevel.MEMORY_AND_DISK) df.count df.count df.count val gbt = new GBTRegressor().setMaxIter(10) val gbtm = gbt.fit(df) val start = System.currentTimeMillis; val gbtm = gbt.fit(df); val end = System.currentTimeMillis; end - start gbtm.evaluateEachIteration(df, "squared") val gbt2 = new GBTRegressor().setMaxIter(10).setSubsamplingRate(0.8) val start = System.currentTimeMillis; val gbtm2 = gbt2.fit(df); val end = System.currentTimeMillis; end - start gbtm2.evaluateEachIteration(df, "squared") ``` result: about 48% faster than existing impl |dur_gbt(new) | dur_gbt2(new) | dur_gbt(old) | dur_gbt2(old) | |------|----------|------------|----------| |133214|134787|197777|188205| |loss(new) | loss2(new) | loss(old) | loss2(old) | |------|----------|------------|----------| |0.4283679582338368|0.42678864636469305|0.4283679582338368|0.42678864636469305| We can see that the convergences of loss are the same. RAM used: existing impl: 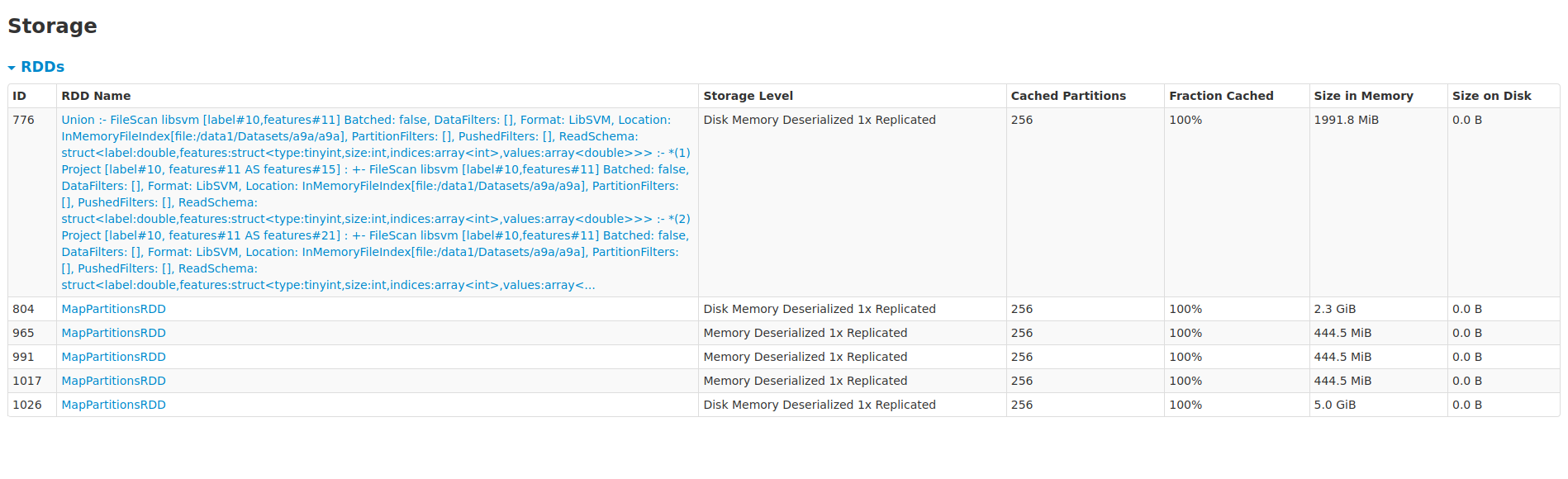 RAM used for training dataset: 2.3G+5.0G=7.3G rdd965/rdd991/rdd1017 are internal rdd at each iteraion this PR: 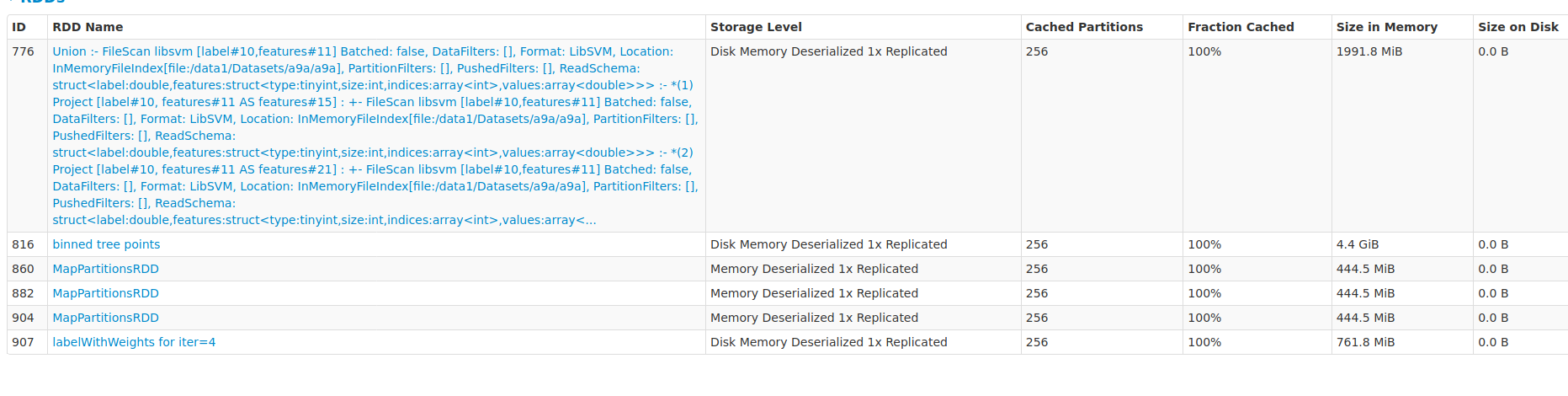 RAM used for training dataset: 4.4G+761M=5.1G
{kind=link}
{kind=link}
---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] With regards, Apache Git Services --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]