zhengruifeng commented on a change in pull request #27519: [SPARK-30770][ML]
avoid vector conversion in GMM.transform
URL: https://github.com/apache/spark/pull/27519#discussion_r386239057
##########
File path: python/pyspark/ml/clustering.py
##########
@@ -252,7 +252,7 @@ class GaussianMixture(JavaEstimator,
_GaussianMixtureParams, JavaMLWritable, Jav
>>> model.predict(df.head().features)
2
>>> model.predictProbability(df.head().features)
- DenseVector([0.0, 0.4736, 0.5264])
+ DenseVector([0.0, 0.0, 1.0])
Review comment:
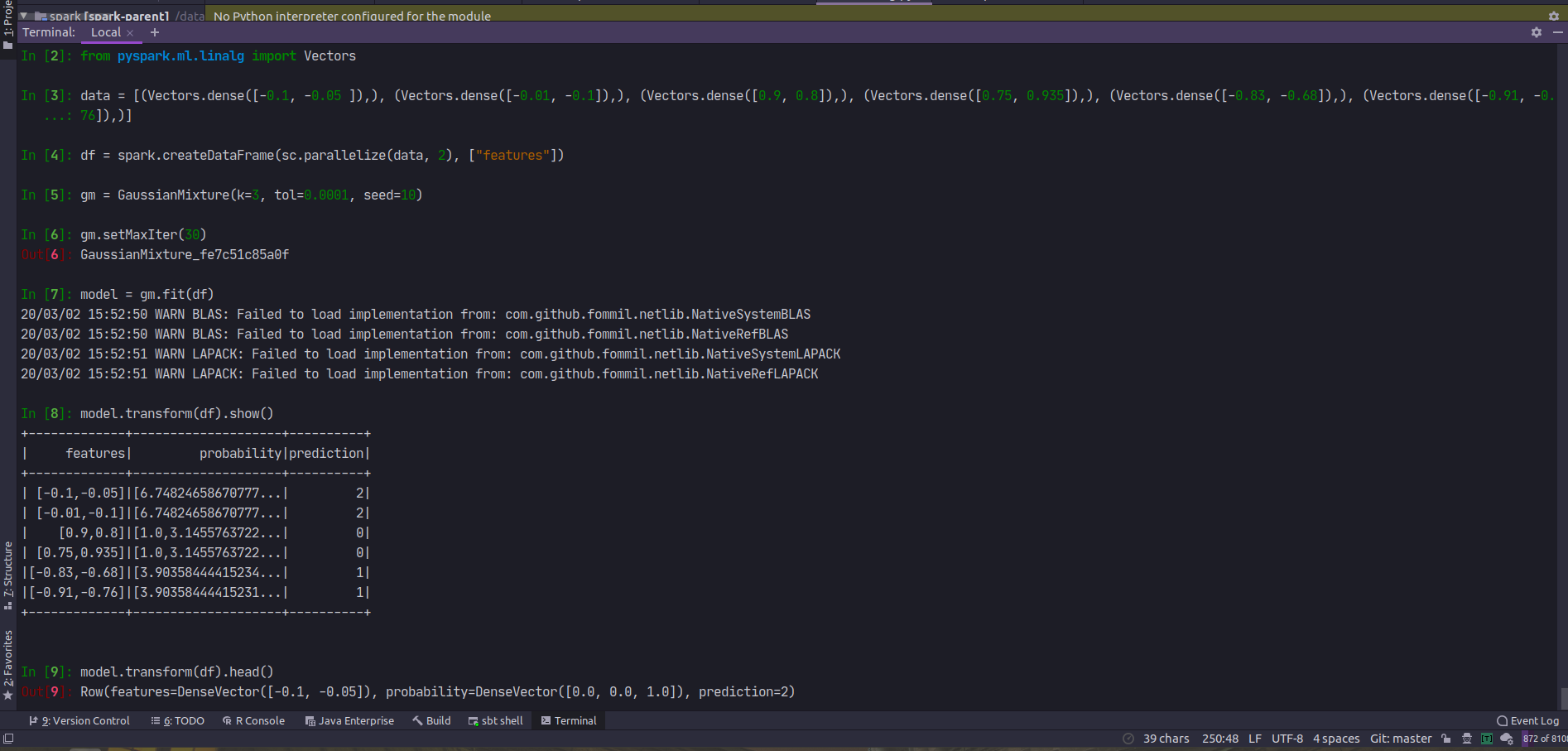
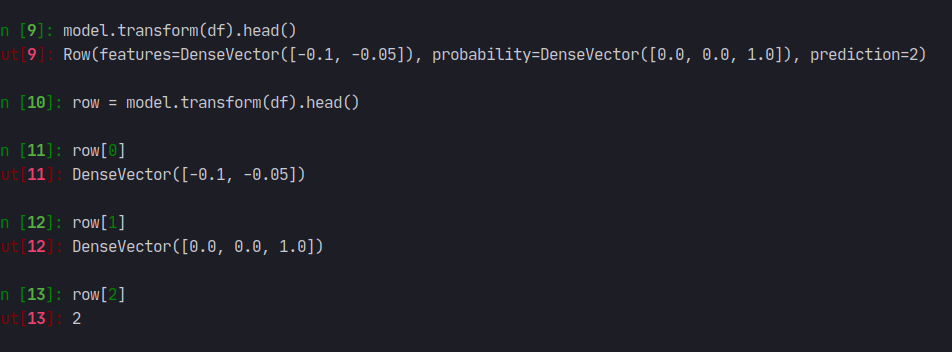
The result in `model.transform(df).show()` are not `DenseVector([0.0, 0.0,
1.0])`, it is about `[6.74824658670777...`;
but the result in `model.transform(df).head()` is `DenseVector([0.0, 0.0,
1.0])`.
Is this a kind of rounding?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}