wangyum opened a new pull request #28032: [WIP][SPARK-31264][SQL] Repartition by dynamic partition columns before insert partition table URL: https://github.com/apache/spark/pull/28032 ### What changes were proposed in this pull request? This PR add two rule `RepartitionBeforeInsertDataSourceTable` and `RepartitionBeforeInsertHiveTable` to support add repartition by dynamic partition columns before insert partition table. ### Why are the changes needed? To ease pressure on the NameNode and improve insert performance. Before this PR. The task will throw exception and create many blocks on HDFS:  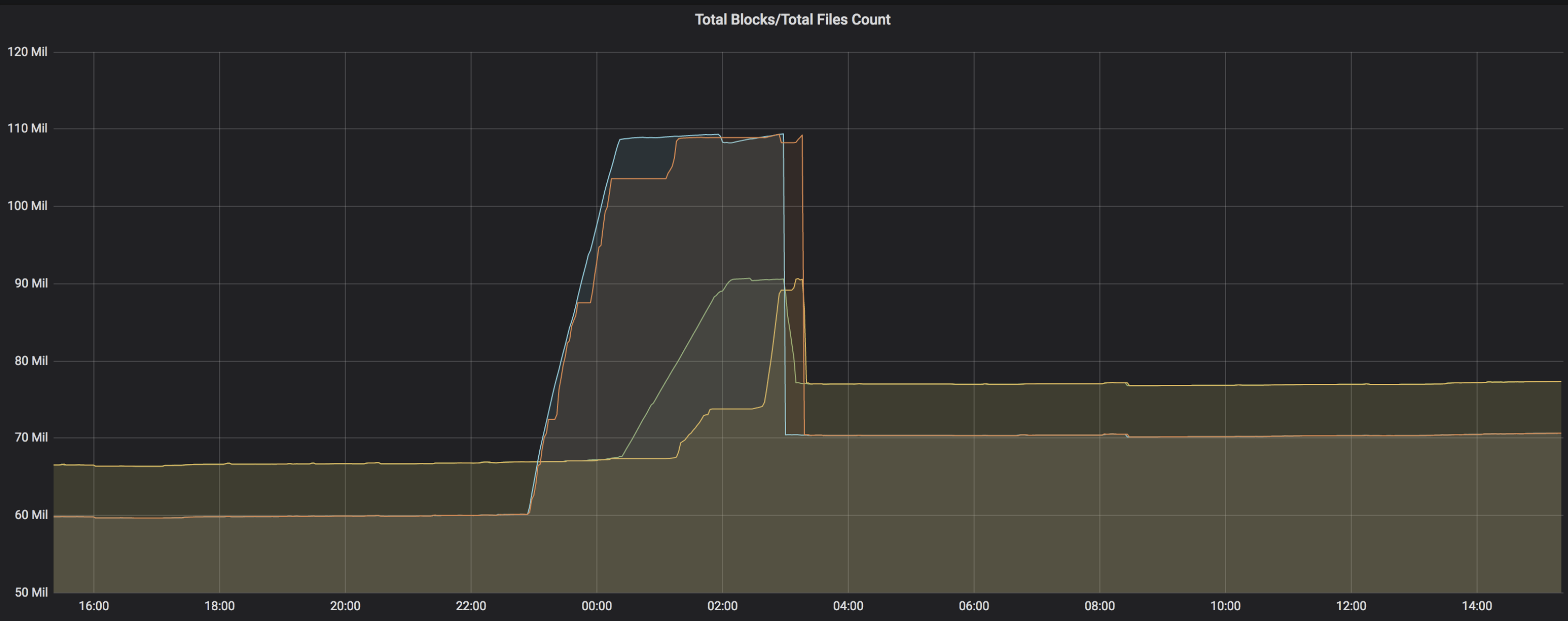 ### Does this PR introduce any user-facing change? No. ### How was this patch tested? Unit test and benchmark test: Query | Before this PR | After this PR -- | -- | -- CREATE TABLE t1 USING parquet PARTITIONED BY (p1, p2) AS (SELECT id, id % 1000 AS p1, id % 10000 AS p2 FROM range(5000000)) | 15 min | 1.1 min
{kind=link}
{kind=link}
---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] With regards, Apache Git Services --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]