manuzhang commented on pull request #28954:
URL: https://github.com/apache/spark/pull/28954#issuecomment-653540634
@JkSelf
I get the same result as you when I set the `numPartitions` of source to 1
(By default, it's 16 on my Mac), i.e.
```scala
val df1 = spark.range(0, 10, 1, 1).withColumn("a", 'id)
val df2 = spark.range(0, 10, 1, 1).withColumn("b", 'id)
val testDf = df1.where('a > 10).join(df2.where('b > 10),
"id").groupBy('a).count()
testDf.collect()
```
Compare the execution plan with above.
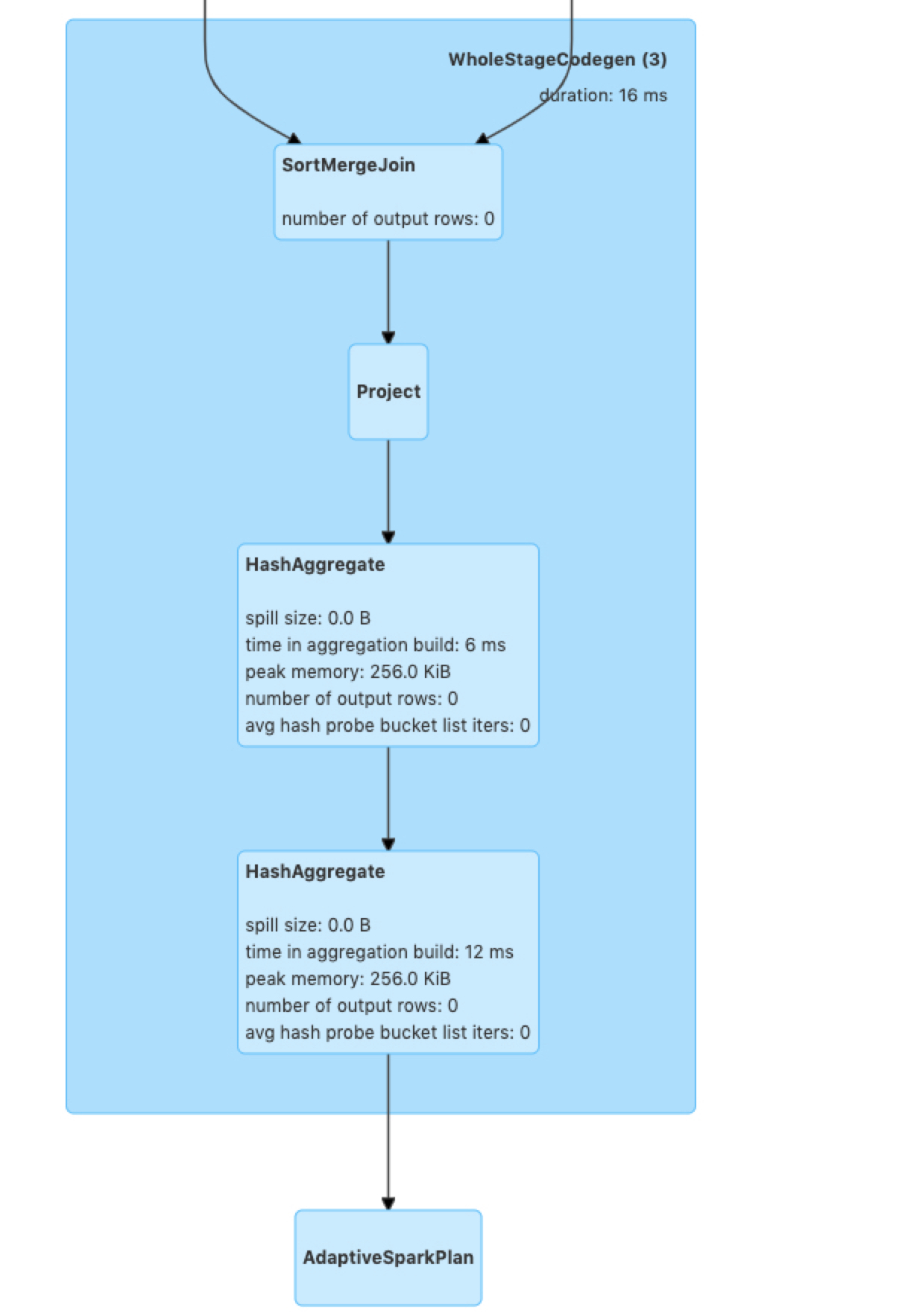
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}