abhishekd0907 commented on a change in pull request #29242:
URL: https://github.com/apache/spark/pull/29242#discussion_r460643781
##########
File path: python/pyspark/sql/dataframe.py
##########
@@ -674,7 +674,7 @@ def cache(self):
.. note:: The default storage level has changed to `MEMORY_AND_DISK`
to match Scala in 2.0.
"""
self.is_cached = True
- self._jdf.cache()
+ self.persist(StorageLevel.MEMORY_AND_DISK)
Review comment:
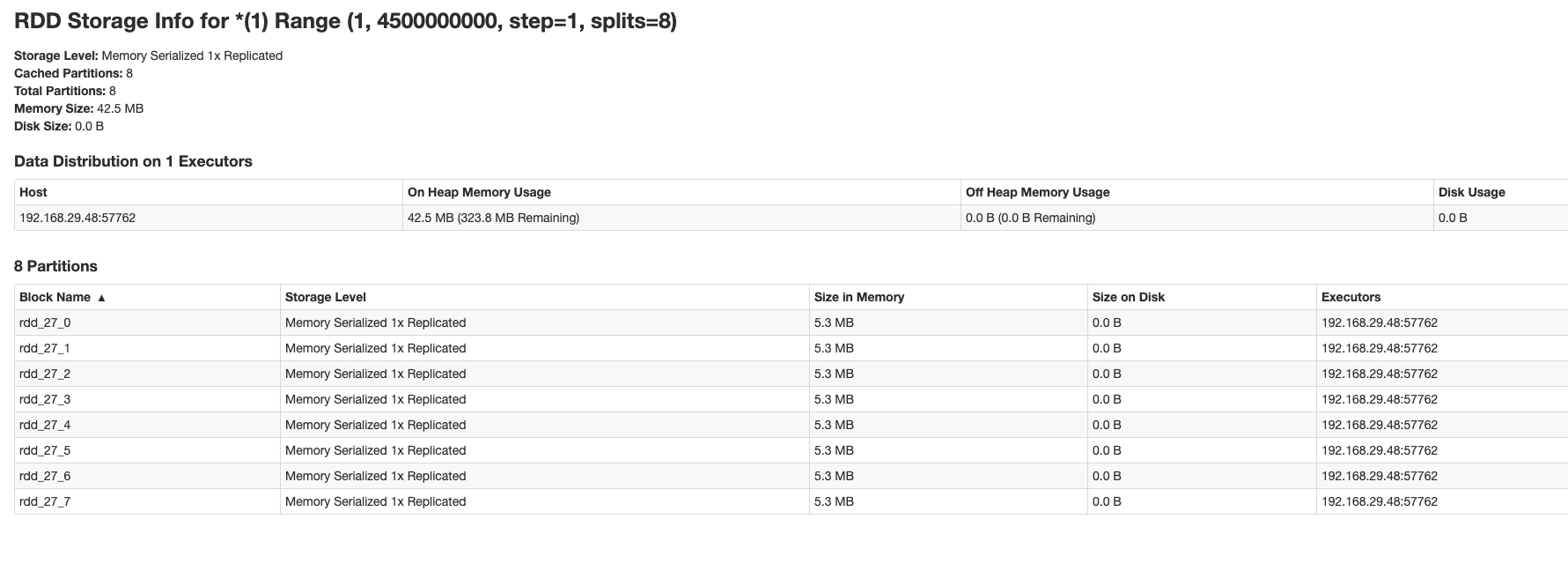
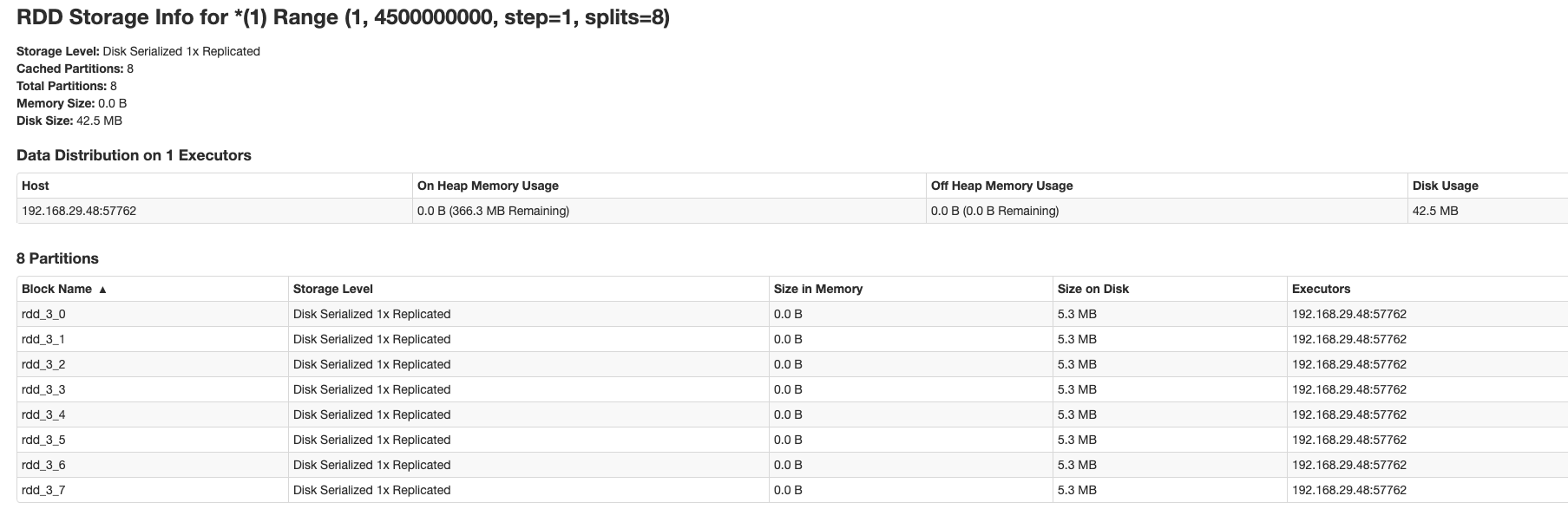
Okay you might be right here but I observed a difference in the behavior
of `pySparkDataframe.cache()` and `pySparkDataframe.persist()` because of
differences in Storage Levels. When `cache()` is used, RDDs are spilled to disk
but when `persist()` is used RDDs are persisted in memory.
This is because `MemoryStore#putIteratorAsValues()` is used when `cache()`
is called and `MemoryStore#putIteratorAsBytes()` is used when `persist()` is
called due to difference in storage levels.
My example:
```
df = spark.range(1,4500000000).cache()
df.count()
AND
df = spark.range(1,4500000000).persist()
df.count()
```
I tried this on Spark version 2.4.6. I have attached RDD storage screenshots
here. Correct me if I'm missing something and this is expected.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}