wangyum opened a new pull request #22038:
URL: https://github.com/apache/spark/pull/22038
## What changes were proposed in this pull request?
before this PR:
```scala
scala> val df = spark.range(4).toDF().selectExpr("cast(id as decimal(9, 2))
as id")
df: org.apache.spark.sql.DataFrame = [id: decimal(9,2)]
scala> df.filter("id in('1', '3')").show
+---+
| id|
+---+
+---+
scala> df.filter("id = '1' or id ='3'").show
+----+
| id|
+----+
|1.00|
|3.00|
+----+
```
after this PR:
```scala
scala> val df = spark.range(4).toDF().selectExpr("cast(id as decimal(9, 2))
as id")
df: org.apache.spark.sql.DataFrame = [id: decimal(9,2)]
scala> df.filter("id in('1', '3')").show
+----+
| id|
+----+
|1.00|
|3.00|
+----+
scala> df.filter("id = '1' or id ='3'").show
+----+
| id|
+----+
|1.00|
|3.00|
+----+
```
This change is the same as
[HIVE-20204](https://issues.apache.org/jira/browse/HIVE-20204).
Other database behavior:
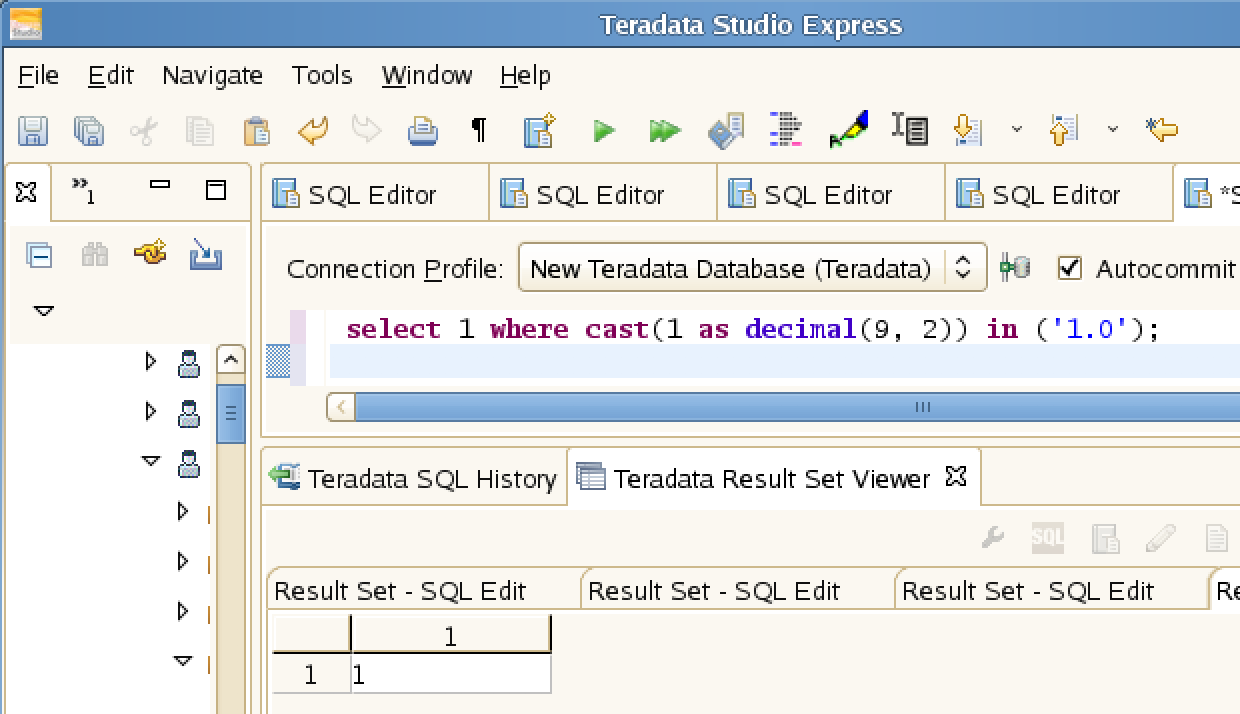
**Teradata**:
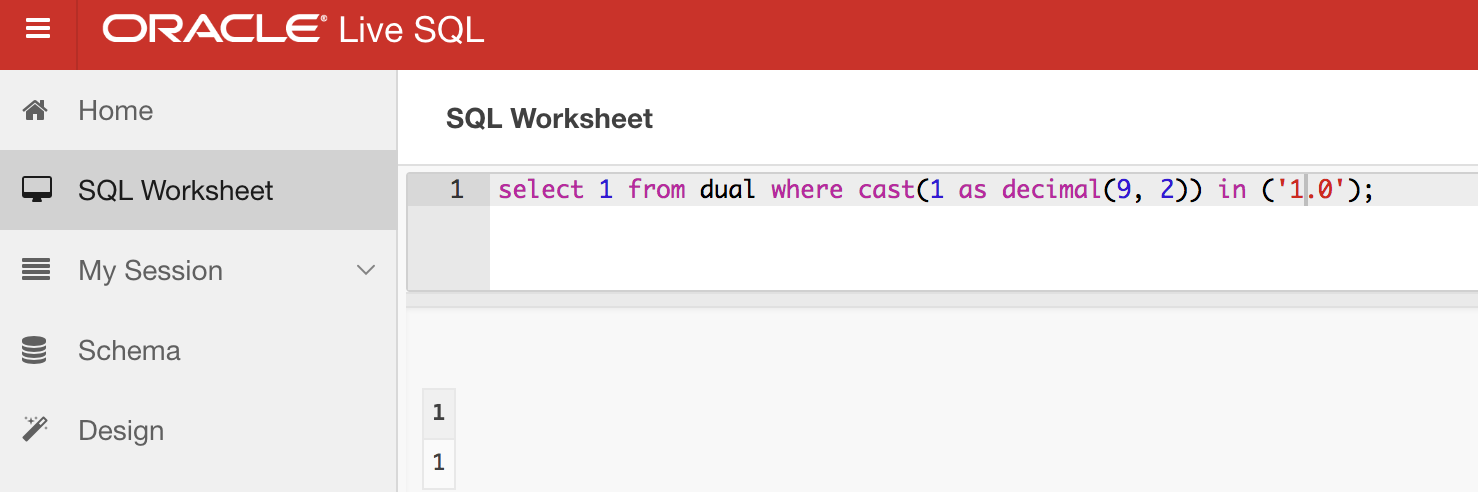
**Oracle**:
**MySQL**:

**postgres**

**Hive-2.3.2**

**Hive** [**current
master**](https://github.com/apache/hive/commit/1c8449cce2a961c6ca6ce38bef0d770f34221d4d)

**spark-sql**:

## How was this patch tested?
unit tests
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}