wangyum commented on a change in pull request #29790:
URL: https://github.com/apache/spark/pull/29790#discussion_r492722255
##########
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
##########
@@ -368,7 +368,7 @@ case class MapEntries(child: Expression)
@transient private lazy val childDataType: MapType =
child.dataType.asInstanceOf[MapType]
- override def dataType: DataType = {
+ private lazy val internalDataType: DataType = {
Review comment:
This is to improve this case:
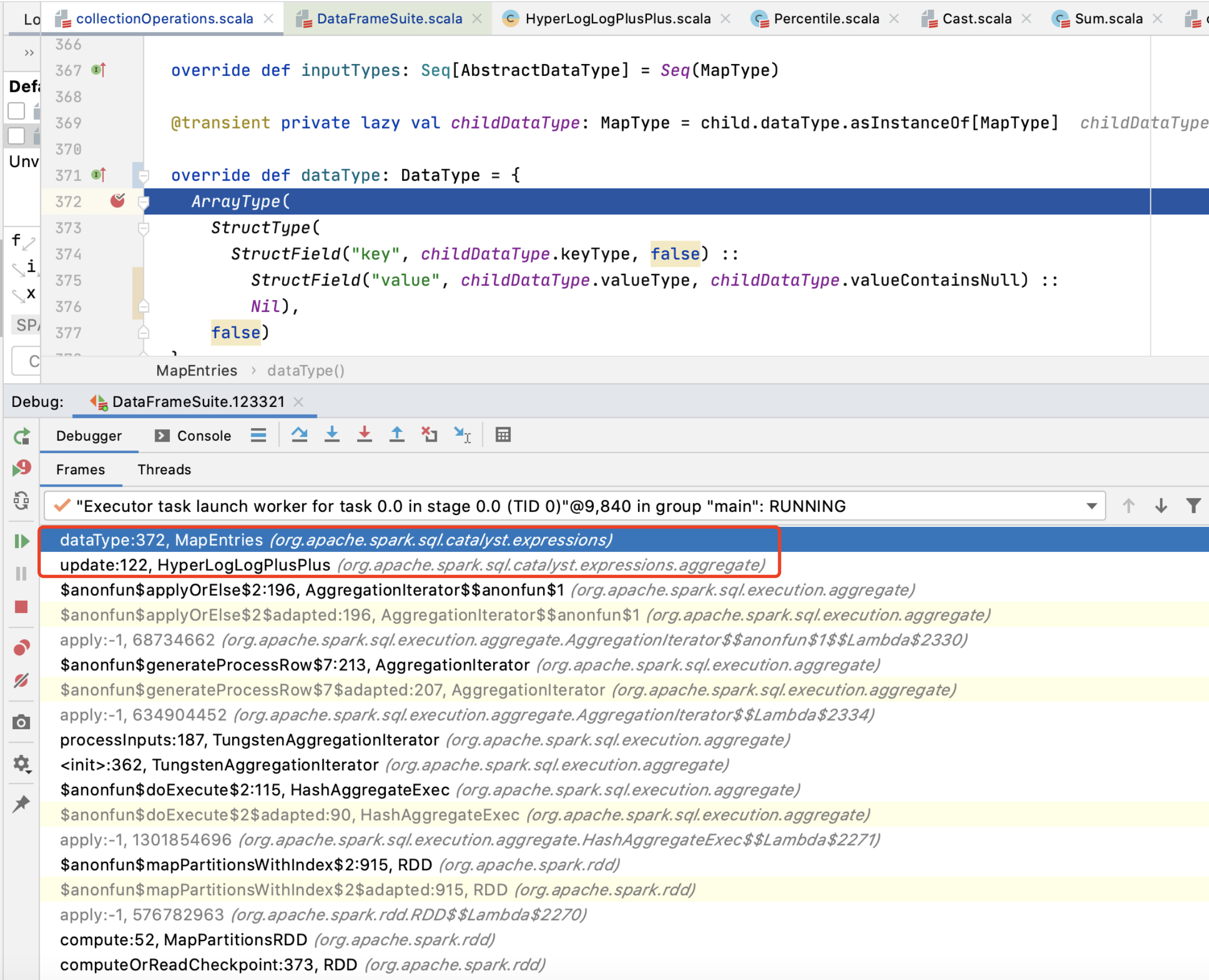
Benchmark code | Before this PR(Seconds) | After this PR(Seconds)
-- | -- | --
spark.range(100000000L).selectExpr("approx_count_distinct(map_entries(map(1,
id)))").collect() | 21787 | 15551
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}