LuciferYang commented on pull request #30663: URL: https://github.com/apache/spark/pull/30663#issuecomment-749378207
@HyukjinKwon @dongjoon-hyun It seems that it is not easy to prove this optimization through UT. I did the following test, taking DataSourceV1 as an example: 1. 10 files and each file has 1100 columns , each file about 400m 2. Execute a simple query without filter `select count(xxx) from orc_table` The key results are as follows: **without this pr** 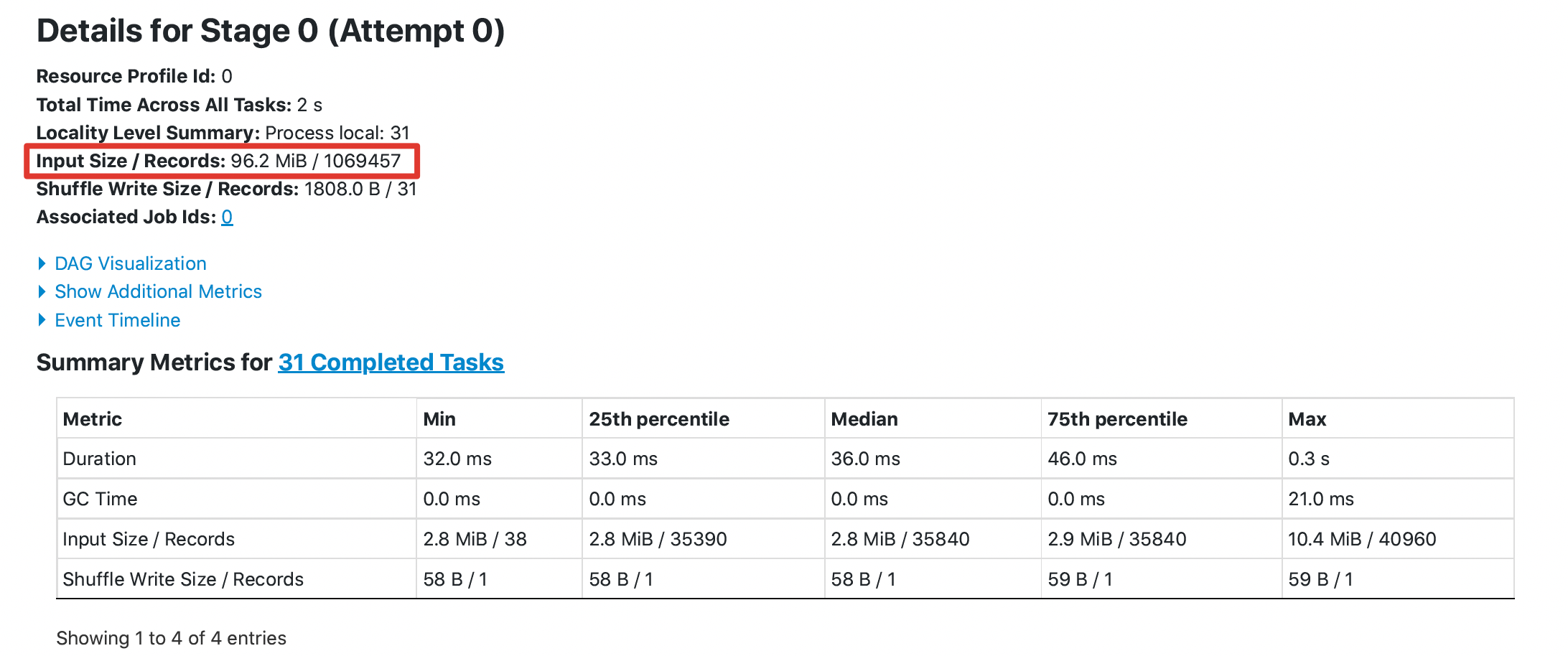 **with this pr** 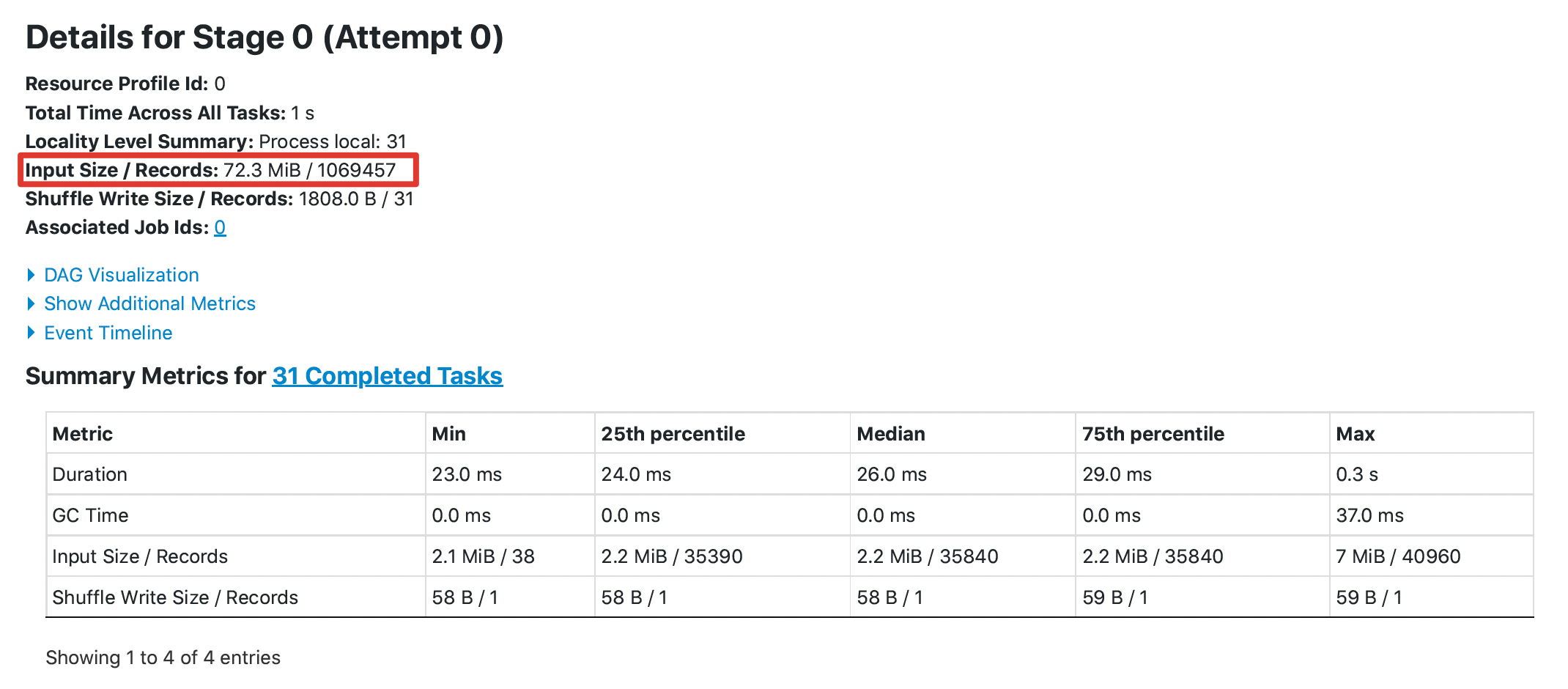 The `Input Size` from `96.2 MiB` to `72.3 MiB`, the `Total Time Across All Tasks` from 2s to 1s ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}